 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multilingual Study of Multi-Sentence Compression using Word Vertex-Labeled Graphs and Integer Linear Programming
Apr 09, 2020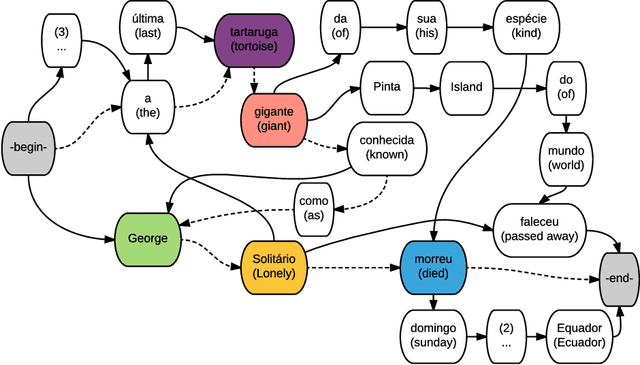
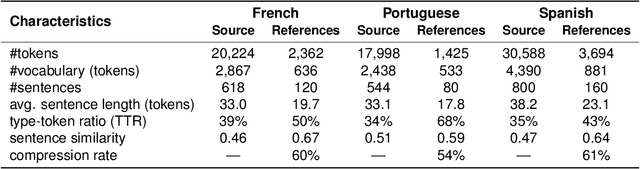
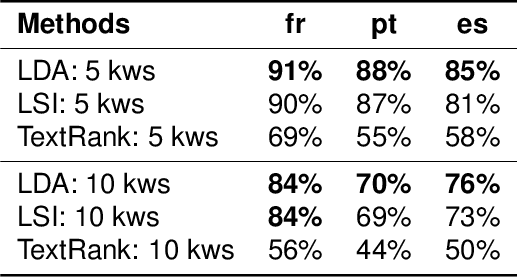
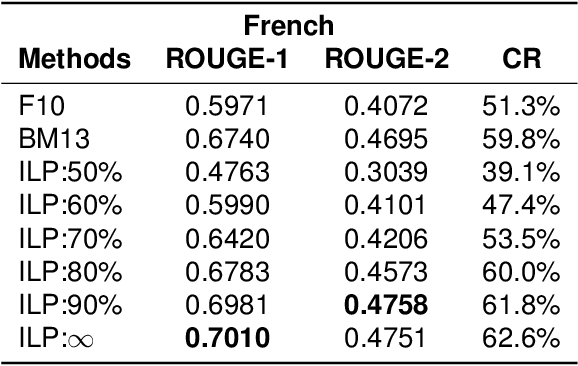
Multi-Sentence Compression (MSC) aims to generate a short sentence with the key information from a cluster of similar sentences. MSC enables summarization and question-answering systems to generate outputs combining fully formed sentences from one or several documents. This paper describes an Integer Linear Programming method for MSC using a vertex-labeled graph to select different keywords, with the goal of generating more informative sentences while maintaining their grammaticality. Our system is of good quality and outperforms the state of the art for evaluations led on news datasets in three languages: French, Portuguese and Spanish. We led both automatic and manual evaluations to determine the informativeness and the grammaticality of compressions for each dataset. In additional tests, which take advantage of the fact that the length of compressions can be modulated, we still improve ROUGE scores with shorter output sentences.
* Preprint version
Automatic Discourse Segmentation: an evaluation in French
Feb 10, 2020

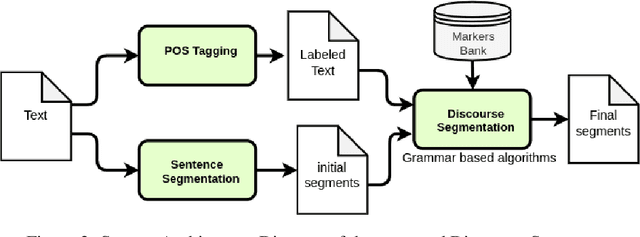
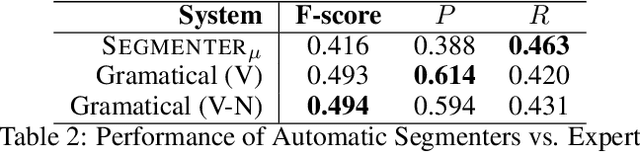
In this article, we describe some discursive segmentation methods as well as a preliminary evaluation of the segmentation quality. Although our experiment were carried for documents in French, we have developed three discursive segmentation models solely based on resources simultaneously available in several languages: marker lists and a statistic POS labeling. We have also carried out automatic evaluations of these systems against the Annodis corpus, which is a manually annotated reference. The results obtained are very encouraging.
