 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight CNN-Based Anomaly Detection for High Voltage Converter Modulators in the Spallation Neutron Source
May 29, 2026Unscheduled trips of high-power pulsed converters are a leading source of downtime at large accelerator facilities. At the Spallation Neutron Source (SNS), the High Voltage Converter Modulators (HVCMs) are consistently the second-largest contributor to lost beam time. Each HVCM pulse is recorded across sensor channels spanning currents, voltages, and magnetic fluxes, whose mutual interactions encode the operating state of the system. Fault precursors do not manifest uniformly across these channels: depending on fault type, they may alter the temporal structure of individual signals, change the statistical dependencies among channels, or both. Existing deep-learning approaches typically process multi-channel signals with standard convolutional pipelines that entangle temporal and cross-channel operations from the first layer, giving the model no explicit mechanism to represent channel independence or structured inter-channel interaction. We hypothesise that architectural inductive bias, specifically the ordering of temporal filtering and cross-channel mixing, plays a central role in detection performance on this class of data. To test this, we vary the order in which these two operations are applied, and examine whether per-pulse adaptive channel reweighting further improves sensitivity. Evaluated on the public HVCM dataset across all four SNS subsystems (RFQ, DTL, CCL, SCL), our best variant achieves a pooled AUC-PR of 0.816 and AUC-ROC of 0.934, outperforming the state of the art on most subsystems and five of the six fault families. Ablations identify three dominant input channels and link per-fault-family performance to whether precursors manifest as amplitude shifts in individual channels or as subtler patterns requiring joint channel representations to surface.
VACE: Learning Geometrically Structured Representations for Time Series Anomaly Detection
May 22, 2026Anomaly detection in multivariate time series is a critical task across a wide range of real-world applications, where abnormal behaviour is rare, labels are unavailable, and the cost of a miss is high. The central challenge is learning a characterisation of normality precise enough to flag deviations. Representation self-supervised learning, typically through contrastive approaches, addresses this by embedding temporal patches into a latent space where normality occupies a well-defined region, with anomalies detected by geometric deviation. However, contrastive approaches shape this space indirectly through pair-sampling heuristics, providing no explicit control over the geometric structure that distance-based scoring requires. This means how tightly normal representations are grouped, and whether distances are directionally meaningful. We present VACE (Velocity-Aligned Channel Embeddings), a self-supervised anomaly detection method that represents normality as a compact, directionally coherent region in the embedding space. To this end, VACE trains a channel-aware encoder through a velocity-consistency objective, with no negatives and no synthetic anomalies, so that normal trajectories are locally smooth and aligned. At test time, a Mahalanobis positional score and a velocity-bank directional score are combined multiplicatively, flagging points that are simultaneously off-distribution and dynamically atypical. Despite its simplicity, VACE achieves state-of-the-art performance on TSB-AD-M under rigorous evaluation, significantly outperforming more complex methods trained on substantially larger budgets.
STOOD-X methodology: using statistical nonparametric test for OOD Detection Large-Scale datasets enhanced with explainability
Apr 03, 2025



Out-of-Distribution (OOD) detection is a critical task in machine learning, particularly in safety-sensitive applications where model failures can have serious consequences. However, current OOD detection methods often suffer from restrictive distributional assumptions, limited scalability, and a lack of interpretability. To address these challenges, we propose STOOD-X, a two-stage methodology that combines a Statistical nonparametric Test for OOD Detection with eXplainability enhancements. In the first stage, STOOD-X uses feature-space distances and a Wilcoxon-Mann-Whitney test to identify OOD samples without assuming a specific feature distribution. In the second stage, it generates user-friendly, concept-based visual explanations that reveal the features driving each decision, aligning with the BLUE XAI paradigm. Through extensive experiments on benchmark datasets and multiple architectures, STOOD-X achieves competitive performance against state-of-the-art post hoc OOD detectors, particularly in high-dimensional and complex settings. In addition, its explainability framework enables human oversight, bias detection, and model debugging, fostering trust and collaboration between humans and AI systems. The STOOD-X methodology therefore offers a robust, explainable, and scalable solution for real-world OOD detection tasks.
Local Attention Mechanism: Boosting the Transformer Architecture for Long-Sequence Time Series Forecasting
Oct 04, 2024



