 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Creating a Large Number of New Bilingual Dictionaries
Aug 12, 2022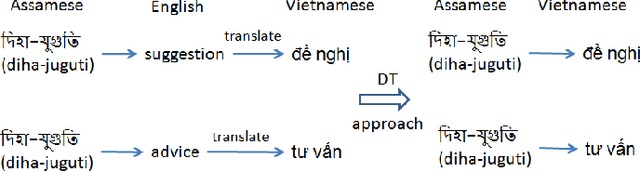
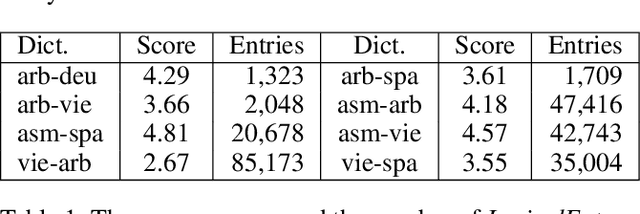
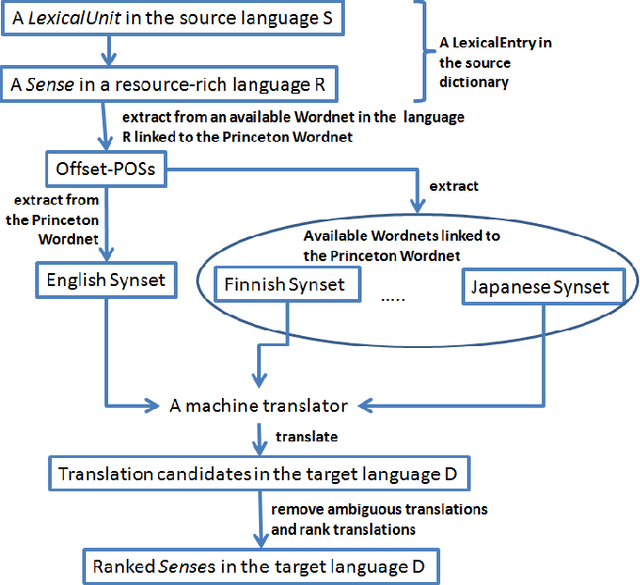
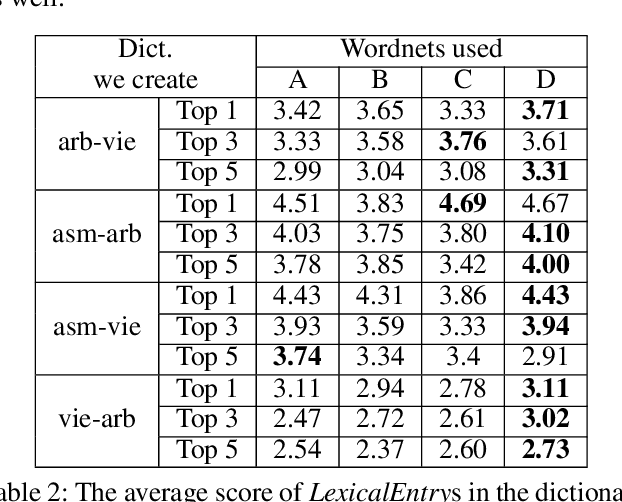
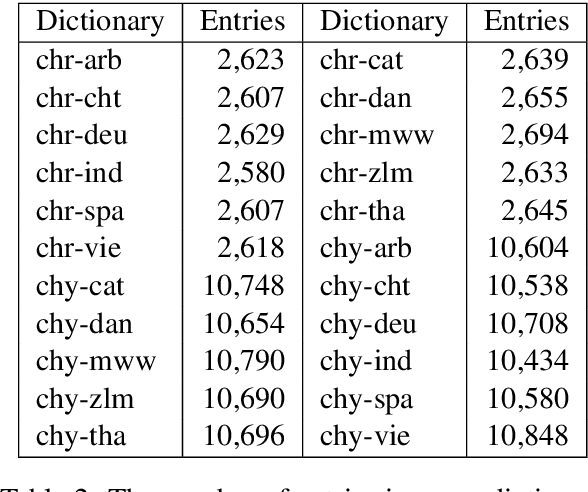
This paper proposes approaches to automatically create a large number of new bilingual dictionaries for low-resource languages, especially resource-poor and endangered languages, from a single input bilingual dictionary. Our algorithms produce translations of words in a source language to plentiful target languages using available Wordnets and a machine translator (MT). Since our approaches rely on just one input dictionary, available Wordnets and an MT, they are applicable to any bilingual dictionary as long as one of the two languages is English or has a Wordnet linked to the Princeton Wordnet. Starting with 5 available bilingual dictionaries, we create 48 new bilingual dictionaries. Of these, 30 pairs of languages are not supported by the popular MTs: Google and Bing.