Generación automática de frases literarias en español
Jan 17, 2020
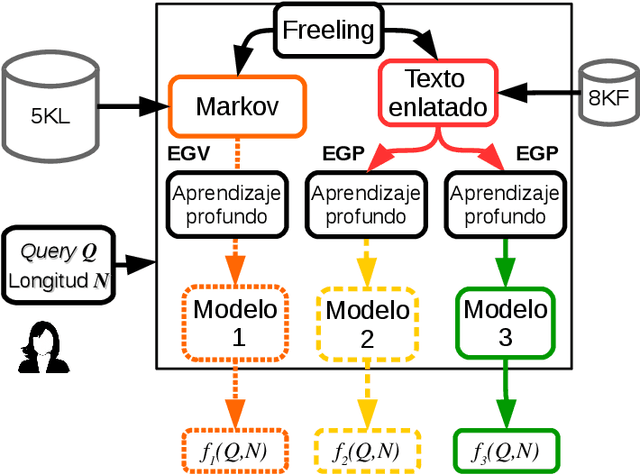

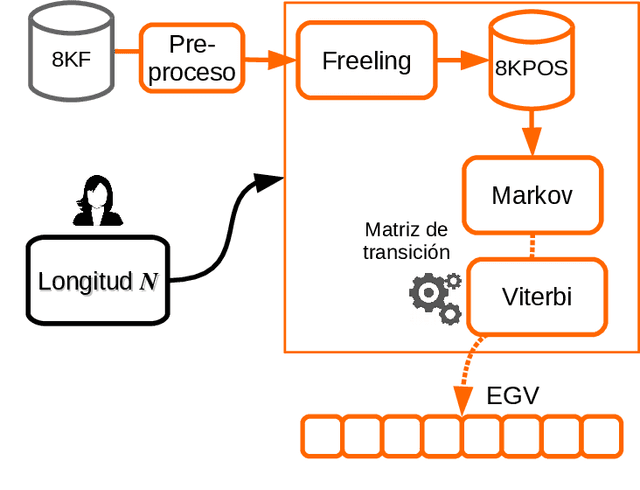
In this work we present a state of the art in the area of Computational Creativity (CC). In particular, we address the automatic generation of literary sentences in Spanish. We propose three models of text generation based mainly on statistical algorithms and shallow parsing analysis. We also present some rather encouraging preliminary results.
Visual Simplified Characters' Emotion Emulator Implementing OCC Model
Jan 17, 2020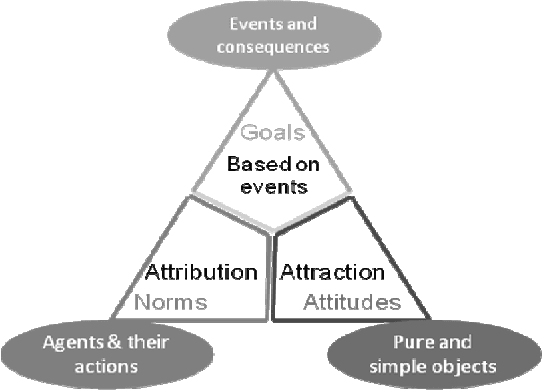


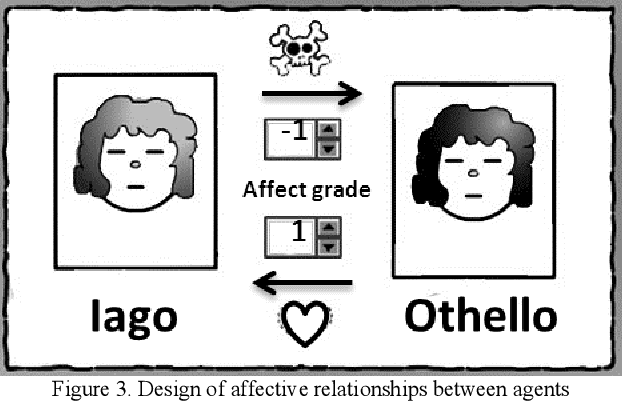
In this paper, we present a visual emulator of the emotions seen in characters in stories. This system is based on a simplified view of the cognitive structure of emotions proposed by Ortony, Clore and Collins (OCC Model). The goal of this paper is to provide a visual platform that allows us to observe changes in the characters' different emotions, and the intricate interrelationships between: 1) each character's emotions, 2) their affective relationships and actions, 3) The events that take place in the development of a plot, and 4) the objects of desire that make up the emotional map of any story. This tool was tested on stories with a contrasting variety of emotional and affective environments: Othello, Twilight, and Harry Potter, behaving sensibly and in keeping with the atmosphere in which the characters were immersed.
