 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOON: Multi-Hash Codes Joint Learning for Cross-Media Retrieval
Aug 17, 2021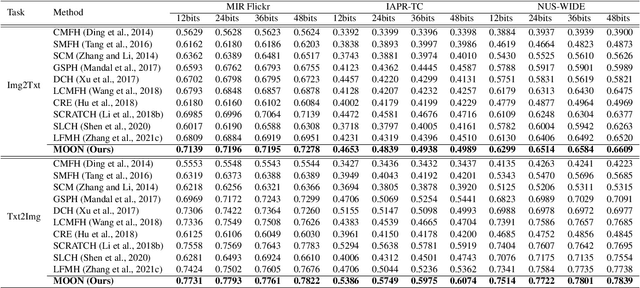
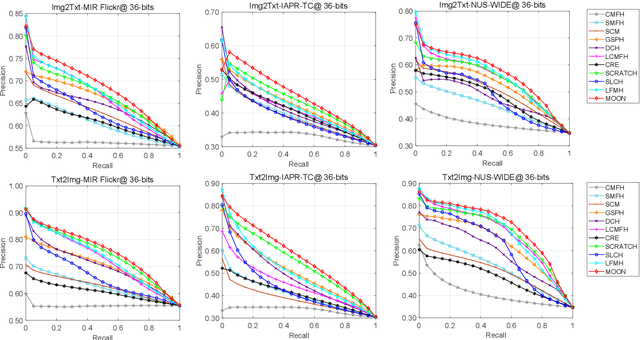
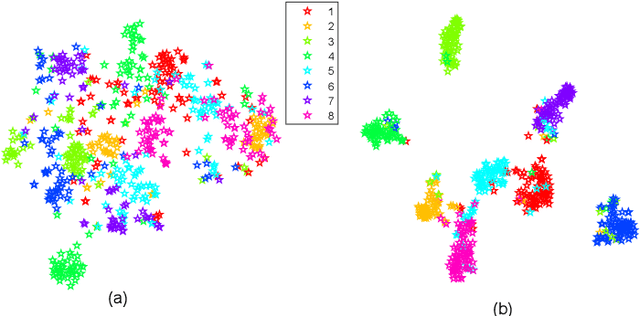
In recent years, cross-media hashing technique has attracted increasing attention for its high computation efficiency and low storage cost. However, the existing approaches still have some limitations, which need to be explored. 1) A fixed hash length (e.g., 16bits or 32bits) is predefined before learning the binary codes. Therefore, these models need to be retrained when the hash length changes, that consumes additional computation power, reducing the scalability in practical applications. 2) Existing cross-modal approaches only explore the information in the original multimedia data to perform the hash learning, without exploiting the semantic information contained in the learned hash codes. To this end, we develop a novel Multiple hash cOdes jOint learNing method (MOON) for cross-media retrieval. Specifically, the developed MOON synchronously learns the hash codes with multiple lengths in a unified framework. Besides, to enhance the underlying discrimination, we combine the clues from the multimodal data, semantic labels and learned hash codes for hash learning. As far as we know, the proposed MOON is the first work to simultaneously learn different length hash codes without retraining in cross-media retrieval. Experiments on several databases show that our MOON can achieve promising performance, outperforming some recent competitive shallow and deep methods.
