 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral methods: crucial for machine learning, natural for quantum computers?
Mar 25, 2026This article presents an argument for why quantum computers could unlock new methods for machine learning. We argue that spectral methods, in particular those that learn, regularise, or otherwise manipulate the Fourier spectrum of a machine learning model, are often natural for quantum computers. For example, if a generative machine learning model is represented by a quantum state, the Quantum Fourier Transform allows us to manipulate the Fourier spectrum of the state using the entire toolbox of quantum routines, an operation that is usually prohibitive for classical models. At the same time, spectral methods are surprisingly fundamental to machine learning: A spectral bias has recently been hypothesised to be the core principle behind the success of deep learning; support vector machines have been known for decades to regularise in Fourier space, and convolutional neural nets build filters in the Fourier space of images. Could, then, quantum computing open fundamentally different, much more direct and resource-efficient ways to design the spectral properties of a model? We discuss this potential in detail here, hoping to stimulate a direction in quantum machine learning research that puts the question of ``why quantum?'' first.
IQP Born Machines under Data-dependent and Agnostic Initialization Strategies
Mar 15, 2026Quantum circuit Born machines based on instantaneous quantum polynomial-time (IQP) circuits are natural candidates for quantum generative modeling, both because of their probabilistic structure and because IQP sampling is provably classically hard in certain regimes. Recent proposals focus on training IQP-QCBMs using Maximum Mean Discrepancy (MMD) losses built from low-body Pauli-$Z$ correlators, but the effect of initialization on the resulting optimization landscape remains poorly understood. In this work, we address this by first proving that the MMD loss landscape suffers from barren plateaus for random full-angle-range initializations of IQP circuits. We then establish lower bounds on the loss variance for identity and an unbiased data-agnostic initialization. We then additionally consider a data-dependent initialization that is better aligned with the target distribution and, under suitable assumptions, yields provable gradients and generally converges quicker to a good minimum (as indicated by our training of circuits with 150 qubits on genomic data). Finally, as a by-product, the developed variance lower bound framework is applicable to a general class of non-linear losses, offering a broader toolset for analyzing warm-starts in quantum machine learning.
Better than classical? The subtle art of benchmarking quantum machine learning models
Mar 14, 2024



Benchmarking models via classical simulations is one of the main ways to judge ideas in quantum machine learning before noise-free hardware is available. However, the huge impact of the experimental design on the results, the small scales within reach today, as well as narratives influenced by the commercialisation of quantum technologies make it difficult to gain robust insights. To facilitate better decision-making we develop an open-source package based on the PennyLane software framework and use it to conduct a large-scale study that systematically tests 12 popular quantum machine learning models on 6 binary classification tasks used to create 160 individual datasets. We find that overall, out-of-the-box classical machine learning models outperform the quantum classifiers. Moreover, removing entanglement from a quantum model often results in as good or better performance, suggesting that "quantumness" may not be the crucial ingredient for the small learning tasks considered here. Our benchmarks also unlock investigations beyond simplistic leaderboard comparisons, and we identify five important questions for quantum model design that follow from our results.
Fast semidefinite programming with feedforward neural networks
Nov 12, 2020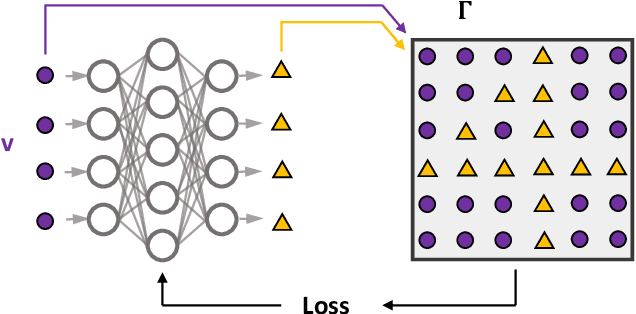
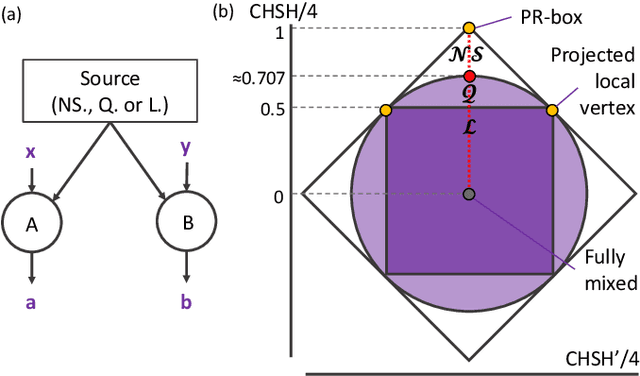
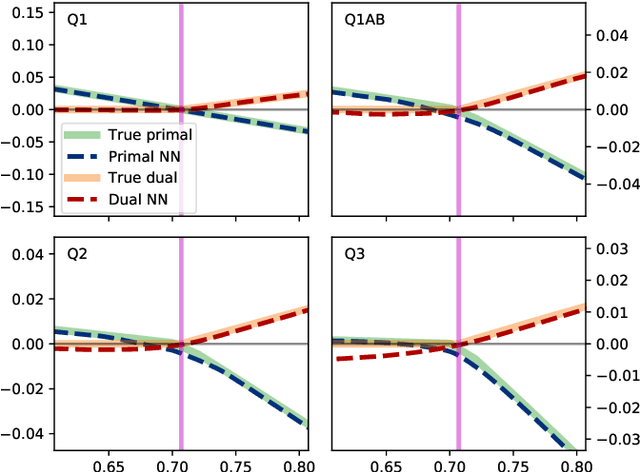
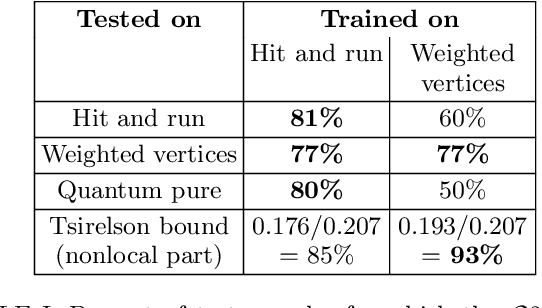
Semidefinite programming is an important optimization task, often used in time-sensitive applications. Though they are solvable in polynomial time, in practice they can be too slow to be used in online, i.e. real-time applications. Here we propose to solve feasibility semidefinite programs using artificial neural networks. Given the optimization constraints as an input, a neural network outputs values for the optimization parameters such that the constraints are satisfied, both for the primal and the dual formulations of the task. We train the network without having to exactly solve the semidefinite program even once, thus avoiding the possibly time-consuming task of having to generate many training samples with conventional solvers. The neural network method is only inconclusive if both the primal and dual models fail to provide feasible solutions. Otherwise we always obtain a certificate, which guarantees false positives to be excluded. We examine the performance of the method on a hierarchy of quantum information tasks, the Navascu\'es-Pironio-Ac\'in hierarchy applied to the Bell scenario. We demonstrate that the trained neural network gives decent accuracy, while showing orders of magnitude increase in speed compared to a traditional solver.