* 7 pages, 14 figures, 2 tables
Intweetive Text Summarization
Jan 16, 2020


The amount of user generated contents from various social medias allows analyst to handle a wide view of conversations on several topics related to their business. Nevertheless keeping up-to-date with this amount of information is not humanly feasible. Automatic Summarization then provides an interesting mean to digest the dynamics and the mass volume of contents. In this paper, we address the issue of tweets summarization which remains scarcely explored. We propose to automatically generated summaries of Micro-Blogs conversations dealing with public figures E-Reputation. These summaries are generated using key-word queries or sample tweet and offer a focused view of the whole Micro-Blog network. Since state-of-the-art is lacking on this point we conduct and evaluate our experiments over the multilingual CLEF RepLab Topic-Detection dataset according to an experimental evaluation process.
* 8 pages, 4 tables
Detecting New Word Meanings: A Comparison of Word Embedding Models in Spanish
Jan 12, 2020
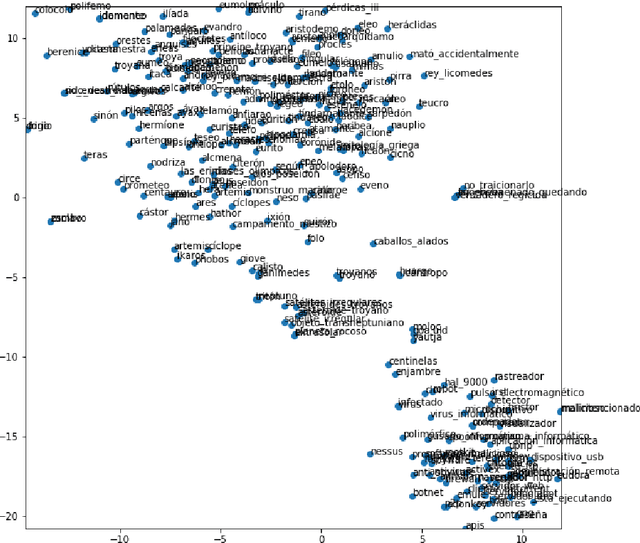
Semantic neologisms (SN) are defined as words that acquire a new word meaning while maintaining their form. Given the nature of this kind of neologisms, the task of identifying these new word meanings is currently performed manually by specialists at observatories of neology. To detect SN in a semi-automatic way, we developed a system that implements a combination of the following strategies: topic modeling, keyword extraction, and word sense disambiguation. The role of topic modeling is to detect the themes that are treated in the input text. Themes within a text give clues about the particular meaning of the words that are used, for example: viral has one meaning in the context of computer science (CS) and another when talking about health. To extract keywords, we used TextRank with POS tag filtering. With this method, we can obtain relevant words that are already part of the Spanish lexicon. We use a deep learning model to determine if a given keyword could have a new meaning. Embeddings that are different from all the known meanings (or topics) indicate that a word might be a valid SN candidate. In this study, we examine the following word embedding models: Word2Vec, Sense2Vec, and FastText. The models were trained with equivalent parameters using Wikipedia in Spanish as corpora. Then we used a list of words and their concordances (obtained from our database of neologisms) to show the different embeddings that each model yields. Finally, we present a comparison of these outcomes with the concordances of each word to show how we can determine if a word could be a valid candidate for SN.
