 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSorting Out the Bad Seeds: Automatic Classification of Cryptocurrency Abuse Reports
Oct 28, 2024Abuse reporting services collect reports about abuse victims have suffered. Accurate classification of the submitted reports is fundamental to analyzing the prevalence and financial impact of different abuse types (e.g., sextortion, investment, romance). Current classification approaches are problematic because they require the reporter to select the abuse type from a list, assuming the reporter has the necessary experience for the classification, which we show is frequently not the case, or require manual classification by analysts, which does not scale. To address these issues, this paper presents a novel approach to classify cryptocurrency abuse reports automatically. We first build a taxonomy of 19 frequently reported abuse types. Given as input the textual description written by the reporter, our classifier leverages a large language model (LLM) to interpret the text and assign it an abuse type in our taxonomy. We collect 290K cryptocurrency abuse reports from two popular reporting services: BitcoinAbuse and BBB's ScamTracker. We build ground truth datasets for 20K of those reports and use them to evaluate three designs for our LLM-based classifier and four LLMs, as well as a supervised ML classifier used as a baseline. Our LLM-based classifier achieves a precision of 0.92, a recall of 0.87, and an F1 score of 0.89, compared to an F1 score of 0.55 for the baseline. We demonstrate our classifier in two applications: providing financial loss statistics for fine-grained abuse types and generating tagged addresses for cryptocurrency analysis platforms.
Decoding the Secrets of Machine Learning in Malware Classification: A Deep Dive into Datasets, Feature Extraction, and Model Performance
Jul 27, 2023



Many studies have proposed machine-learning (ML) models for malware detection and classification, reporting an almost-perfect performance. However, they assemble ground-truth in different ways, use diverse static- and dynamic-analysis techniques for feature extraction, and even differ on what they consider a malware family. As a consequence, our community still lacks an understanding of malware classification results: whether they are tied to the nature and distribution of the collected dataset, to what extent the number of families and samples in the training dataset influence performance, and how well static and dynamic features complement each other. This work sheds light on those open questions. by investigating the key factors influencing ML-based malware detection and classification. For this, we collect the largest balanced malware dataset so far with 67K samples from 670 families (100 samples each), and train state-of-the-art models for malware detection and family classification using our dataset. Our results reveal that static features perform better than dynamic features, and that combining both only provides marginal improvement over static features. We discover no correlation between packing and classification accuracy, and that missing behaviors in dynamically-extracted features highly penalize their performance. We also demonstrate how a larger number of families to classify make the classification harder, while a higher number of samples per family increases accuracy. Finally, we find that models trained on a uniform distribution of samples per family better generalize on unseen data.
Malware Traffic Classification: Evaluation of Algorithms and an Automated Ground-truth Generation Pipeline
Nov 07, 2020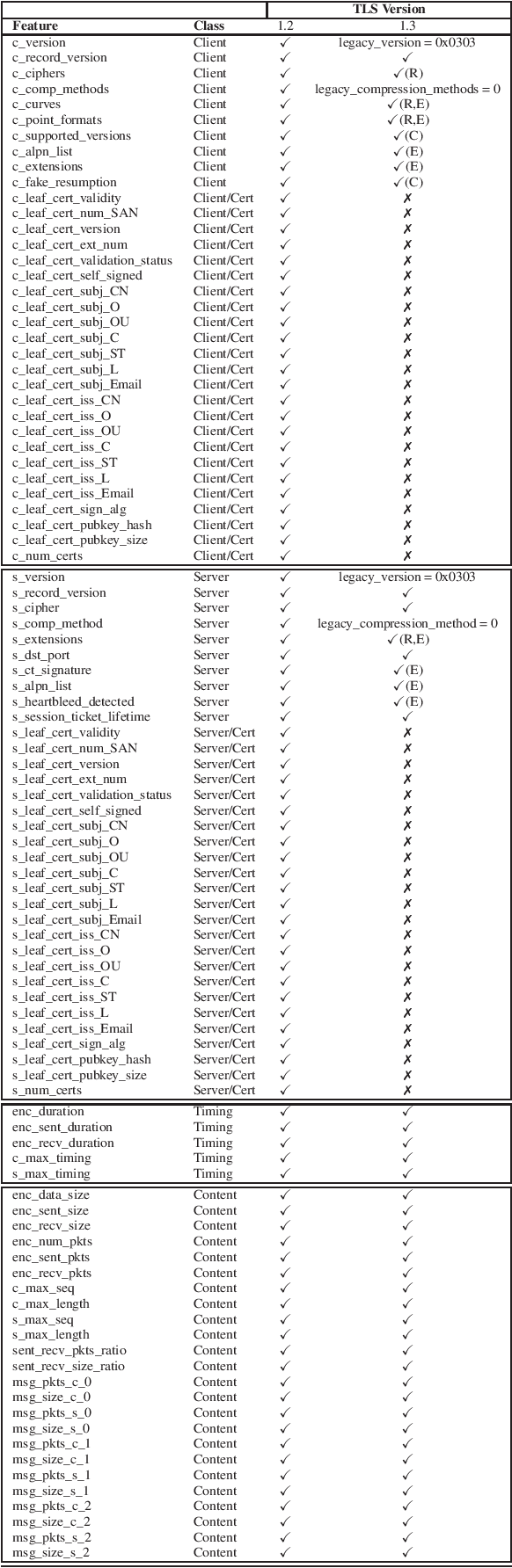

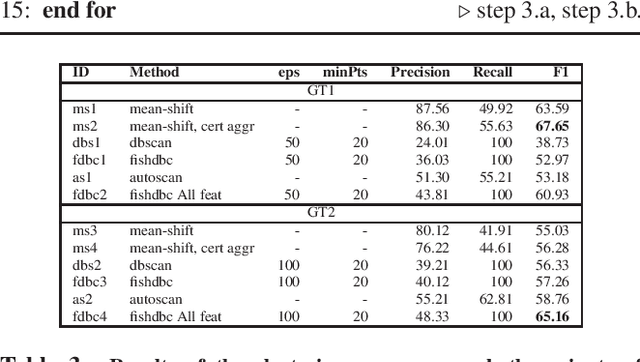
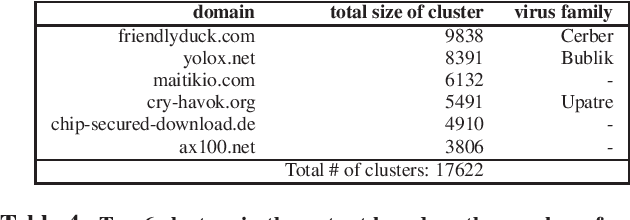
Identifying threats in a network traffic flow which is encrypted is uniquely challenging. On one hand it is extremely difficult to simply decrypt the traffic due to modern encryption algorithms. On the other hand, passing such an encrypted stream through pattern matching algorithms is useless because encryption ensures there aren't any. Moreover, evaluating such models is also difficult due to lack of labeled benign and malware datasets. Other approaches have tried to tackle this problem by employing observable meta-data gathered from the flow. We try to augment this approach by extending it to a semi-supervised malware classification pipeline using these observable meta-data. To this end, we explore and test different kind of clustering approaches which make use of unique and diverse set of features extracted from this observable meta-data. We also, propose an automated packet data-labeling pipeline to generate ground-truth data which can serve as a base-line to evaluate the classifiers mentioned above in particular, or any other detection model in general.