* 7 pages
Using Artificial Intelligence and IoT for Constructing a Smart Trash Bin
Aug 12, 2022The research reported in this paper transforms a normal trash bin into a smarter one by applying computer vision technology. With the support of sensors and actuator devices, the trash bin can automatically classify garbage. In particular, a camera on the trash bin takes pictures of trash, then the central processing unit analyzes and makes decisions regarding which bin to drop trash into. The accuracy of our trash bin system achieves 90%. Besides, our model is connected to the Internet to update the bin status for further management. A mobile application is developed for managing the bin.
* 8 pages
Building a Chatbot on a Closed Domain using RASA
Aug 12, 2022
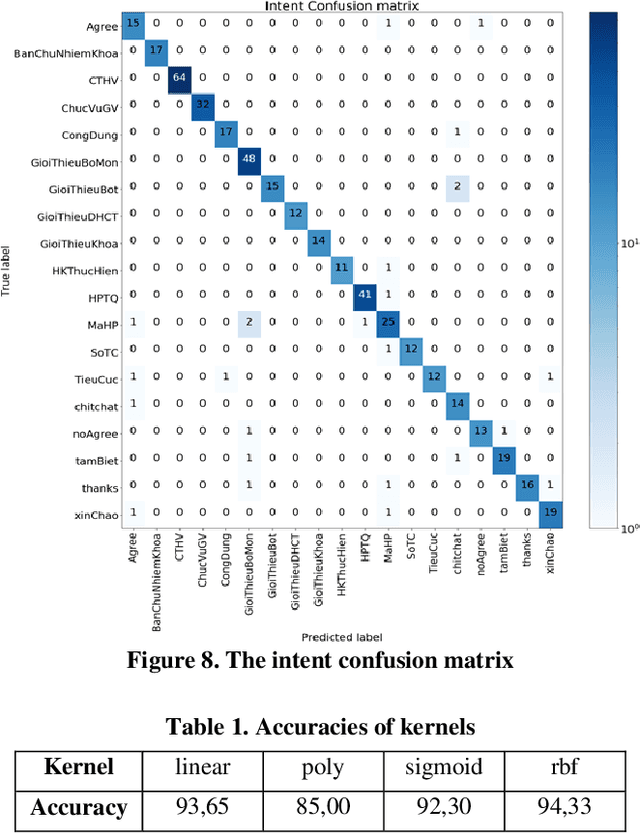

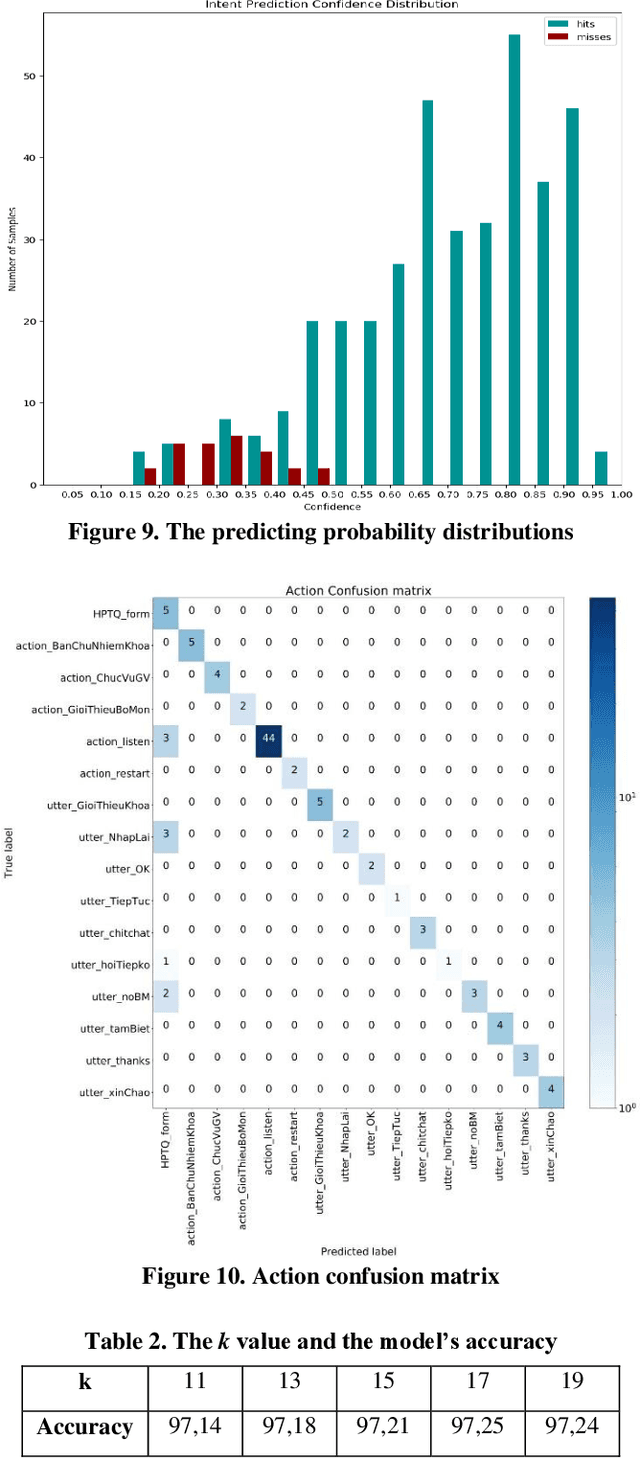
In this study, we build a chatbot system in a closed domain with the RASA framework, using several models such as SVM for classifying intents, CRF for extracting entities and LSTM for predicting action. To