PPT Fusion: Pyramid Patch Transformerfor a Case Study in Image Fusion
Jul 29, 2021

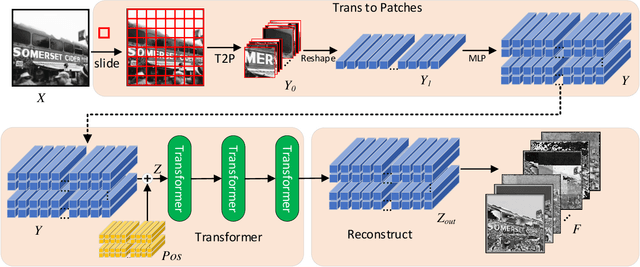
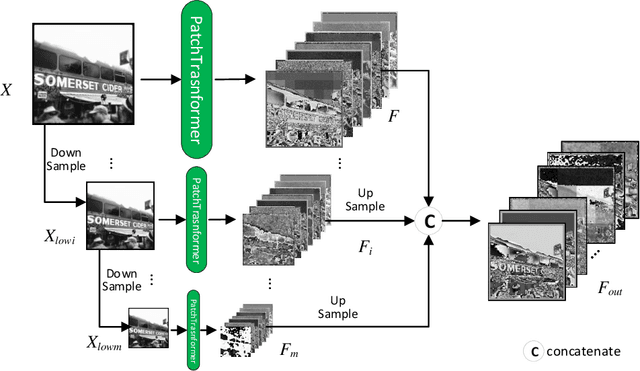
The Transformer architecture has achieved rapiddevelopment in recent years, outperforming the CNN archi-tectures in many computer vision tasks, such as the VisionTransformers (ViT) for image classification. However, existingvisual transformer models aim to extract semantic informationfor high-level tasks such as classification and detection, distortingthe spatial resolution of the input image, thus sacrificing thecapacity in reconstructing the input or generating high-resolutionimages. In this paper, therefore, we propose a Patch PyramidTransformer(PPT) to effectively address the above issues. Specif-ically, we first design a Patch Transformer to transform theimage into a sequence of patches, where transformer encodingis performed for each patch to extract local representations.In addition, we construct a Pyramid Transformer to effectivelyextract the non-local information from the entire image. Afterobtaining a set of multi-scale, multi-dimensional, and multi-anglefeatures of the original image, we design the image reconstructionnetwork to ensure that the features can be reconstructed intothe original input. To validate the effectiveness, we apply theproposed Patch Pyramid Transformer to the image fusion task.The experimental results demonstrate its superior performanceagainst the state-of-the-art fusion approaches, achieving the bestresults on several evaluation indicators. The underlying capacityof the PPT network is reflected by its universal power in featureextraction and image reconstruction, which can be directlyapplied to different image fusion tasks without redesigning orretraining the network.
SiT: Self-supervised vIsion Transformer
Apr 08, 2021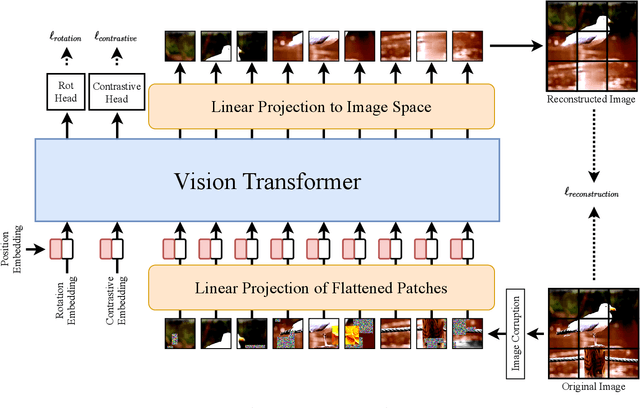
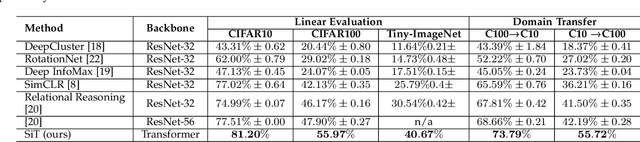

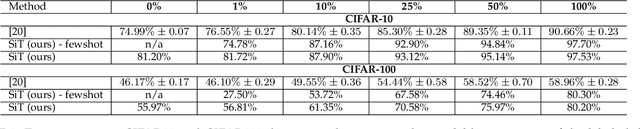
Self-supervised learning methods are gaining increasing traction in computer vision due to their recent success in reducing the gap with supervised learning. In natural language processing (NLP) self-supervised learning and transformers are already the methods of choice. The recent literature suggests that the transformers are becoming increasingly popular also in computer vision. So far, the vision transformers have been shown to work well when pretrained either using a large scale supervised data or with some kind of co-supervision, e.g. in terms of teacher network. These supervised pretrained vision transformers achieve very good results in downstream tasks with minimal changes. In this work we investigate the merits of self-supervised learning for pretraining image/vision transformers and then using them for downstream classification tasks. We propose Self-supervised vIsion Transformers (SiT) and discuss several self-supervised training mechanisms to obtain a pretext model. The architectural flexibility of SiT allows us to use it as an autoencoder and work with multiple self-supervised tasks seamlessly. We show that a pretrained SiT can be finetuned for a downstream classification task on small scale datasets, consisting of a few thousand images rather than several millions. The proposed approach is evaluated on standard datasets using common protocols. The results demonstrate the strength of the transformers and their suitability for self-supervised learning. We outperformed existing self-supervised learning methods by large margin. We also observed that SiT is good for few shot learning and also showed that it is learning useful representation by simply training a linear classifier on top of the learned features from SiT. Pretraining, finetuning, and evaluation codes will be available under: https://github.com/Sara-Ahmed/SiT.