* 16 pages, 3 figures
Predicting Personalized Academic and Career Roads: First Steps Toward a Multi-Uses Recommender System
Jan 03, 2020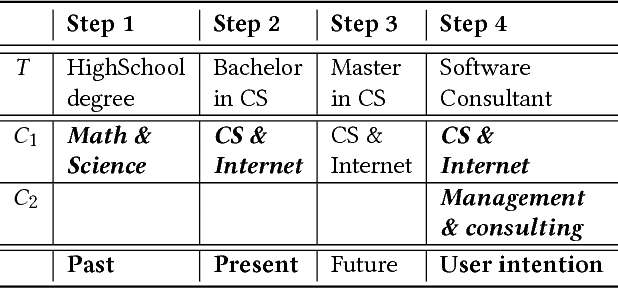
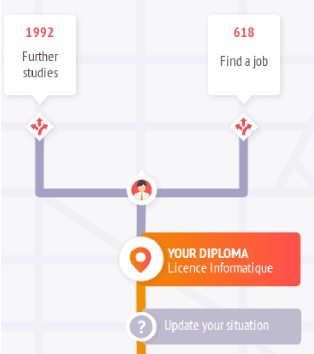

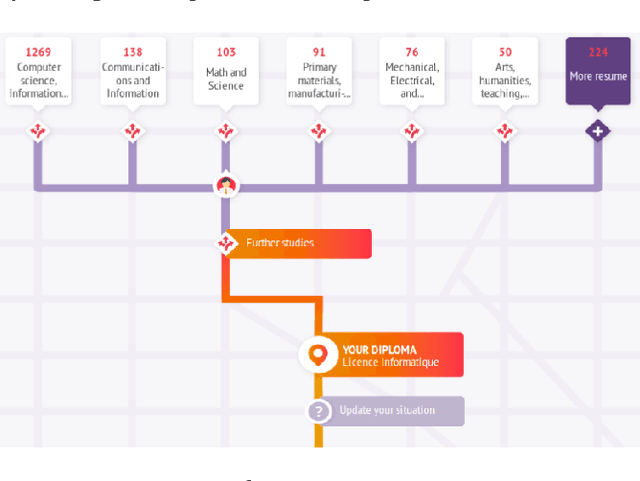
Nobody knows what one's do in the future and everyone will have had a different answer to the question : how do you see yourself in five years after your current job/diploma? In this paper we introduce concepts, large categories of fields of studies or job domains in order to represent the vision of the future of the user's trajectory. Then, we show how they can influence the prediction when proposing him a set of next steps to take.
* 4 pages, 3 figures, 4 tables
RIMAX: Ranking Semantic Rhymes by calculating Definition Similarity
Dec 25, 2019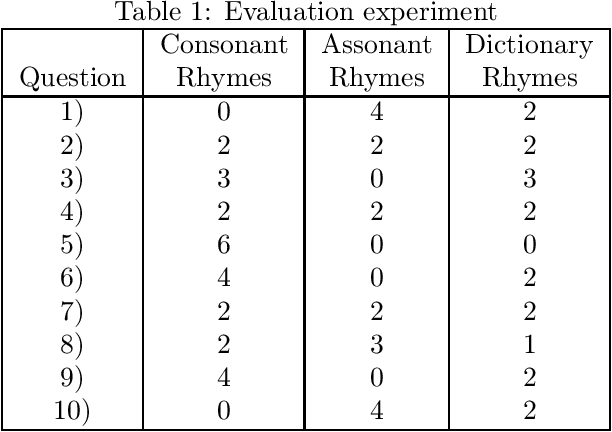
This paper presents RIMAX, a new system for detecting semantic rhymes, using a Comprehensive Mexican Spanish Dictionary (DEM) and its Rhyming Dictionary (REM). We use the Vector Space Model to calculate the similarity of the definition of a query with the definitions corresponding to the assonant and consonant rhymes of the query. The preliminary results using a manual evaluation are very encouraging.