improve responses from the bot, the kNN algorithm is used to transform false entities extracted into true entities. The knowledge domain of our chatbot is about the College of Information and Communication Technology of Can Tho University, Vietnam. We manually construct a chatbot corpus with 19 intents, 441 sentence patterns of intents, 253 entities and 133 stories. Experiment results show that the bot responds well to relevant questions.
* 5 pages
Creating Lexical Resources for Endangered Languages
Aug 08, 2022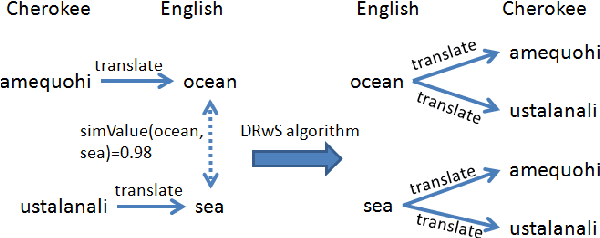
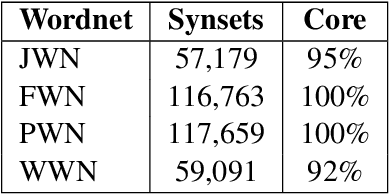
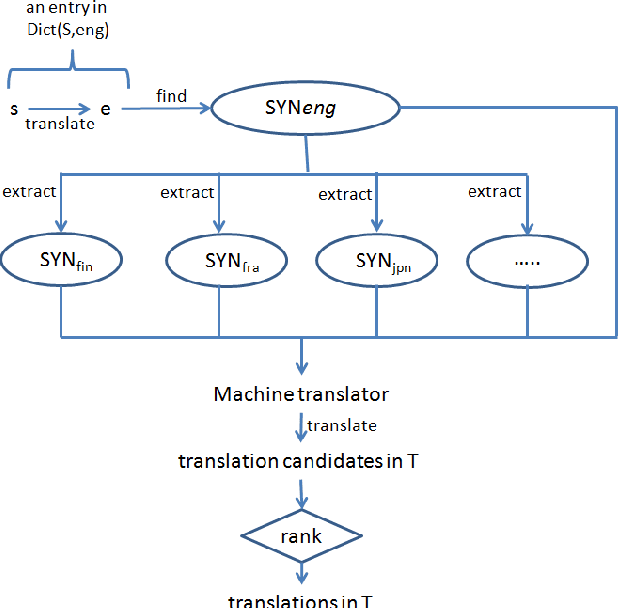
This paper examines approaches to generate lexical resources for endangered languages. Our algorithms construct bilingual dictionaries and multilingual thesauruses using public Wordnets and a machine translator (MT). Since our work relies on only one bilingual dictionary between an endangered language and an "intermediate helper" language, it is applicable to languages that lack many existing resources.
