 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSNet: A Deep Multi-scale Submanifold Network for Visual Classification
Jan 29, 2022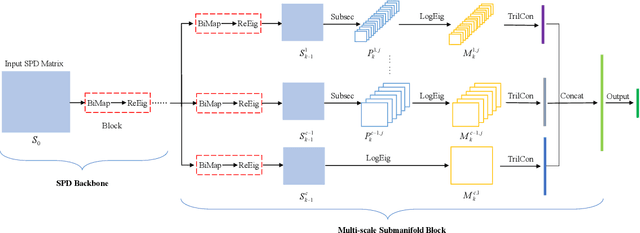
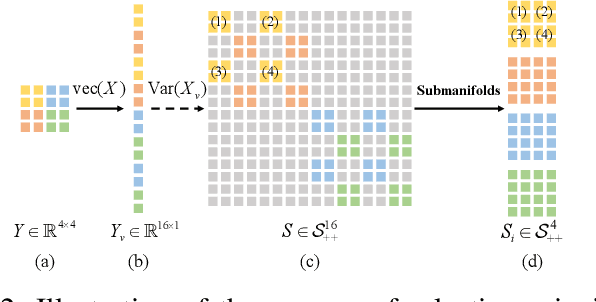


The Symmetric Positive Definite (SPD) matrix has received wide attention as a tool for visual data representation in computer vision. Although there are many different attempts to develop effective deep architectures for data processing on the Riemannian manifold of SPD matrices, a very few solutions explicitly mine the local geometrical information in deep SPD feature representations. While CNNs have demonstrated the potential of hierarchical local pattern extraction even for SPD represented data, we argue that it is of utmost importance to ensure the preservation of local geometric information in the SPD networks. Accordingly, in this work we propose an SPD network designed with this objective in mind. In particular, we propose an architecture, referred to as MSNet, which fuses geometrical multi-scale information. We first analyse the convolution operator commonly used for mapping the local information in Euclidean deep networks from the perspective of a higher level of abstraction afforded by the Category Theory. Based on this analysis, we postulate a submanifold selection principle to guide the design of our MSNet. In particular, we use it to design a submanifold fusion block to take advantage of the rich local geometry encoded in the network layers. The experiments involving multiple visual tasks show that our algorithm outperforms most Riemannian SOTA competitors.
Constrained Structure Learning for Scene Graph Generation
Jan 27, 2022



As a structured prediction task, scene graph generation aims to build a visually-grounded scene graph to explicitly model objects and their relationships in an input image. Currently, the mean field variational Bayesian framework is the de facto methodology used by the existing methods, in which the unconstrained inference step is often implemented by a message passing neural network. However, such formulation fails to explore other inference strategies, and largely ignores the more general constrained optimization models. In this paper, we present a constrained structure learning method, for which an explicit constrained variational inference objective is proposed. Instead of applying the ubiquitous message-passing strategy, a generic constrained optimization method - entropic mirror descent - is utilized to solve the constrained variational inference step. We validate the proposed generic model on various popular scene graph generation benchmarks and show that it outperforms the state-of-the-art methods.
Exploring Fusion Strategies for Accurate RGBT Visual Object Tracking
