 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Real-Time ECG and EMG Modeling on $μ$NPUs
Apr 21, 2026The miniaturisation of neural processing units (NPUs) and other low-power accelerators has enabled their integration into microcontroller-scale wearable hardware, supporting near-real-time, offline, and privacy-preserving inference. Yet physiological signal analysis has remained infeasible on such hardware; recent Transformer-based models show state-of-the-art performance but are prohibitively large for resource- and power-constrained hardware and incompatible with $μ$NPUs due to their dynamic attention operations. We introduce PhysioLite, a lightweight, NPU-compatible model architecture and training framework for ECG/EMG signal analysis. Using learnable wavelet filter banks, CPU-offloaded positional encoding, and hardware-aware layer design, PhysioLite reaches performance comparable to state-of-the-art Transformer-based foundation models on ECG and EMG benchmarks, while being <10% of the size ($\sim$370KB with 8-bit quantization). We also profile its component-wise latency and resource consumption on both the MAX78000 and HX6538 WE2 $μ$NPUs, demonstrating its viability for signal analysis on constrained, battery-powered hardware. We release our model(s) and training framework at: https://github.com/j0shmillar/physiolite.
Bifröst: Spatial Networking with Bigraphs
Jul 30, 2025Modern networked environments increasingly rely on spatial reasoning, but lack a coherent representation for coordinating physical space. Consequently, tasks such as enforcing spatial access policies remain fragile and manual. We first propose a unifying representation based on bigraphs, capturing spatial, social, and communication relationships within a single formalism, with user-facing tools to generate bigraphs from physical environments. Second, we present a hierarchical agent architecture for distributed spatial reasoning, with runtimes for agentic processes to interact the spatial representation, and a context-aware execution model that scopes reasoning to the smallest viable subspace. Together, these enable private, reliable, and low-latency spatial networking that can safely interact with agentic workflows.
Energy-Aware Deep Learning on Resource-Constrained Hardware
May 18, 2025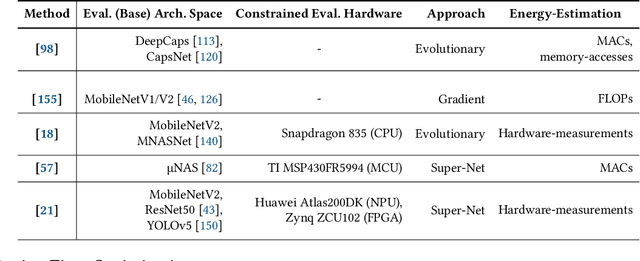
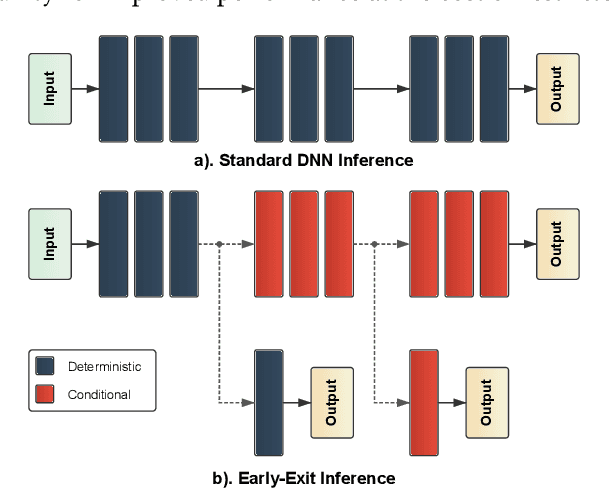
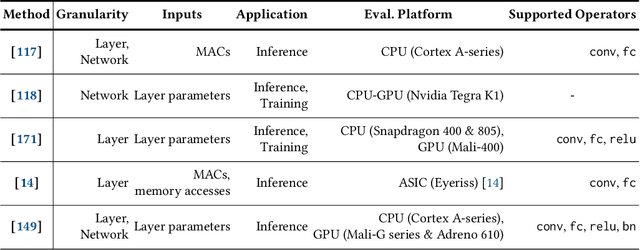
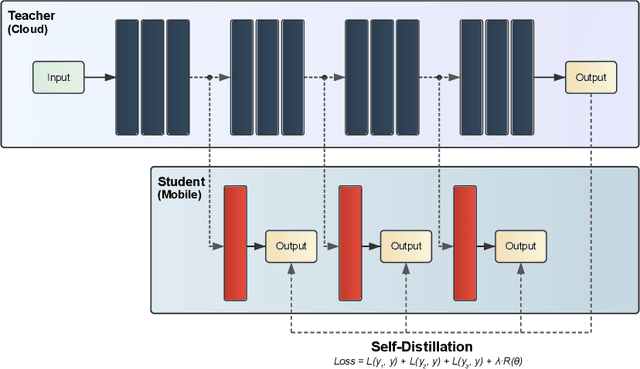
The use of deep learning (DL) on Internet of Things (IoT) and mobile devices offers numerous advantages over cloud-based processing. However, such devices face substantial energy constraints to prolong battery-life, or may even operate intermittently via energy-harvesting. Consequently, \textit{energy-aware} approaches for optimizing DL inference and training on such resource-constrained devices have garnered recent interest. We present an overview of such approaches, outlining their methodologies, implications for energy consumption and system-level efficiency, and their limitations in terms of supported network types, hardware platforms, and application scenarios. We hope our review offers a clear synthesis of the evolving energy-aware DL landscape and serves as a foundation for future research in energy-constrained computing.
Benchmarking Ultra-Low-Power $μ$NPUs
Mar 28, 2025