* 9 pages
Automatically constructing Wordnet synsets
Aug 08, 2022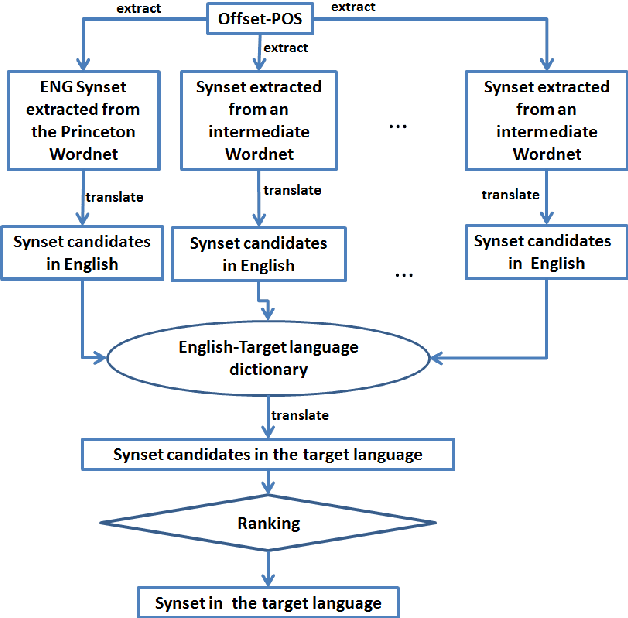
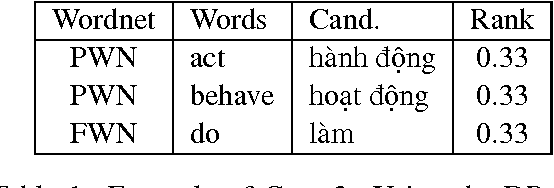
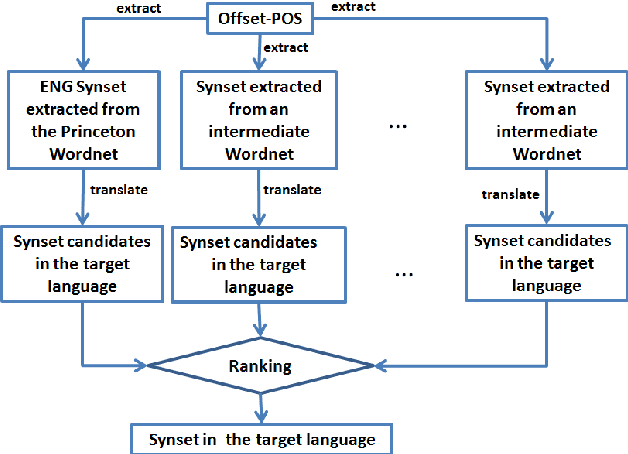
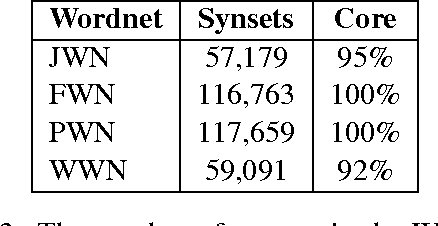
Manually constructing a Wordnet is a difficult task, needing years of experts' time. As a first step to automatically construct full Wordnets, we propose approaches to generate Wordnet synsets for languages both resource-rich and resource-poor, using publicly available Wordnets, a machine translator and/or a single bilingual dictionary. Our algorithms translate synsets of existing Wordnets to a target language T, then apply a ranking method on the translation candidates to find best translations in T. Our approaches are applicable to any language which has at least one existing bilingual dictionary translating from English to it.