Jan 21, 2022
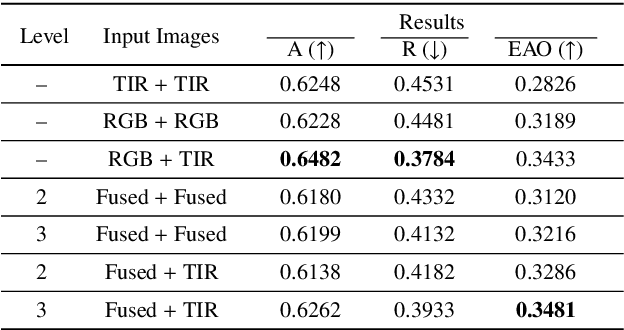
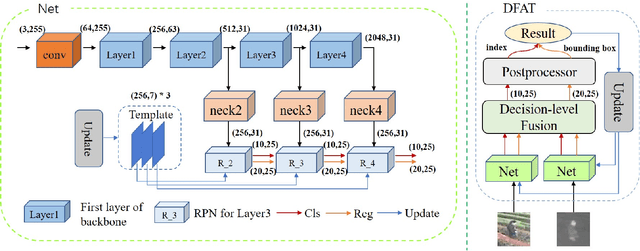
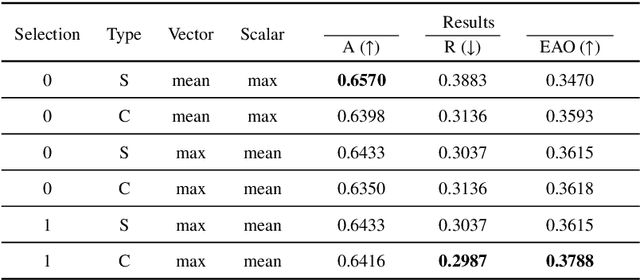
We address the problem of multi-modal object tracking in video and explore various options of fusing the complementary information conveyed by the visible (RGB) and thermal infrared (TIR) modalities including pixel-level, feature-level and decision-level fusion. Specifically, different from the existing methods, paradigm of image fusion task is heeded for fusion at pixel level. Feature-level fusion is fulfilled by attention mechanism with channels excited optionally. Besides, at decision level, a novel fusion strategy is put forward since an effortless averaging configuration has shown the superiority. The effectiveness of the proposed decision-level fusion strategy owes to a number of innovative contributions, including a dynamic weighting of the RGB and TIR contributions and a linear template update operation. A variant of which produced the winning tracker at the Visual Object Tracking Challenge 2020 (VOT-RGBT2020). The concurrent exploration of innovative pixel- and feature-level fusion strategies highlights the advantages of the proposed decision-level fusion method. Extensive experimental results on three challenging datasets, \textit{i.e.}, GTOT, VOT-RGBT2019, and VOT-RGBT2020, demonstrate the effectiveness and robustness of the proposed method, compared to the state-of-the-art approaches. Code will be shared at \textcolor{blue}{\emph{https://github.com/Zhangyong-Tang/DFAT}.
Neural Belief Propagation for Scene Graph Generation
Dec 10, 2021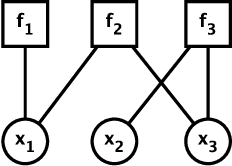
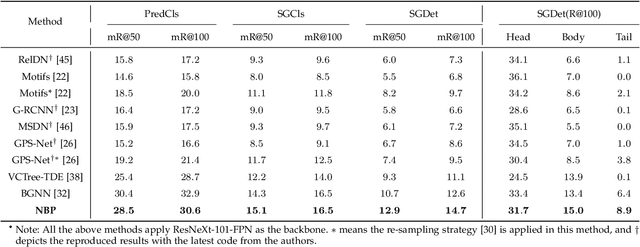
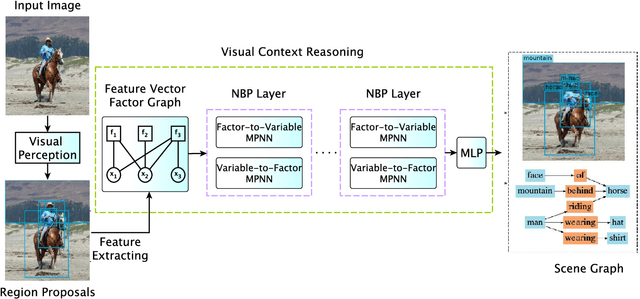
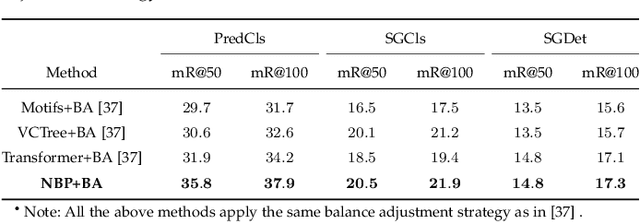
Scene graph generation aims to interpret an input image by explicitly modelling the potential objects and their relationships, which is predominantly solved by the message passing neural network models in previous methods. Currently, such approximation models generally assume the output variables are totally independent and thus ignore the informative structural higher-order interactions. This could lead to the inconsistent interpretations for an input image. In this paper, we propose a novel neural belief propagation method to generate the resulting scene graph. It employs a structural Bethe approximation rather than the mean field approximation to infer the associated marginals. To find a better bias-variance trade-off, the proposed model not only incorporates pairwise interactions but also higher order interactions into the associated scoring function. It achieves the state-of-the-art performance on various popular scene graph generation benchmarks.
