 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite size corrections for neural network Gaussian processes
Aug 27, 2019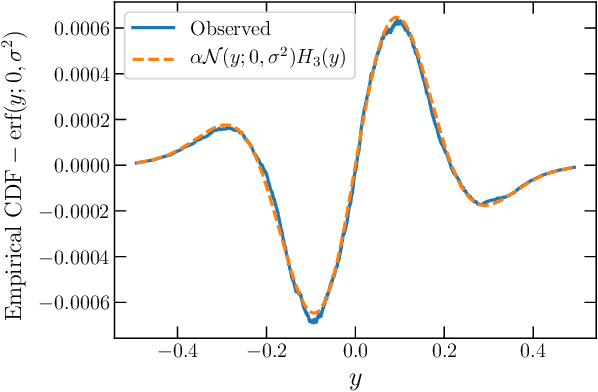
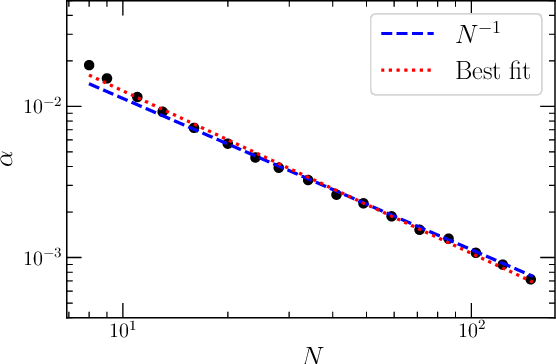
There has been a recent surge of interest in modeling neural networks (NNs) as Gaussian processes. In the limit of a NN of infinite width the NN becomes equivalent to a Gaussian process. Here we demonstrate that for an ensemble of large, finite, fully connected networks with a single hidden layer the distribution of outputs at initialization is well described by a Gaussian perturbed by the fourth Hermite polynomial for weights drawn from a symmetric distribution. We show that the scale of the perturbation is inversely proportional to the number of units in the NN and that higher order terms decay more rapidly, thereby recovering the Edgeworth expansion. We conclude by observing that understanding how this perturbation changes under training would reveal the regimes in which the Gaussian process framework is valid to model NN behavior.
PCA of high dimensional random walks with comparison to neural network training
Jun 22, 2018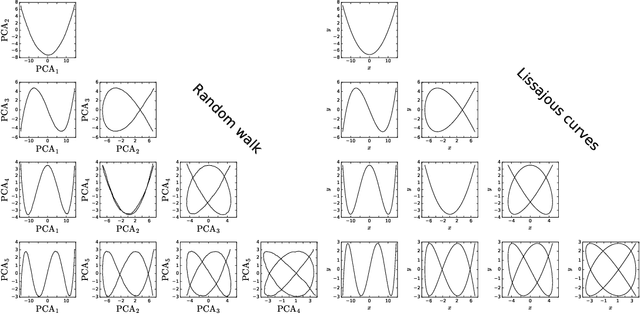
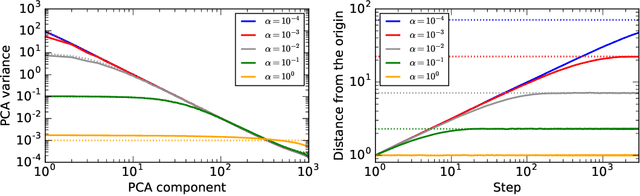
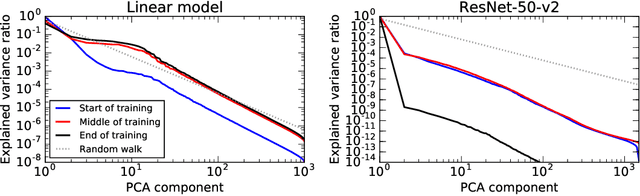
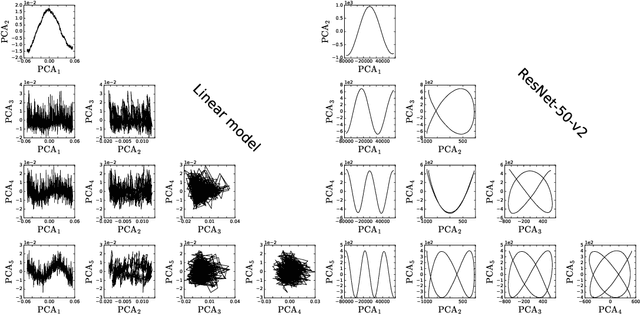
One technique to visualize the training of neural networks is to perform PCA on the parameters over the course of training and to project to the subspace spanned by the first few PCA components. In this paper we compare this technique to the PCA of a high dimensional random walk. We compute the eigenvalues and eigenvectors of the covariance of the trajectory and prove that in the long trajectory and high dimensional limit most of the variance is in the first few PCA components, and that the projection of the trajectory onto any subspace spanned by PCA components is a Lissajous curve. We generalize these results to a random walk with momentum and to an Ornstein-Uhlenbeck processes (i.e., a random walk in a quadratic potential) and show that in high dimensions the walk is not mean reverting, but will instead be trapped at a fixed distance from the minimum. We finally compare the distribution of PCA variances and the PCA projected training trajectories of a linear model trained on CIFAR-10 and ResNet-50-v2 trained on Imagenet and find that the distribution of PCA variances resembles a random walk with drift.