* 6 pages
Creating Reverse Bilingual Dictionaries
Aug 08, 2022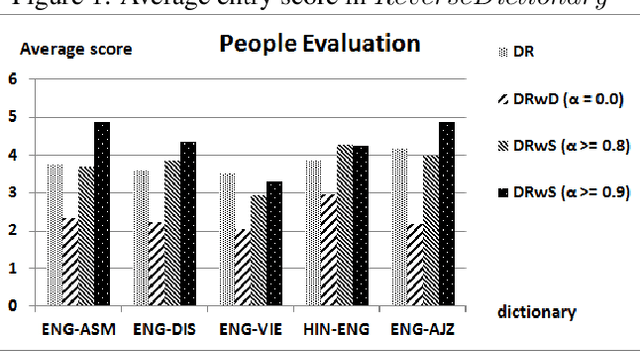
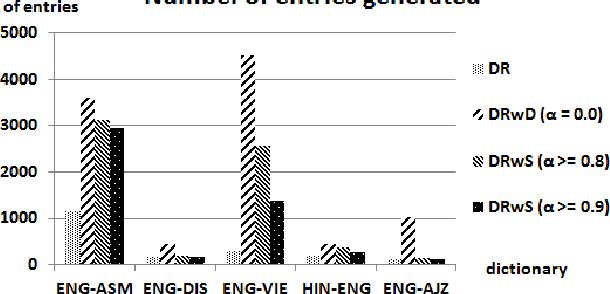
Bilingual dictionaries are expensive resources and not many are available when one of the languages is resource-poor. In this paper, we propose algorithms for creation of new reverse bilingual dictionaries from existing bilingual dictionaries in which English is one of the two languages. Our algorithms exploit the similarity between word-concept pairs using the English Wordnet to produce reverse dictionary entries. Since our algorithms rely on available bilingual dictionaries, they are applicable to any bilingual dictionary as long as one of the two languages has Wordnet type lexical ontology.
* 5 pages
Phrase translation using a bilingual dictionary and n-gram data: A case study from Vietnamese to English
Aug 05, 2022
Past approaches to translate a phrase in a language L1 to a language L2 using a dictionary-based approach require grammar rules to restructure initial translations. This paper introduces a novel method without using any grammar rules to translate a given phrase in L1, which does not exist in the dictionary, to L2. We require at least one L1-L2 bilingual dictionary and n-gram data in L2. The average manual evaluation score of our translations is 4.29/5.00, which implies very high quality.
* 5 pages
Towards Multimodal Vision-Language Models Generating Non-Generic Text
Jul 09, 2022
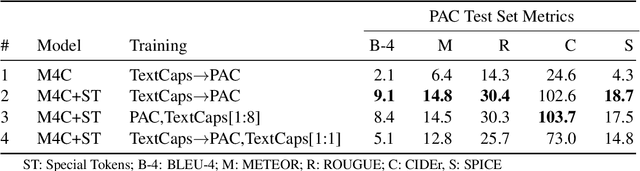
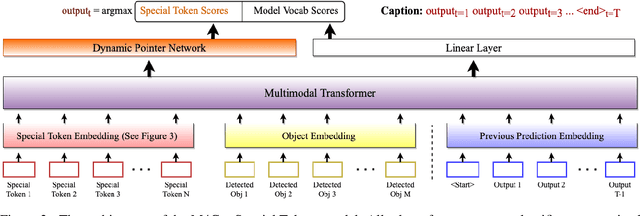

Vision-language models can assess visual context in an image and generate descriptive text. While the generated text may be accurate and syntactically correct, it is often overly general. To address this, recent work has used optical character recognition to supplement visual information with text extracted from an image. In this work, we contend that vision-language models can benefit from additional information that can be extracted from an image, but are not used by current models. We modify previous multimodal frameworks to accept relevant information from any number of auxiliary classifiers. In particular, we focus on person names as an additional set of tokens and create a novel image-caption dataset to facilitate captioning with person names. The dataset, Politicians and Athletes in Captions (PAC), consists of captioned images of well-known people in context. By fine-tuning pretrained models with this dataset, we demonstrate a model that can naturally integrate facial recognition tokens into generated text by training on limited data. For the PAC dataset, we provide a discussion on collection and baseline benchmark scores.