RFN-Nest: An end-to-end residual fusion network for infrared and visible images
Mar 14, 2021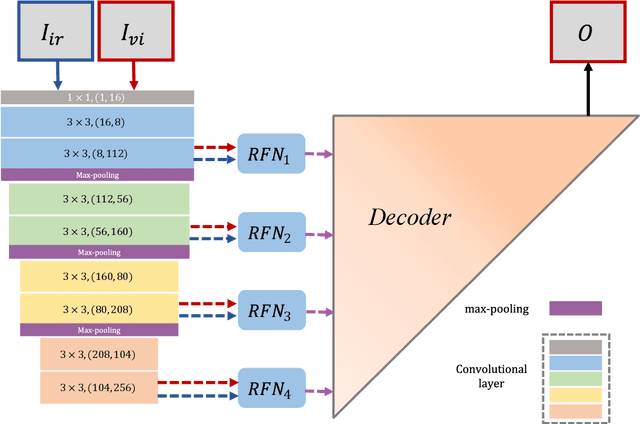
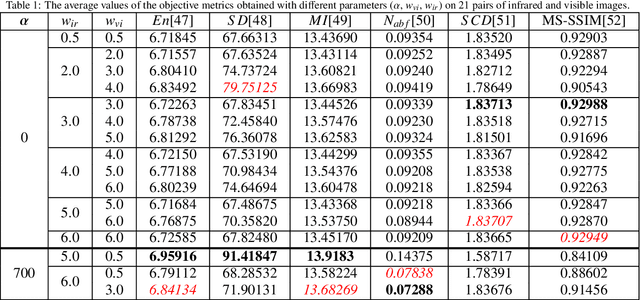
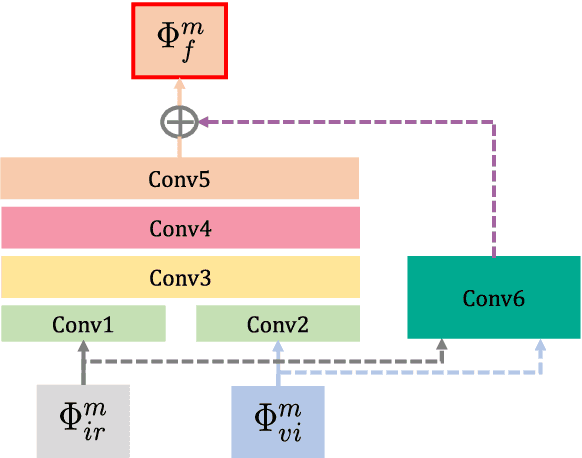

In the image fusion field, the design of deep learning-based fusion methods is far from routine. It is invariably fusion-task specific and requires a careful consideration. The most difficult part of the design is to choose an appropriate strategy to generate the fused image for a specific task in hand. Thus, devising learnable fusion strategy is a very challenging problem in the community of image fusion. To address this problem, a novel end-to-end fusion network architecture (RFN-Nest) is developed for infrared and visible image fusion. We propose a residual fusion network (RFN) which is based on a residual architecture to replace the traditional fusion approach. A novel detail-preserving loss function, and a feature enhancing loss function are proposed to train RFN. The fusion model learning is accomplished by a novel two-stage training strategy. In the first stage, we train an auto-encoder based on an innovative nest connection (Nest) concept. Next, the RFN is trained using the proposed loss functions. The experimental results on public domain data sets show that, compared with the existing methods, our end-to-end fusion network delivers a better performance than the state-of-the-art methods in both subjective and objective evaluation. The code of our fusion method is available at https://github.com/hli1221/imagefusion-rfn-nest
NPT-Loss: A Metric Loss with Implicit Mining for Face Recognition
Mar 05, 2021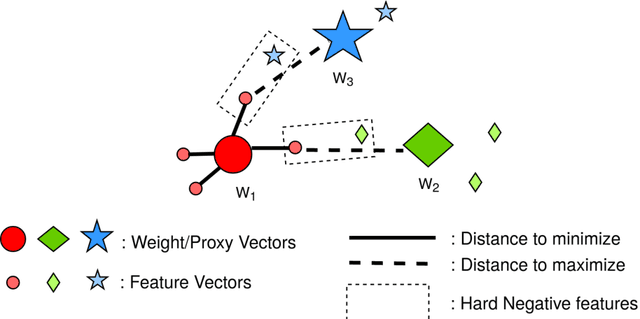

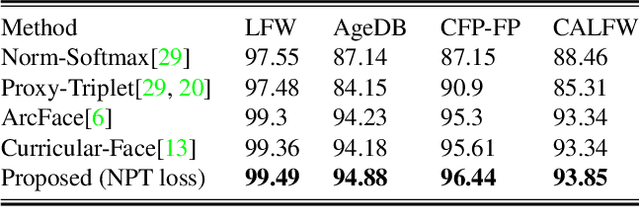