Un duel probabiliste pour départager deux présidents (LIA @ DEFT'2005)
Mar 11, 2019
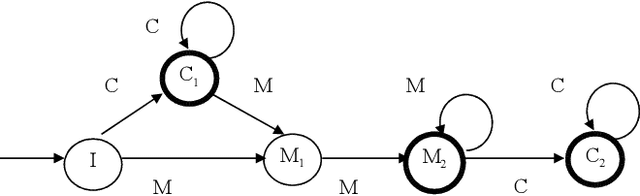
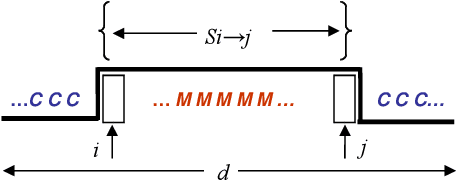
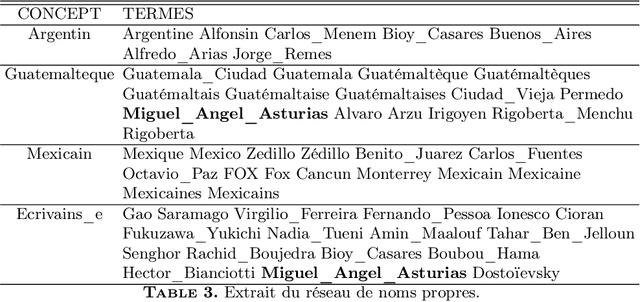
We present a set of probabilistic models applied to binary classification as defined in the DEFT'05 challenge. The challenge consisted a mixture of two differents problems in Natural Language Processing : identification of author (a sequence of Fran\c{c}ois Mitterrand's sentences might have been inserted into a speech of Jacques Chirac) and thematic break detection (the subjects addressed by the two authors are supposed to be different). Markov chains, Bayes models and an adaptative process have been used to identify the paternity of these sequences. A probabilistic model of the internal coherence of speeches which has been employed to identify thematic breaks. Adding this model has shown to improve the quality results. A comparison with different approaches demostrates the superiority of a strategy that combines learning, coherence and adaptation. Applied to the DEFT'05 data test the results in terms of precision (0.890), recall (0.955) and Fscore (0.925) measure are very promising.
* 27 figures, 1 table (in French)
Predicting the Semantic Textual Similarity with Siamese CNN and LSTM
Oct 24, 2018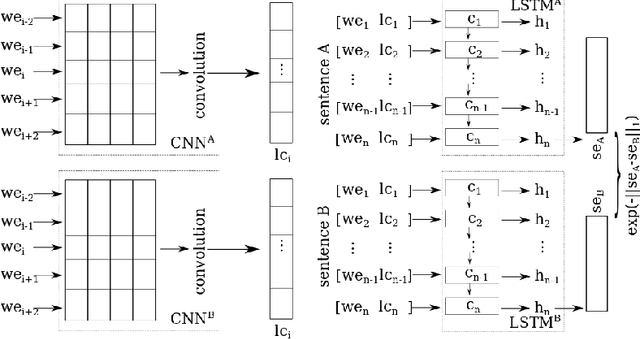
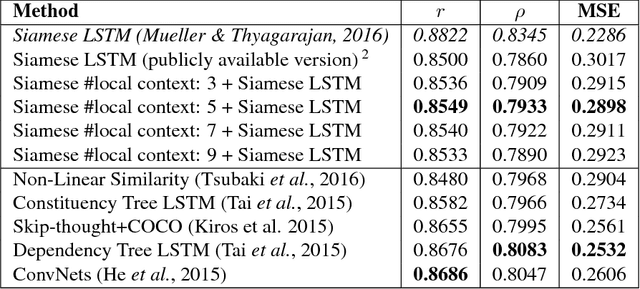
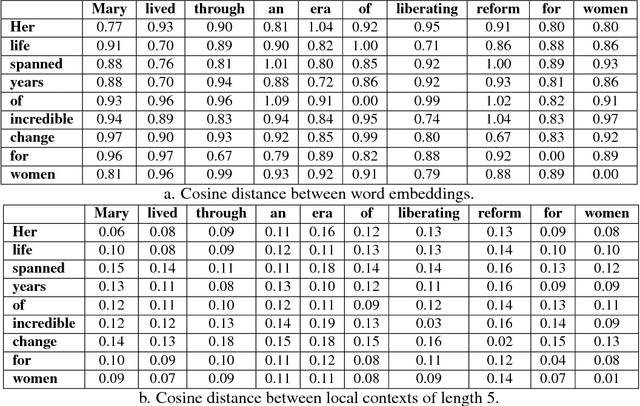
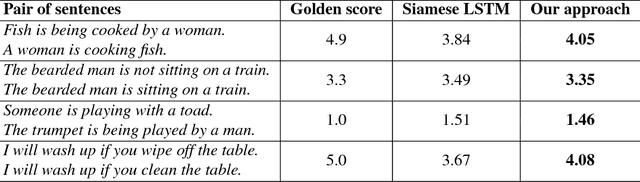
Semantic Textual Similarity (STS) is the basis of many applications in Natural Language Processing (NLP). Our system combines convolution and recurrent neural networks to measure the semantic similarity of sentences. It uses a convolution network to take account of the local context of words and an LSTM to consider the global context of sentences. This combination of networks helps to preserve the relevant information of sentences and improves the calculation of the similarity between sentences. Our model has achieved good results and is competitive with the best state-of-the-art systems.