Transformers have become the leading choice in natural language processing over other deep learning architectures. This trend has also permeated the field of time series analysis, especially for long-horizon forecasting, showcasing promising results both in performance and running time. In this paper, we introduce Local Attention Mechanism (LAM), an efficient attention mechanism tailored for time series analysis. This mechanism exploits the continuity properties of time series to reduce the number of attention scores computed. We present an algorithm for implementing LAM in tensor algebra that runs in time and memory O(nlogn), significantly improving upon the O(n^2) time and memory complexity of traditional attention mechanisms. We also note the lack of proper datasets to evaluate long-horizon forecast models. Thus, we propose a novel set of datasets to improve the evaluation of models addressing long-horizon forecasting challenges. Our experimental analysis demonstrates that the vanilla transformer architecture magnified with LAM surpasses state-of-the-art models, including the vanilla attention mechanism. These results confirm the effectiveness of our approach and highlight a range of future challenges in long-sequence time series forecasting.
SHIELD: A regularization technique for eXplainable Artificial Intelligence
Apr 03, 2024



As Artificial Intelligence systems become integral across domains, the demand for explainability grows. While the effort by the scientific community is focused on obtaining a better explanation for the model, it is important not to ignore the potential of this explanation process to improve training as well. While existing efforts primarily focus on generating and evaluating explanations for black-box models, there remains a critical gap in directly enhancing models through these evaluations. This paper introduces SHIELD (Selective Hidden Input Evaluation for Learning Dynamics), a regularization technique for explainable artificial intelligence designed to improve model quality by concealing portions of input data and assessing the resulting discrepancy in predictions. In contrast to conventional approaches, SHIELD regularization seamlessly integrates into the objective function, enhancing model explainability while also improving performance. Experimental validation on benchmark datasets underscores SHIELD's effectiveness in improving Artificial Intelligence model explainability and overall performance. This establishes SHIELD regularization as a promising pathway for developing transparent and reliable Artificial Intelligence regularization techniques.
A Survey on Semi-Supervised Semantic Segmentation
Feb 20, 2023