Face recognition (FR) using deep convolutional neural networks (DCNNs) has seen remarkable success in recent years. One key ingredient of DCNN-based FR is the appropriate design of a loss function that ensures discrimination between various identities. The state-of-the-art (SOTA) solutions utilise normalised Softmax loss with additive and/or multiplicative margins. Despite being popular, these Softmax+margin based losses are not theoretically motivated and the effectiveness of a margin is justified only intuitively. In this work, we utilise an alternative framework that offers a more direct mechanism of achieving discrimination among the features of various identities. We propose a novel loss that is equivalent to a triplet loss with proxies and an implicit mechanism of hard-negative mining. We give theoretical justification that minimising the proposed loss ensures a minimum separability between all identities. The proposed loss is simple to implement and does not require heavy hyper-parameter tuning as in the SOTA solutions. We give empirical evidence that despite its simplicity, the proposed loss consistently achieves SOTA performance in various benchmarks for both high-resolution and low-resolution FR tasks.
Differentiable Neural Architecture Learning for Efficient Neural Network Design
Mar 03, 2021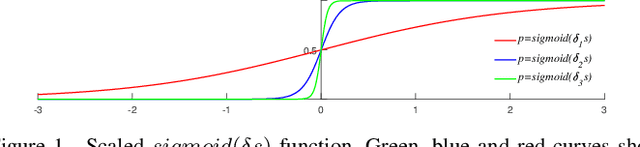
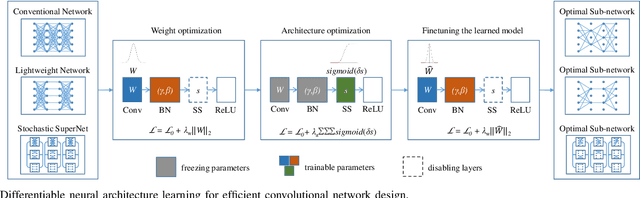
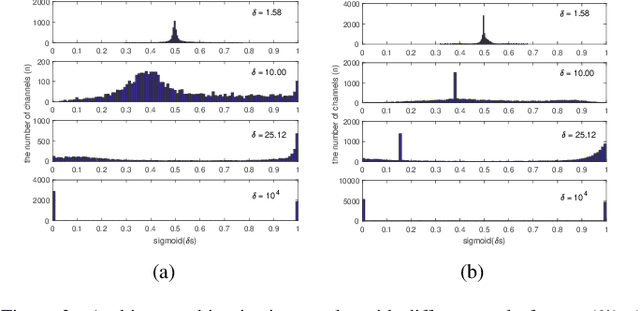
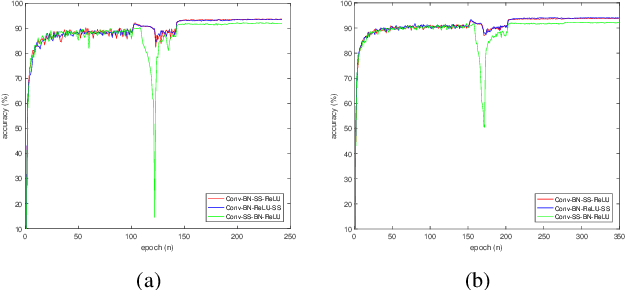
Automated neural network design has received ever-increasing attention with the evolution of deep convolutional neural networks (CNNs), especially involving their deployment on embedded and mobile platforms. One of the biggest problems that neural architecture search (NAS) confronts is that a large number of candidate neural architectures are required to train, using, for instance, reinforcement learning and evolutionary optimisation algorithms, at a vast computation cost. Even recent differentiable neural architecture search (DNAS) samples a small number of candidate neural architectures based on the probability distribution of learned architecture parameters to select the final neural architecture. To address this computational complexity issue, we introduce a novel \emph{architecture parameterisation} based on scaled