 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do the metrics mean? A critical analysis of the use of Automated Evaluation Metrics in Interpreting
Jan 09, 2026With the growth of interpreting technologies, from remote interpreting and Computer-Aided Interpreting to automated speech translation and interpreting avatars, there is now a high demand for ways to quickly and efficiently measure the quality of any interpreting delivered. A range of approaches to fulfil the need for quick and efficient quality measurement have been proposed, each involving some measure of automation. This article examines these recently-proposed quality measurement methods and will discuss their suitability for measuring the quality of authentic interpreting practice, whether delivered by humans or machines, concluding that automatic metrics as currently proposed cannot take into account the communicative context and thus are not viable measures of the quality of any interpreting provision when used on their own. Across all attempts to measure or even categorise quality in Interpreting Studies, the contexts in which interpreting takes place have become fundamental to the final analysis.
Sociotechnical Effects of Machine Translation
Mar 26, 2025


While the previous chapters have shown how machine translation (MT) can be useful, in this chapter we discuss some of the side-effects and risks that are associated, and how they might be mitigated. With the move to neural MT and approaches using Large Language Models (LLMs), there is an associated impact on climate change, as the models built by multinational corporations are massive. They are hugely expensive to train, consume large amounts of electricity, and output huge volumes of kgCO2 to boot. However, smaller models which still perform to a high level of quality can be built with much lower carbon footprints, and tuning pre-trained models saves on the requirement to train from scratch. We also discuss the possible detrimental effects of MT on translators and other users. The topics of copyright and ownership of data are discussed, as well as ethical considerations on data and MT use. Finally, we show how if done properly, using MT in crisis scenarios can save lives, and we provide a method of how this might be done.
Towards transparency in NLP shared tasks
May 11, 2021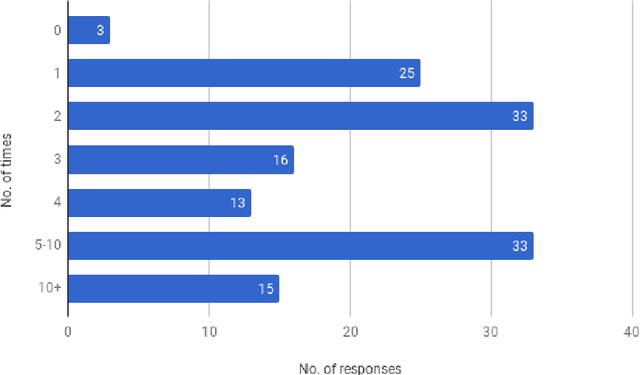
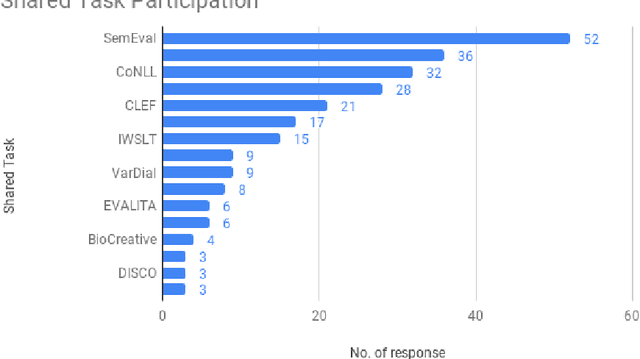
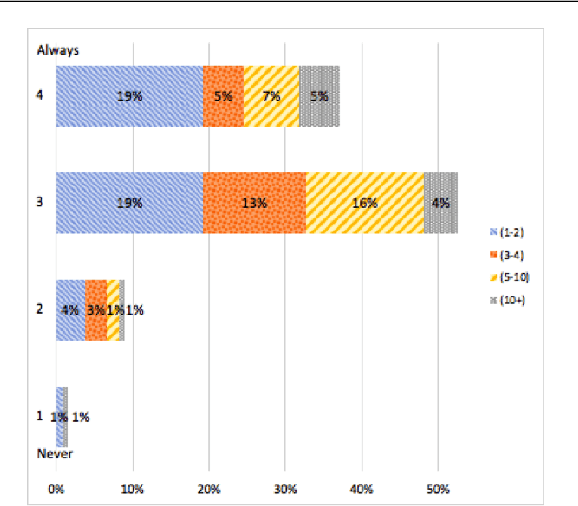
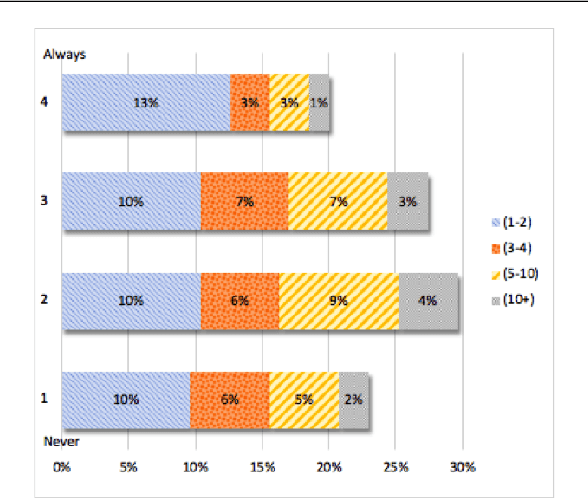
This article reports on a survey carried out across the Natural Language Processing (NLP) community. The survey aimed to capture the opinions of the research community on issues surrounding shared tasks, with respect to both participation and organisation. Amongst the 175 responses received, both positive and negative observations were made. We carried out and report on an extensive analysis of these responses, which leads us to propose a Shared Task Organisation Checklist that could support future participants and organisers. The proposed Checklist is flexible enough to accommodate the wide diversity of shared tasks in our field and its goal is not to be prescriptive, but rather to serve as a tool that encourages shared task organisers to foreground ethical behaviour, beginning with the common issues that the 175 respondents deemed important. Its usage would not only serve as an instrument to reflect on important aspects of shared tasks, but would also promote increased transparency around them.