 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Analysis of Zipf's Law, Power Law, and Lognormal Distributions in Medical Discharge Reports
Mar 30, 2020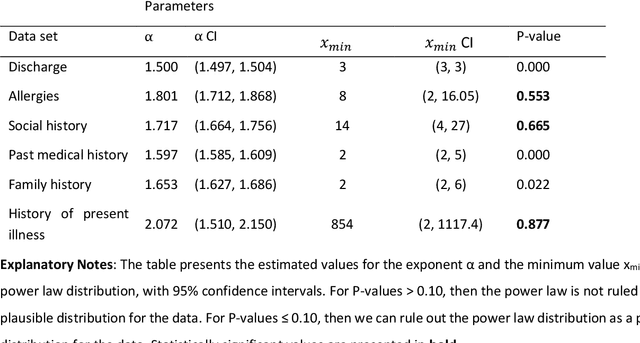
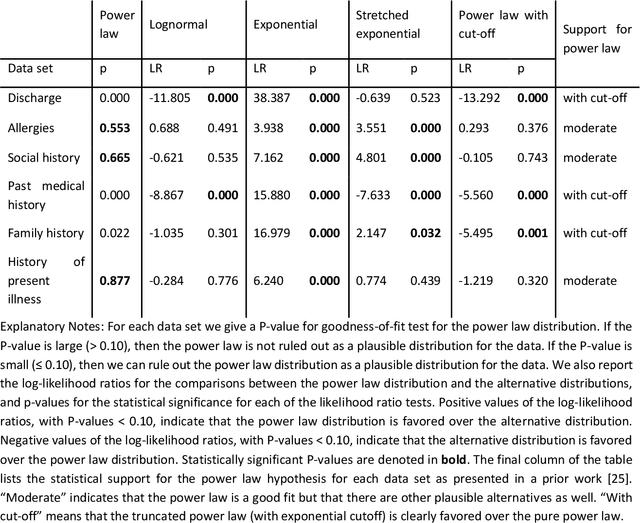
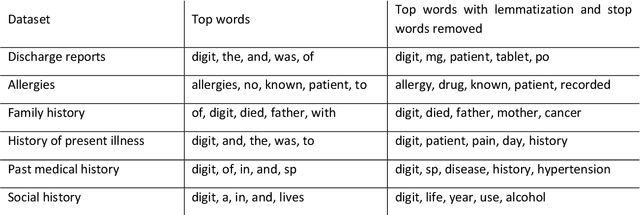
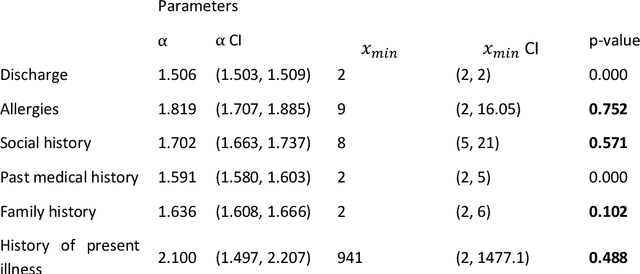
Bayesian modelling and statistical text analysis rely on informed probability priors to encourage good solutions. This paper empirically analyses whether text in medical discharge reports follow Zipf's law, a commonly assumed statistical property of language where word frequency follows a discrete power law distribution. We examined 20,000 medical discharge reports from the MIMIC-III dataset. Methods included splitting the discharge reports into tokens, counting token frequency, fitting power law distributions to the data, and testing whether alternative distributions--lognormal, exponential, stretched exponential, and truncated power law--provided superior fits to the data. Results show that discharge reports are best fit by the truncated power law and lognormal distributions. Our findings suggest that Bayesian modelling and statistical text analysis of discharge report text would benefit from using truncated power law and lognormal probability priors.