Efficient on-device neural network (NN) inference has various advantages over cloud-based processing, including predictable latency, enhanced privacy, greater reliability, and reduced operating costs for vendors. This has sparked the recent rapid development of microcontroller-scale NN accelerators, often referred to as neural processing units ($\mu$NPUs), designed specifically for ultra-low-power applications. In this paper we present the first comparative evaluation of a number of commercially-available $\mu$NPUs, as well as the first independent benchmarks for several of these platforms. We develop and open-source a model compilation framework to enable consistent benchmarking of quantized models across diverse $\mu$NPU hardware. Our benchmark targets end-to-end performance and includes model inference latency, power consumption, and memory overhead, alongside other factors. The resulting analysis uncovers both expected performance trends as well as surprising disparities between hardware specifications and actual performance, including $\mu$NPUs exhibiting unexpected scaling behaviors with increasing model complexity. Our framework provides a foundation for further evaluation of $\mu$NPU platforms alongside valuable insights for both hardware designers and software developers in this rapidly evolving space.
Terracorder: Sense Long and Prosper
Aug 05, 2024In-situ sensing devices need to be deployed in remote environments for long periods of time; minimizing their power consumption is vital for maximising both their operational lifetime and coverage. We introduce Terracorder -- a versatile multi-sensor device -- and showcase its exceptionally low power consumption using an on-device reinforcement learning scheduler. We prototype a unique device setup for biodiversity monitoring and compare its battery life using our scheduler against a number of fixed schedules; the scheduler captures more than 80% of events at less than 50% of the number of activations of the best-performing fixed schedule. We then explore how a collaborative scheduler can maximise the useful operation of a network of devices, improving overall network power consumption and robustness.
Towards Low-Energy Adaptive Personalization for Resource-Constrained Devices
Mar 29, 2024The personalization of machine learning (ML) models to address data drift is a significant challenge in the context of Internet of Things (IoT) applications. Presently, most approaches focus on fine-tuning either the full base model or its last few layers to adapt to new data, while often neglecting energy costs. However, various types of data drift exist, and fine-tuning the full base model or the last few layers may not result in optimal performance in certain scenarios. We propose Target Block Fine-Tuning (TBFT), a low-energy adaptive personalization framework designed for resource-constrained devices. We categorize data drift and personalization into three types: input-level, feature-level, and output-level. For each type, we fine-tune different blocks of the model to achieve optimal performance with reduced energy costs. Specifically, input-, feature-, and output-level correspond to fine-tuning the front, middle, and rear blocks of the model. We evaluate TBFT on a ResNet model, three datasets, three different training sizes, and a Raspberry Pi. Compared with the $Block Avg$, where each block is fine-tuned individually and their performance improvements are averaged, TBFT exhibits an improvement in model accuracy by an average of 15.30% whilst saving 41.57% energy consumption on average compared with full fine-tuning.