sigmoid function, and propose a general \emph{Differentiable Neural Architecture Learning} (DNAL) method to optimize the neural architecture without the need to evaluate candidate neural networks. Specifically, for stochastic supernets as well as conventional CNNs, we build a new channel-wise module layer with the architecture components controlled by a scaled sigmoid function. We train these neural network models from scratch. The network optimization is decoupled into the weight optimization and the architecture optimization. We address the non-convex optimization problem of neural architecture by the continuous scaled sigmoid method with convergence guarantees. Extensive experiments demonstrate our DNAL method delivers superior performance in terms of neural architecture search cost. The optimal networks learned by DNAL surpass those produced by the state-of-the-art methods on the benchmark CIFAR-10 and ImageNet-1K dataset in accuracy, model size and computational complexity.
A Deep Decomposition Network for Image Processing: A Case Study for Visible and Infrared Image Fusion
Feb 21, 2021
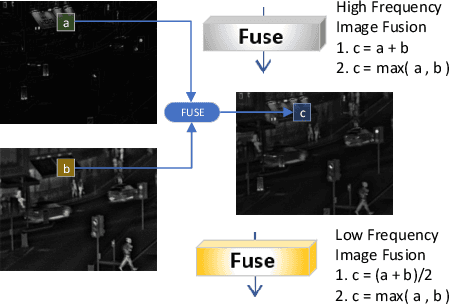
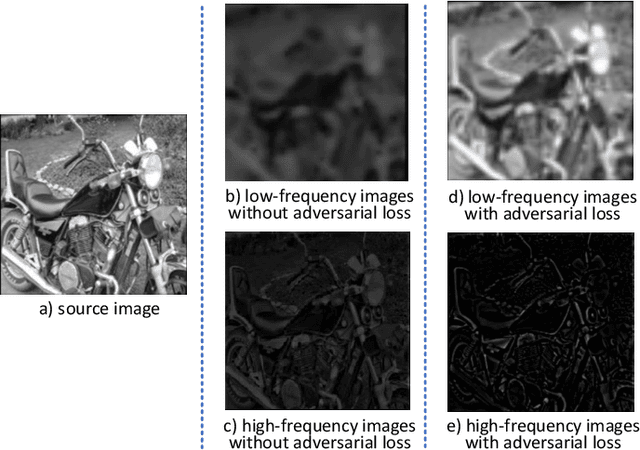

Image decomposition is a crucial subject in the field of image processing. It can extract salient features from the source image. We propose a new image decomposition method based on convolutional neural network. This method can be applied to many image processing tasks. In this paper, we apply the image decomposition network to the image fusion task. We input infrared image and visible light image and decompose them into three high-frequency feature images and a low-frequency feature image respectively. The two sets of feature images are fused using a specific fusion strategy to obtain fusion feature images. Finally, the feature images are reconstructed to obtain the fused image. Compared with the state-of-the-art fusion methods, this method has achieved better performance in both subjective and objective evaluation.