Semantic segmentation is one of the most challenging tasks in computer vision. However, in many applications, a frequent obstacle is the lack of labeled images, due to the high cost of pixel-level labeling. In this scenario, it makes sense to approach the problem from a semi-supervised point of view, where both labeled and unlabeled images are exploited. In recent years this line of research has gained much interest and many approaches have been published in this direction. Therefore, the main objective of this study is to provide an overview of the current state of the art in semi-supervised semantic segmentation, offering an updated taxonomy of all existing methods to date. This is complemented by an experimentation with a variety of models representing all the categories of the taxonomy on the most widely used becnhmark datasets in the literature, and a final discussion on the results obtained, the challenges and the most promising lines of future research.
TSFEDL: A Python Library for Time Series Spatio-Temporal Feature Extraction and Prediction using Deep Learning
Jun 08, 2022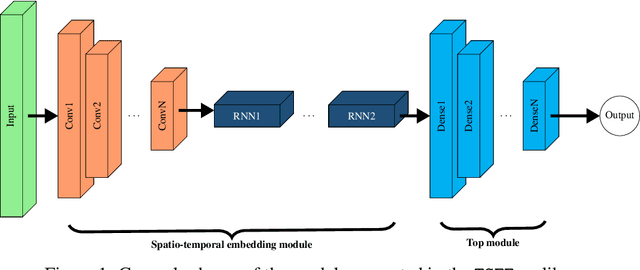
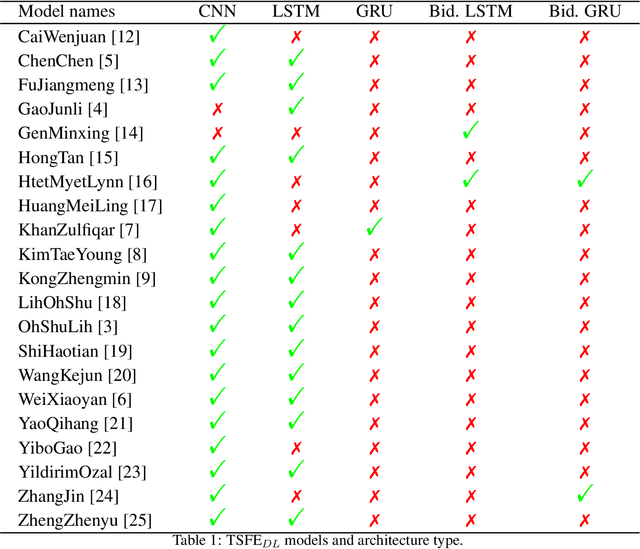
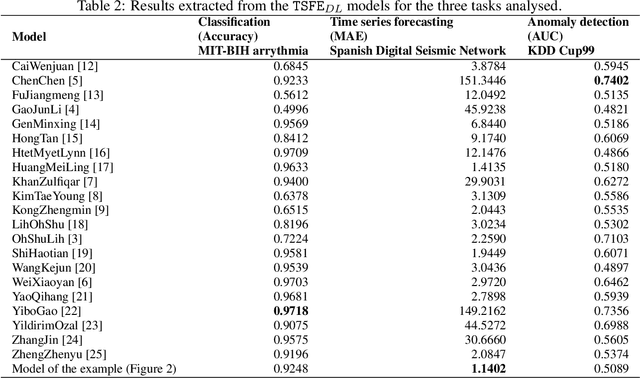
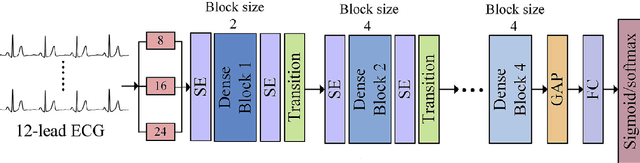
The combination of convolutional and recurrent neural networks is a promising framework that allows the extraction of high-quality spatio-temporal features together with its temporal dependencies, which is key for time series prediction problems such as forecasting, classification or anomaly detection, amongst others. In this paper, the TSFEDL library is introduced. It compiles 20 state-of-the-art methods for both time series feature extraction and prediction, employing convolutional and recurrent deep neural networks for its use in several data mining tasks. The library is built upon a set of Tensorflow+Keras and PyTorch modules under the AGPLv3 license. The performance validation of the architectures included in this proposal confirms the usefulness of this Python package.
A robust approach for deep neural networks in presence of label noise: relabelling and filtering instances during training
Sep 08, 2021
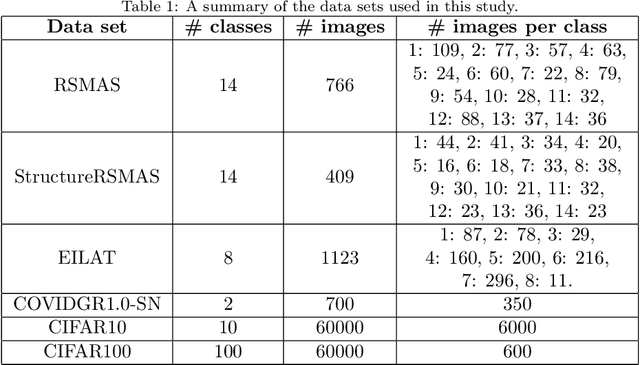
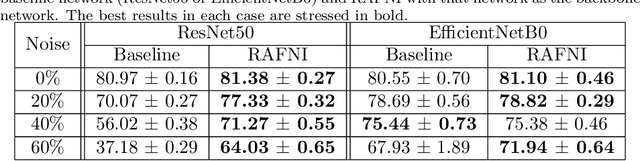