MC-SSL0.0: Towards Multi-Concept Self-Supervised Learning
Nov 30, 2021
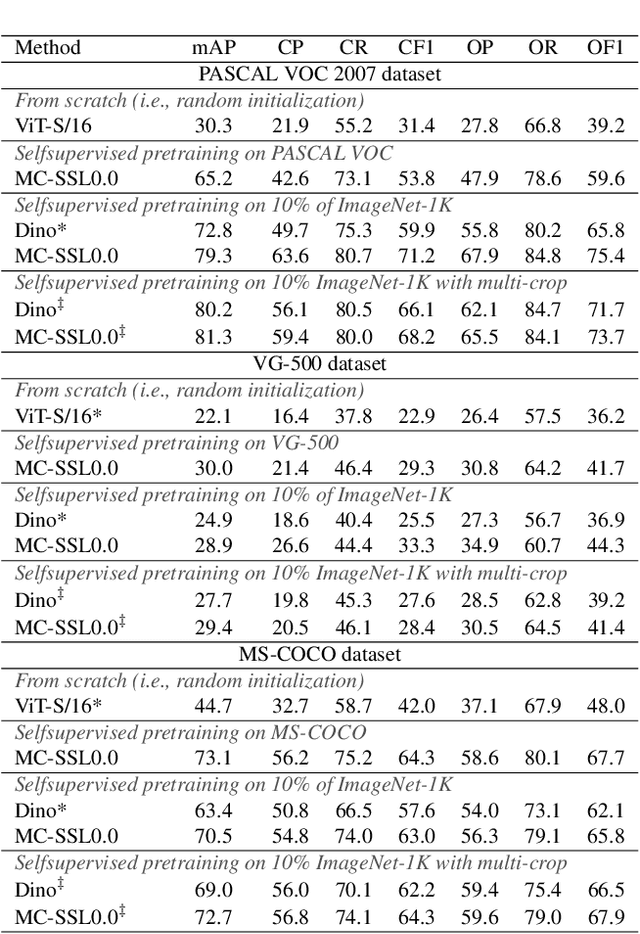
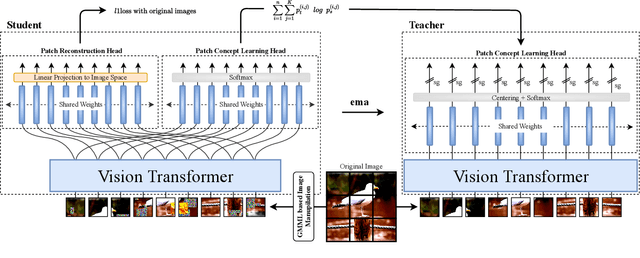
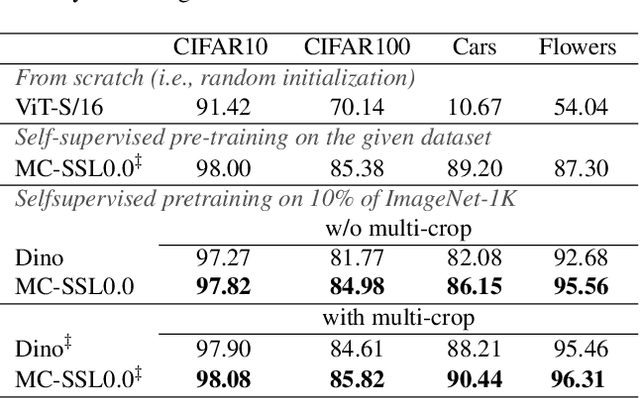
Self-supervised pretraining is the method of choice for natural language processing models and is rapidly gaining popularity in many vision tasks. Recently, self-supervised pretraining has shown to outperform supervised pretraining for many downstream vision applications, marking a milestone in the area. This superiority is attributed to the negative impact of incomplete labelling of the training images, which convey multiple concepts, but are annotated using a single dominant class label. Although Self-Supervised Learning (SSL), in principle, is free of this limitation, the choice of pretext task facilitating SSL is perpetuating this shortcoming by driving the learning process towards a single concept output. This study aims to investigate the possibility of modelling all the concepts present in an image without using labels. In this aspect the proposed SSL frame-work MC-SSL0.0 is a step towards Multi-Concept Self-Supervised Learning (MC-SSL) that goes beyond modelling single dominant label in an image to effectively utilise the information from all the concepts present in it. MC-SSL0.0 consists of two core design concepts, group masked model learning and learning of pseudo-concept for data token using a momentum encoder (teacher-student) framework. The experimental results on multi-label and multi-class image classification downstream tasks demonstrate that MC-SSL0.0 not only surpasses existing SSL methods but also outperforms supervised transfer learning. The source code will be made publicly available for community to train on bigger corpus.