AXM-Net: Cross-Modal Context Sharing Attention Network for Person Re-ID
Jan 19, 2021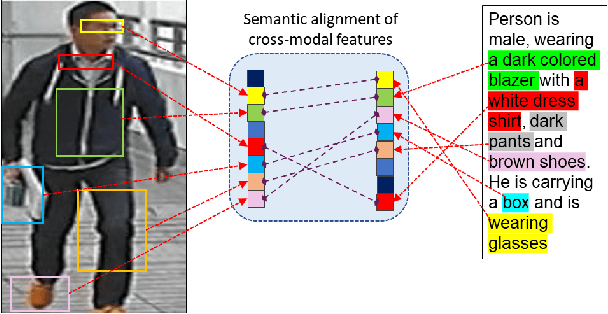
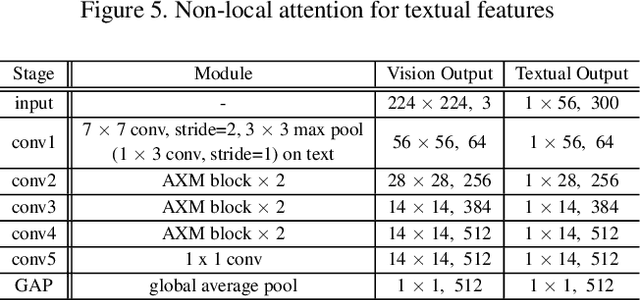
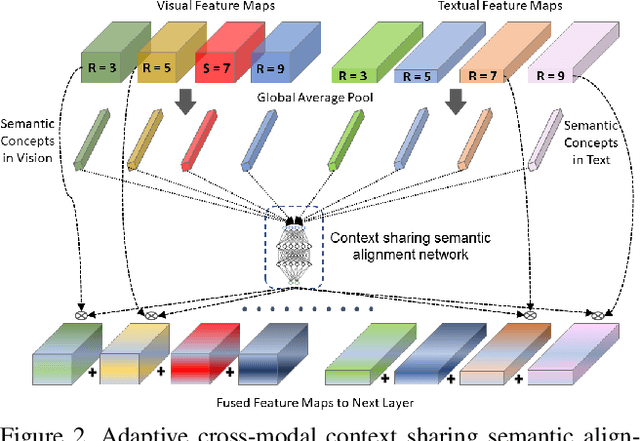
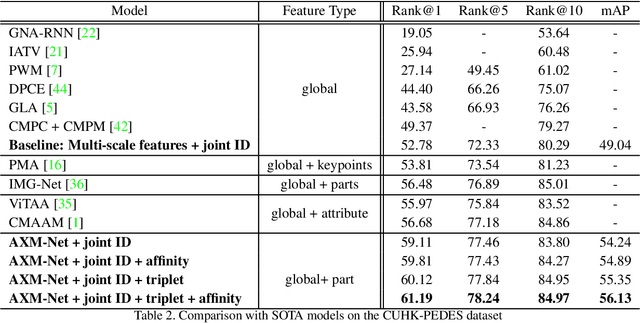
Cross-modal person re-identification (Re-ID) is critical for modern video surveillance systems. The key challenge is to align inter-modality representations according to semantic information present for a person and ignore background information. In this work, we present AXM-Net, a novel CNN based architecture designed for learning semantically aligned visual and textual representations. The underlying building block consists of multiple streams of feature maps coming from visual and textual modalities and a novel learnable context sharing semantic alignment network. We also propose complementary intra modal attention learning mechanisms to focus on more fine-grained local details in the features along with a cross-modal affinity loss for robust feature matching. Our design is unique in its ability to implicitly learn feature alignments from data. The entire AXM-Net can be trained in an end-to-end manner. We report results on both person search and cross-modal Re-ID tasks. Extensive experimentation validates the proposed framework and demonstrates its superiority by outperforming the current state-of-the-art methods by a significant margin.