Deep learning has outperformed other machine learning algorithms in a variety of tasks, and as a result, it has become more and more popular and used. However, as other machine learning algorithms, deep learning, and convolutional neural networks (CNNs) in particular, perform worse when the data sets present label noise. Therefore, it is important to develop algorithms that help the training of deep networks and their generalization to noise-free test sets. In this paper, we propose a robust training strategy against label noise, called RAFNI, that can be used with any CNN. This algorithm filters and relabels instances of the training set based on the predictions and their probabilities made by the backbone neural network during the training process. That way, this algorithm improves the generalization ability of the CNN on its own. RAFNI consists of three mechanisms: two mechanisms that filter instances and one mechanism that relabels instances. In addition, it does not suppose that the noise rate is known nor does it need to be estimated. We evaluated our algorithm using different data sets of several sizes and characteristics. We also compared it with state-of-the-art models using the CIFAR10 and CIFAR100 benchmarks under different types and rates of label noise and found that RAFNI achieves better results in most cases.
Anomaly Detection in Predictive Maintenance: A New Evaluation Framework for Temporal Unsupervised Anomaly Detection Algorithms
May 26, 2021
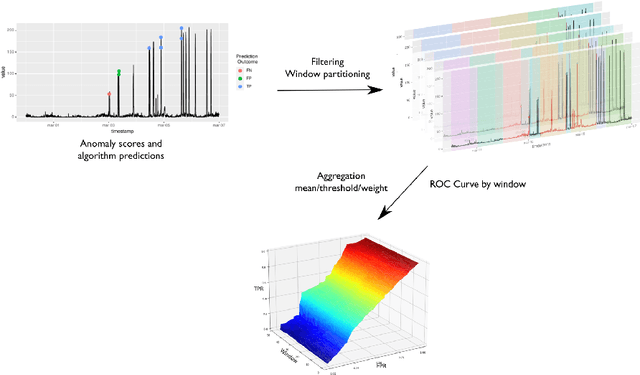

The research in anomaly detection lacks a unified definition of what represents an anomalous instance. Discrepancies in the nature itself of an anomaly lead to multiple paradigms of algorithms design and experimentation. Predictive maintenance is a special case, where the anomaly represents a failure that must be prevented. Related time-series research as outlier and novelty detection or time-series classification does not apply to the concept of an anomaly in this field, because they are not single points which have not been seen previously and may not be precisely annotated. Moreover, due to the lack of annotated anomalous data, many benchmarks are adapted from supervised scenarios. To address these issues, we generalise the concept of positive and negative instances to intervals to be able to evaluate unsupervised anomaly detection algorithms. We also preserve the imbalance scheme for evaluation through the proposal of the Preceding Window ROC, a generalisation for the calculation of ROC curves for time-series scenarios. We also adapt the mechanism from a established time-series anomaly detection benchmark to the proposed generalisations to reward early detection. Therefore, the proposal represents a flexible evaluation framework for the different scenarios. To show the usefulness of this definition, we include a case study of Big Data algorithms with a real-world time-series problem provided by the company ArcelorMittal, and compare the proposal with an evaluation method.
Label Noise Filtering Techniques to Improve Monotonic Classification
Oct 21, 2018



The monotonic ordinal classification has increased the interest of researchers and practitioners within machine learning community in the last years. In real applications, the problems with monotonicity constraints are very frequent. To construct predictive monotone models from those problems, many classifiers require as input a data set satisfying the monotonicity relationships among all samples. Changing the class labels of the data set (relabelling) is useful for this. Relabelling is assumed to be an important building block for the construction of monotone classifiers and it is proved that it can improve the predictive performance. In this paper, we will address the construction of monotone datasets considering as noise the cases that do not meet the monotonicity restrictions. For the first time in the specialized literature, we propose the use of noise filtering algorithms in a preprocessing stage with a double goal: to increase both the monotonicity index of the models and the accuracy of the predictions for different monotonic classifiers. The experiments are performed over 12 datasets coming from classification and regression problems and show that our scheme improves the prediction capabilities of the monotonic classifiers instead of being applied to original and relabeled datasets. In addition, we have included the analysis of noise filtering process in the particular case of wine quality classification to understand its effect in the predictive models generated.