Global Interaction Modelling in Vision Transformer via Super Tokens
Nov 25, 2021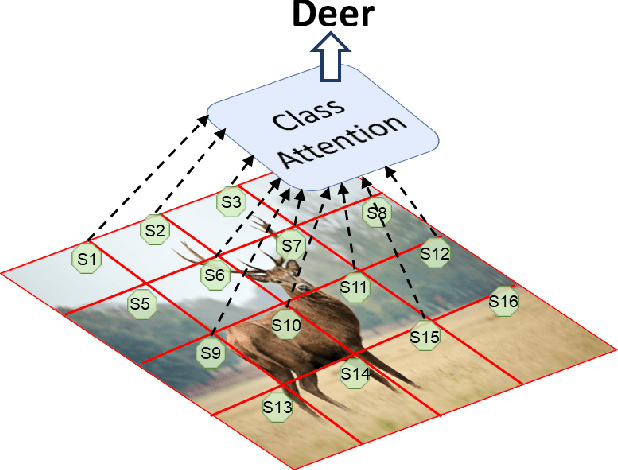
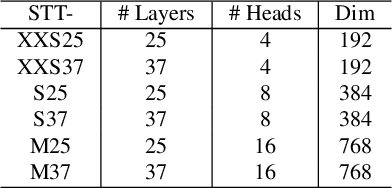
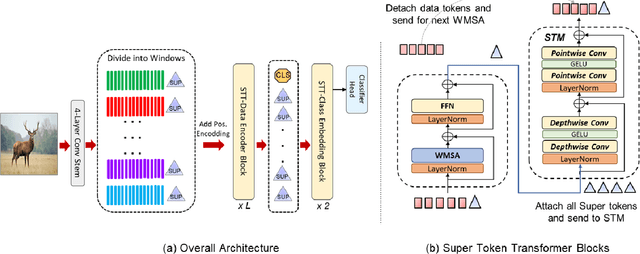
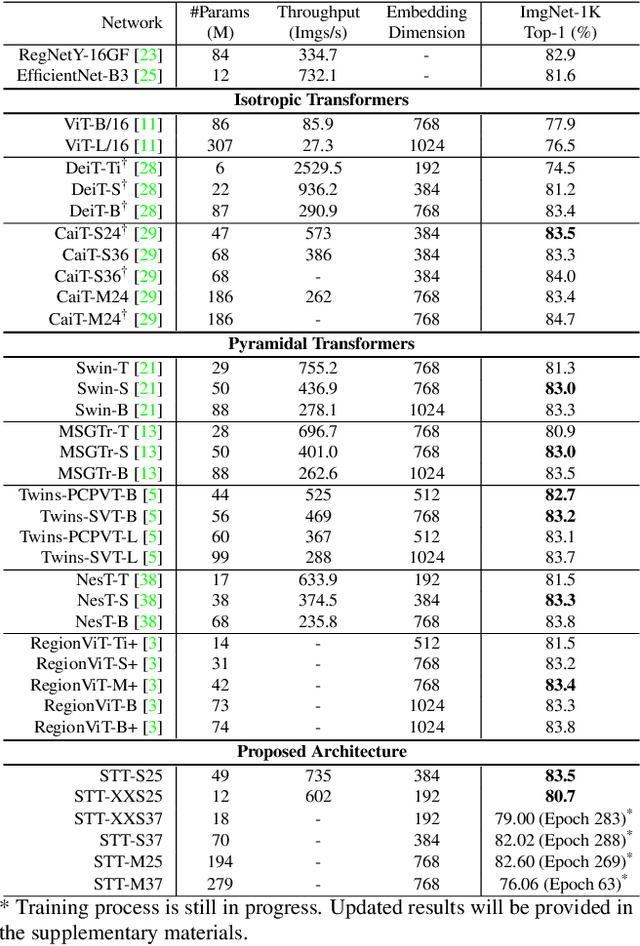
With the popularity of Transformer architectures in computer vision, the research focus has shifted towards developing computationally efficient designs. Window-based local attention is one of the major techniques being adopted in recent works. These methods begin with very small patch size and small embedding dimensions and then perform strided convolution (patch merging) in order to reduce the feature map size and increase embedding dimensions, hence, forming a pyramidal Convolutional Neural Network (CNN) like design. In this work, we investigate local and global information modelling in transformers by presenting a novel isotropic architecture that adopts local windows and special tokens, called Super tokens, for self-attention. Specifically, a single Super token is assigned to each image window which captures the rich local details for that window. These tokens are then employed for cross-window communication and global representation learning. Hence, most of the learning is independent of the image patches $(N)$ in the higher layers, and the class embedding is learned solely based on the Super tokens $(N/M^2)$ where $M^2$ is the window size. In standard image classification on Imagenet-1K, the proposed Super tokens based transformer (STT-S25) achieves 83.5\% accuracy which is equivalent to Swin transformer (Swin-B) with circa half the number of parameters (49M) and double the inference time throughput. The proposed Super token transformer offers a lightweight and promising backbone for visual recognition tasks.