ZoDIAC: Zoneout Dropout Injection Attention Calculation
Jun 28, 2022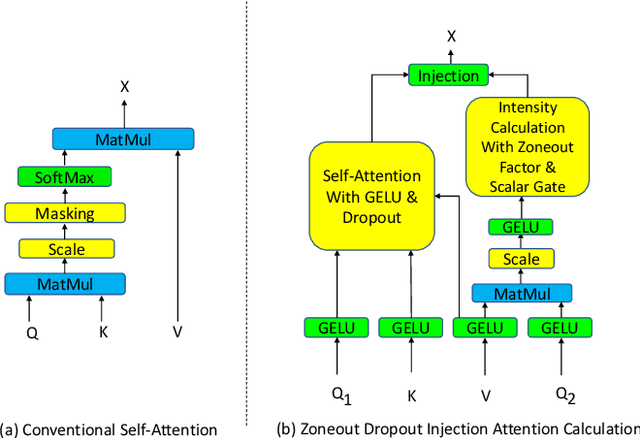
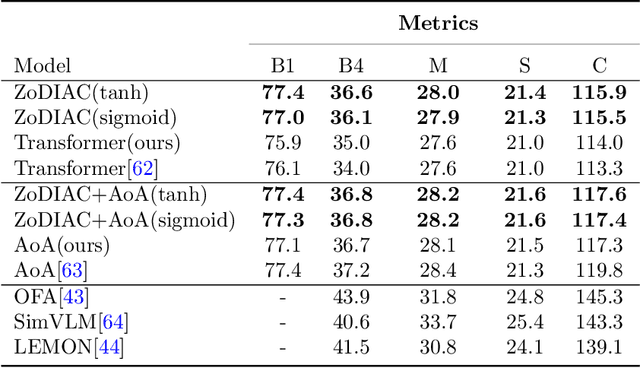
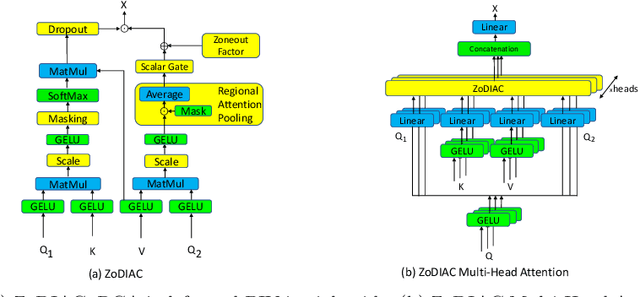
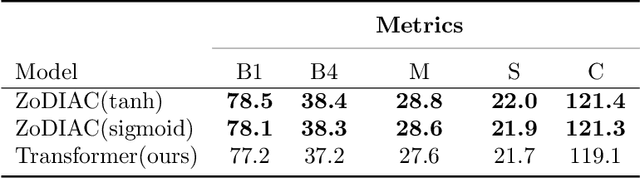
Recently the use of self-attention has yielded to state-of-the-art results in vision-language tasks such as image captioning as well as natural language understanding and generation (NLU and NLG) tasks and computer vision tasks such as image classification. This is since self-attention maps the internal interactions among the elements of input source and target sequences. Although self-attention successfully calculates the attention values and maps the relationships among the elements of input source and target sequence, yet there is no mechanism to control the intensity of attention. In real world, when communicating with each other face to face or vocally, we tend to express different visual and linguistic context with various amounts of intensity. Some words might carry (be spoken with) more stress and weight indicating the importance of that word in the context of the whole sentence. Based on this intuition, we propose Zoneout Dropout Injection Attention Calculation (ZoDIAC) in which the intensities of attention values in the elements of the input sequence are calculated with respect to the context of the elements of input sequence. The results of our experiments reveal that employing ZoDIAC leads to better performance in comparison with the self-attention module in the Transformer model. The ultimate goal is to find out if we could modify self-attention module in the Transformer model with a method that is potentially extensible to other models that leverage on self-attention at their core. Our findings suggest that this particular goal deserves further attention and investigation by the research community. The code for ZoDIAC is available on www.github.com/zanyarz/zodiac .
