 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgilePruner: An Empirical Study of Attention and Diversity for Adaptive Visual Token Pruning in Large Vision-Language Models
Mar 01, 2026Large Vision-Language Models (LVLMs) have adopted visual token pruning strategies to mitigate substantial computational overhead incurred by extensive visual token sequences. While prior works primarily focus on either attention-based or diversity-based pruning methods, in-depth analysis of these approaches' characteristics and limitations remains largely unexplored. In this work, we conduct thorough empirical analysis using effective rank (erank) as a measure of feature diversity and attention score entropy to investigate visual token processing mechanisms and analyze the strengths and weaknesses of each approach. Our analysis reveals two insights: (1) Our erank-based quantitative analysis shows that many diversity-oriented pruning methods preserve substantially less feature diversity than intended; moreover, analysis using the CHAIR dataset reveals that the diversity they do retain is closely tied to increased hallucination frequency compared to attention-based pruning. (2) We further observe that attention-based approaches are more effective on simple images where visual evidence is concentrated, while diversity-based methods better handle complex images with distributed features. Building on these empirical insights, we show that incorporating image-aware adjustments into existing hybrid pruning strategies consistently improves their performance. We also provide a minimal instantiation of our empirical findings through a simple adaptive pruning mechanism, which achieves strong and reliable performance across standard benchmarks as well as hallucination-specific evaluations. Our project page available at https://cvsp-lab.github.io/AgilePruner.
AnoSeg: Anomaly Segmentation Network Using Self-Supervised Learning
Oct 07, 2021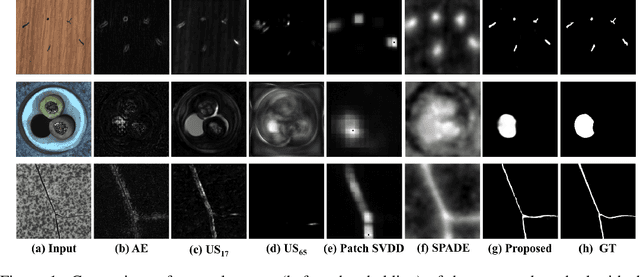
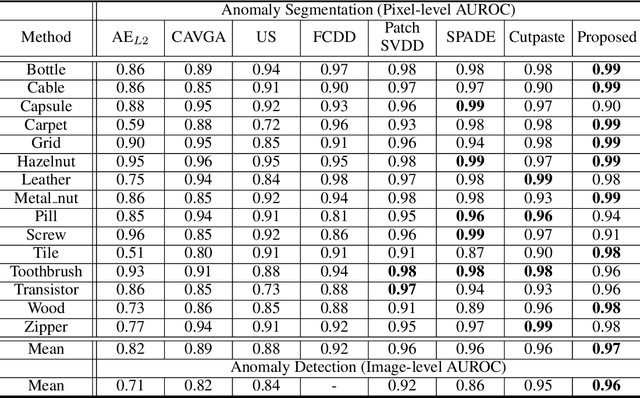
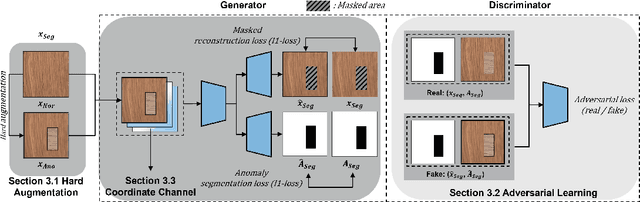

Anomaly segmentation, which localizes defective areas, is an important component in large-scale industrial manufacturing. However, most recent researches have focused on anomaly detection. This paper proposes a novel anomaly segmentation network (AnoSeg) that can directly generate an accurate anomaly map using self-supervised learning. For highly accurate anomaly segmentation, the proposed AnoSeg considers three novel techniques: Anomaly data generation based on hard augmentation, self-supervised learning with pixel-wise and adversarial losses, and coordinate channel concatenation. First, to generate synthetic anomaly images and reference masks for normal data, the proposed method uses hard augmentation to change the normal sample distribution. Then, the proposed AnoSeg is trained in a self-supervised learning manner from the synthetic anomaly data and normal data. Finally, the coordinate channel, which represents the pixel location information, is concatenated to an input of AnoSeg to consider the positional relationship of each pixel in the image. The estimated anomaly map can also be utilized to improve the performance of anomaly detection. Our experiments show that the proposed method outperforms the state-of-the-art anomaly detection and anomaly segmentation methods for the MVTec AD dataset. In addition, we compared the proposed method with the existing methods through the intersection over union (IoU) metric commonly used in segmentation tasks and demonstrated the superiority of our method for anomaly segmentation.