The Multiscenario Multienvironment BioSecure Multimodal Database (BMDB)
Nov 17, 2021

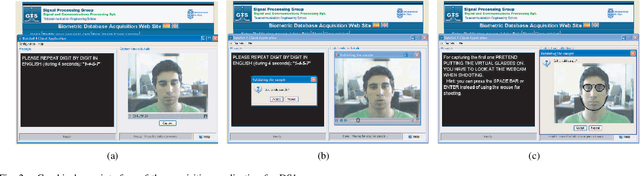

A new multimodal biometric database designed and acquired within the framework of the European BioSecure Network of Excellence is presented. It is comprised of more than 600 individuals acquired simultaneously in three scenarios: 1) over the Internet, 2) in an office environment with desktop PC, and 3) in indoor/outdoor environments with mobile portable hardware. The three scenarios include a common part of audio/video data. Also, signature and fingerprint data have been acquired both with desktop PC and mobile portable hardware. Additionally, hand and iris data were acquired in the second scenario using desktop PC. Acquisition has been conducted by 11 European institutions. Additional features of the BioSecure Multimodal Database (BMDB) are: two acquisition sessions, several sensors in certain modalities, balanced gender and age distributions, multimodal realistic scenarios with simple and quick tasks per modality, cross-European diversity, availability of demographic data, and compatibility with other multimodal databases. The novel acquisition conditions of the BMDB allow us to perform new challenging research and evaluation of either monomodal or multimodal biometric systems, as in the recent BioSecure Multimodal Evaluation campaign. A description of this campaign including baseline results of individual modalities from the new database is also given. The database is expected to be available for research purposes through the BioSecure Association during 2008
Benchmarking Quality-Dependent and Cost-Sensitive Score-Level Multimodal Biometric Fusion Algorithms
Nov 17, 2021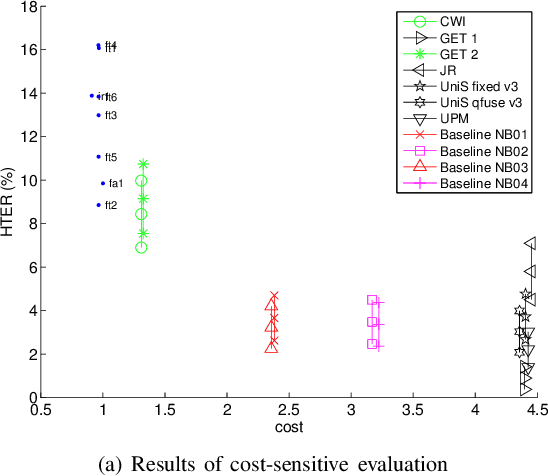
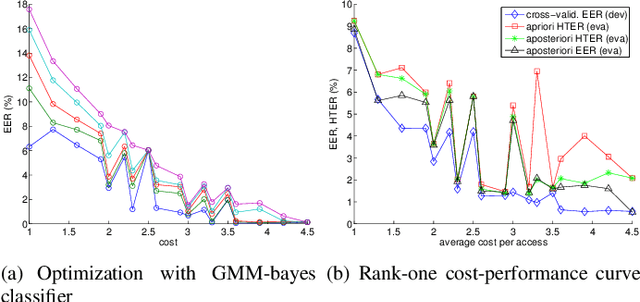
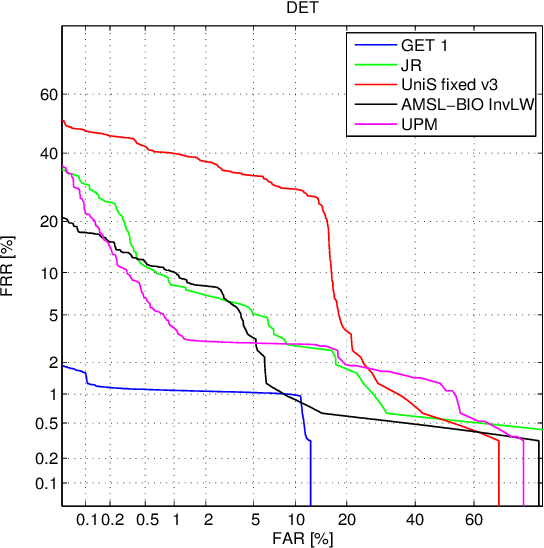
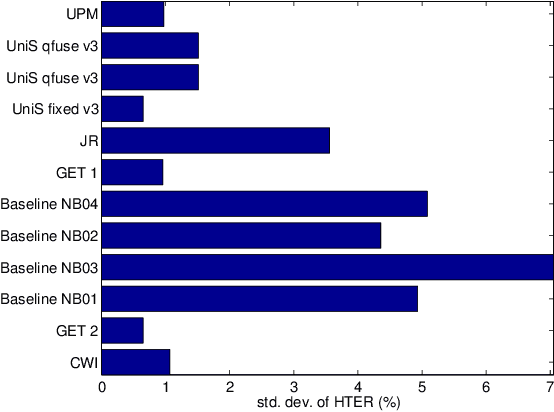
