 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearness of Neighbors Attention for Regression in Supervised Finetuning
Jun 09, 2025It is common in supervised machine learning to combine the feature extraction capabilities of neural networks with the predictive power of traditional algorithms, such as k-nearest neighbors (k-NN) or support vector machines. This procedure involves performing supervised fine-tuning (SFT) on a domain-appropriate feature extractor, followed by training a traditional predictor on the resulting SFT embeddings. When used in this manner, traditional predictors often deliver increased performance over the SFT model itself, despite the fine-tuned feature extractor yielding embeddings specifically optimized for prediction by the neural network's final dense layer. This suggests that directly incorporating traditional algorithms into SFT as prediction layers may further improve performance. However, many traditional algorithms have not been implemented as neural network layers due to their non-differentiable nature and their unique optimization requirements. As a step towards solving this problem, we introduce the Nearness of Neighbors Attention (NONA) regression layer. NONA uses the mechanics of neural network attention and a novel learned attention-masking scheme to yield a differentiable proxy of the k-NN regression algorithm. Results on multiple unstructured datasets show improved performance over both dense layer prediction and k-NN on SFT embeddings for regression.
CAtCh: Cognitive Assessment through Cookie Thief
Jun 07, 2025Several machine learning algorithms have been developed for the prediction of Alzheimer's disease and related dementia (ADRD) from spontaneous speech. However, none of these algorithms have been translated for the prediction of broader cognitive impairment (CI), which in some cases is a precursor and risk factor of ADRD. In this paper, we evaluated several speech-based open-source methods originally proposed for the prediction of ADRD, as well as methods from multimodal sentiment analysis for the task of predicting CI from patient audio recordings. Results demonstrated that multimodal methods outperformed unimodal ones for CI prediction, and that acoustics-based approaches performed better than linguistics-based ones. Specifically, interpretable acoustic features relating to affect and prosody were found to significantly outperform BERT-based linguistic features and interpretable linguistic features, respectively. All the code developed for this study is available at https://github.com/JTColonel/catch.
Conditioning Autoencoder Latent Spaces for Real-Time Timbre Interpolation and Synthesis
Jan 30, 2020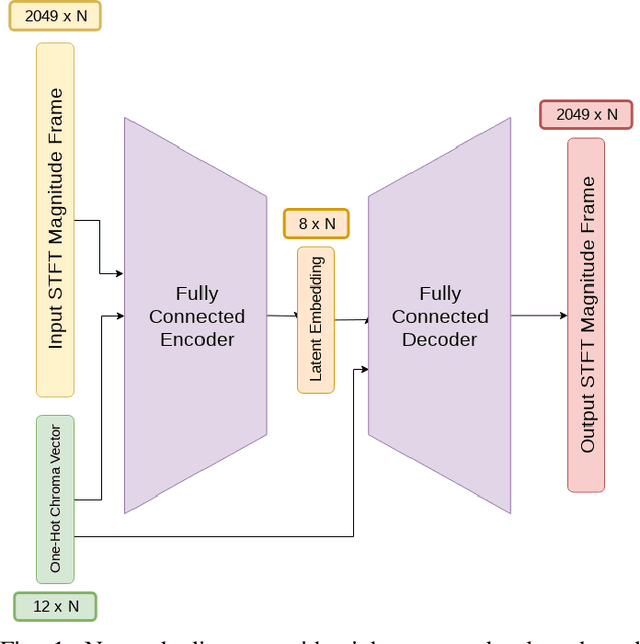
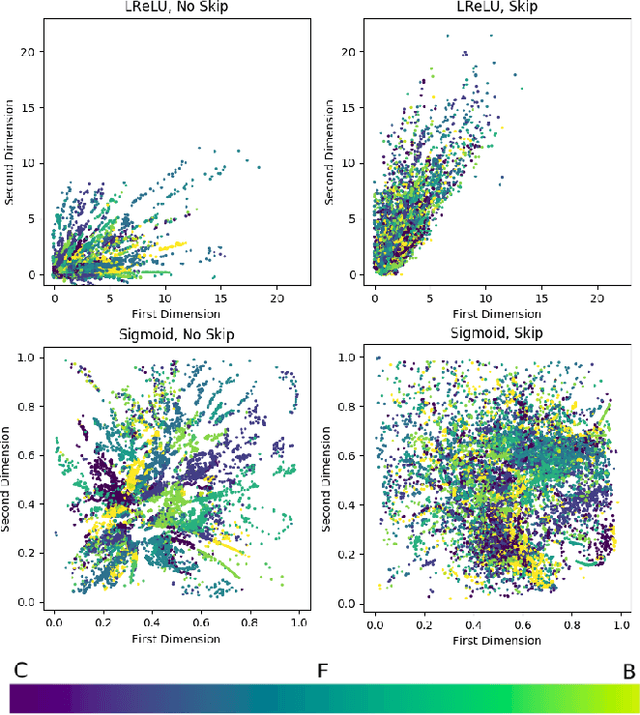
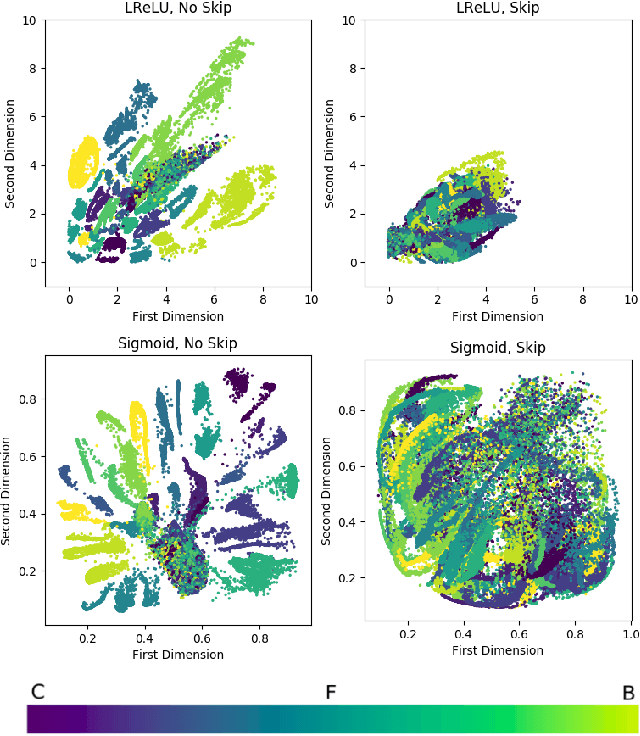
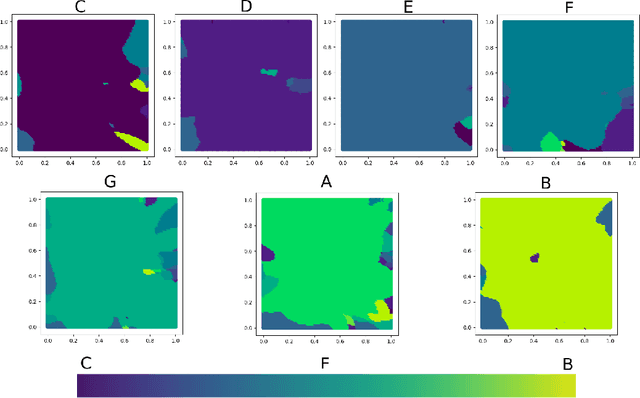
We compare standard autoencoder topologies' performances for timbre generation. We demonstrate how different activation functions used in the autoencoder's bottleneck distributes a training corpus's embedding. We show that the choice of sigmoid activation in the bottleneck produces a more bounded and uniformly distributed embedding than a leaky rectified linear unit activation. We propose a one-hot encoded chroma feature vector for use in both input augmentation and latent space conditioning. We measure the performance of these networks, and characterize the latent embeddings that arise from the use of this chroma conditioning vector. An open source, real-time timbre synthesis algorithm in Python is outlined and shared.