Separable Batch Normalization for Robust Facial Landmark Localization with Cross-protocol Network Training
Jan 17, 2021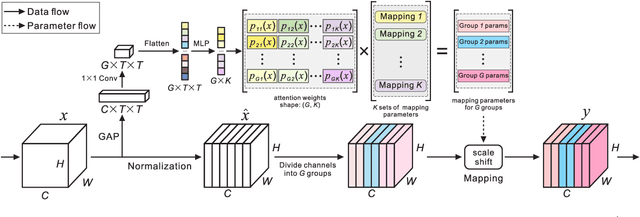
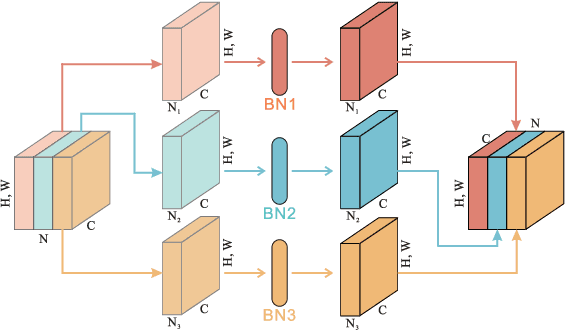
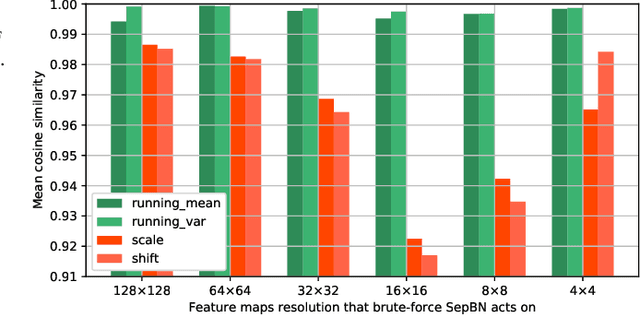
A big, diverse and balanced training data is the key to the success of deep neural network training. However, existing publicly available datasets used in facial landmark localization are usually much smaller than those for other computer vision tasks. A small dataset without diverse and balanced training samples cannot support the training of a deep network effectively. To address the above issues, this paper presents a novel Separable Batch Normalization (SepBN) module with a Cross-protocol Network Training (CNT) strategy for robust facial landmark localization. Different from the standard BN layer that uses all the training data to calculate a single set of parameters, SepBN considers that the samples of a training dataset may belong to different sub-domains. Accordingly, the proposed SepBN module uses multiple sets of parameters, each corresponding to a specific sub-domain. However, the selection of an appropriate branch in the inference stage remains a challenging task because the sub-domain of a test sample is unknown. To mitigate this difficulty, we propose a novel attention mechanism that assigns different weights to each branch for automatic selection in an effective style. As a further innovation, the proposed CNT strategy trains a network using multiple datasets having different facial landmark annotation systems, boosting the performance and enhancing the generalization capacity of the trained network. The experimental results obtained on several well-known datasets demonstrate the effectiveness of the proposed method.
A Flatter Loss for Bias Mitigation in Cross-dataset Facial Age Estimation
Oct 26, 2020
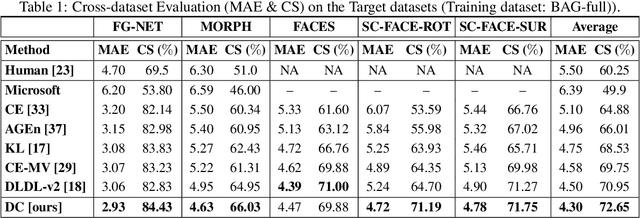
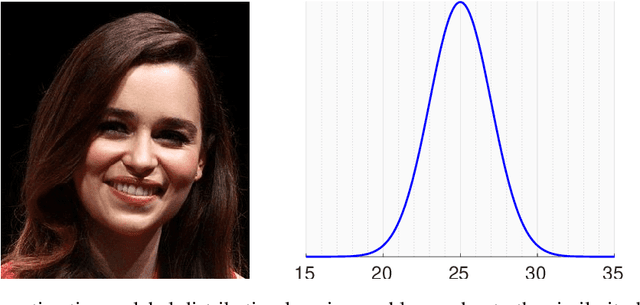
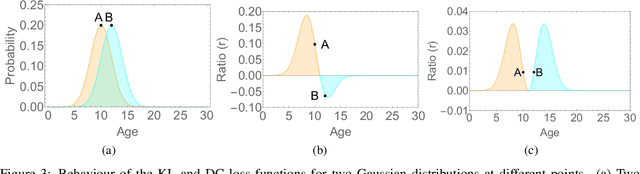
The most existing studies in the facial age estimation assume training and test images are captured under similar shooting conditions. However, this is rarely valid in real-world applications, where training and test sets usually have different characteristics. In this paper, we advocate a cross-dataset protocol for age estimation benchmarking. In order to improve the cross-dataset age estimation performance, we mitigate the inherent bias caused by the learning algorithm itself. To this end, we propose a novel loss function that is more effective for neural network training. The relative smoothness of the proposed loss function is its advantage with regards to the optimisation process performed by stochastic gradient descent (SGD). Compared with existing loss functions, the lower gradient of the proposed loss function leads to the convergence of SGD to a better optimum point, and consequently a better generalisation. The cross-dataset experimental results demonstrate the superiority of the proposed method over the state-of-the-art algorithms in terms of accuracy and generalisation capability.