Using Random Perturbations to Mitigate Adversarial Attacks on Sentiment Analysis Models
Feb 11, 2022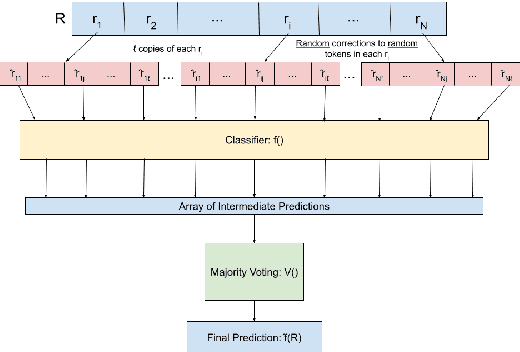
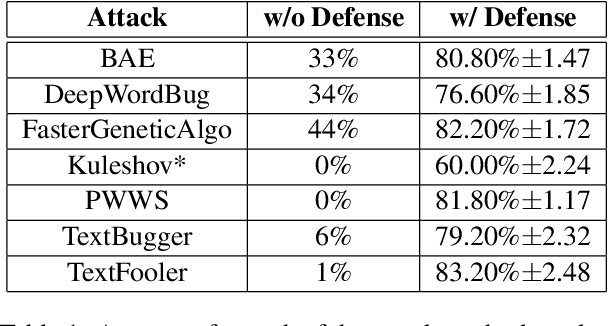
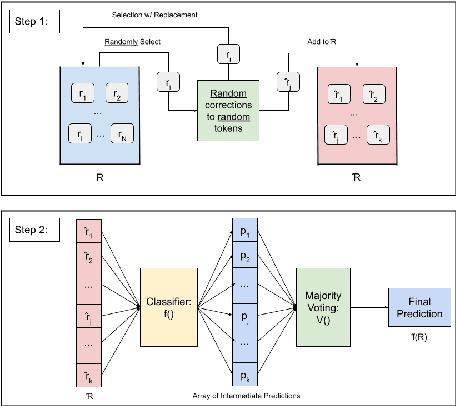
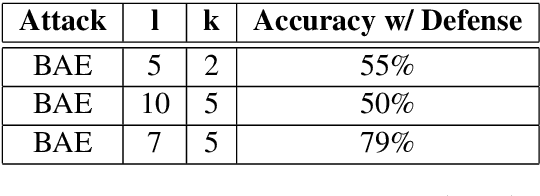
Attacks on deep learning models are often difficult to identify and therefore are difficult to protect against. This problem is exacerbated by the use of public datasets that typically are not manually inspected before use. In this paper, we offer a solution to this vulnerability by using, during testing, random perturbations such as spelling correction if necessary, substitution by random synonym, or simply dropping the word. These perturbations are applied to random words in random sentences to defend NLP models against adversarial attacks. Our Random Perturbations Defense and Increased Randomness Defense methods are successful in returning attacked models to similar accuracy of models before attacks. The original accuracy of the model used in this work is 80% for sentiment classification. After undergoing attacks, the accuracy drops to accuracy between 0% and 44%. After applying our defense methods, the accuracy of the model is returned to the original accuracy within statistical significance.