Automatically verifying the identity of a person by means of biometrics is an important application in day-to-day activities such as accessing banking services and security control in airports. To increase the system reliability, several biometric devices are often used. Such a combined system is known as a multimodal biometric system. This paper reports a benchmarking study carried out within the framework of the BioSecure DS2 (Access Control) evaluation campaign organized by the University of Surrey, involving face, fingerprint, and iris biometrics for person authentication, targeting the application of physical access control in a medium-size establishment with some 500 persons. While multimodal biometrics is a well-investigated subject, there exists no benchmark for a fusion algorithm comparison. Working towards this goal, we designed two sets of experiments: quality-dependent and cost-sensitive evaluation. The quality-dependent evaluation aims at assessing how well fusion algorithms can perform under changing quality of raw images principally due to change of devices. The cost-sensitive evaluation, on the other hand, investigates how well a fusion algorithm can perform given restricted computation and in the presence of software and hardware failures, resulting in errors such as failure-to-acquire and failure-to-match. Since multiple capturing devices are available, a fusion algorithm should be able to handle this nonideal but nevertheless realistic scenario. In both evaluations, each fusion algorithm is provided with scores from each biometric comparison subsystem as well as the quality measures of both template and query data. The response to the call of the campaign proved very encouraging, with the submission of 22 fusion systems. To the best of our knowledge, this is the first attempt to benchmark quality-based multimodal fusion algorithms.
Video Is Graph: Structured Graph Module for Video Action Recognition
Oct 12, 2021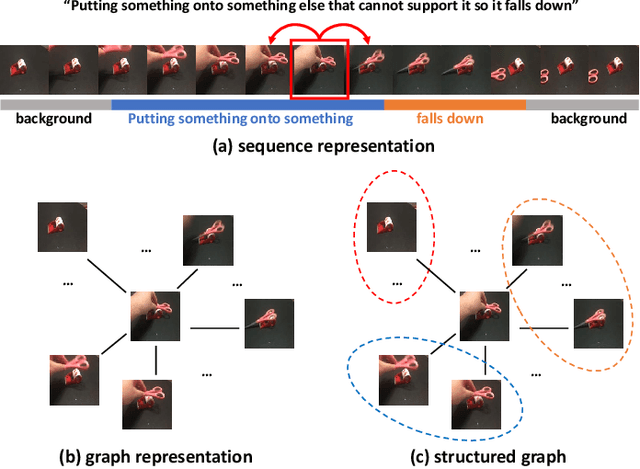
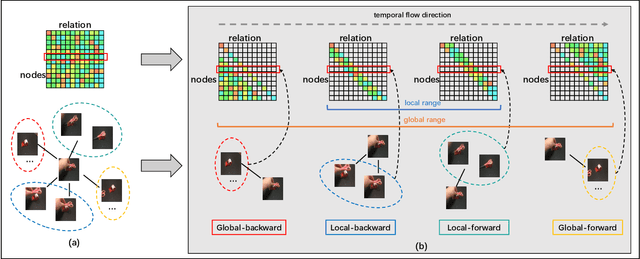
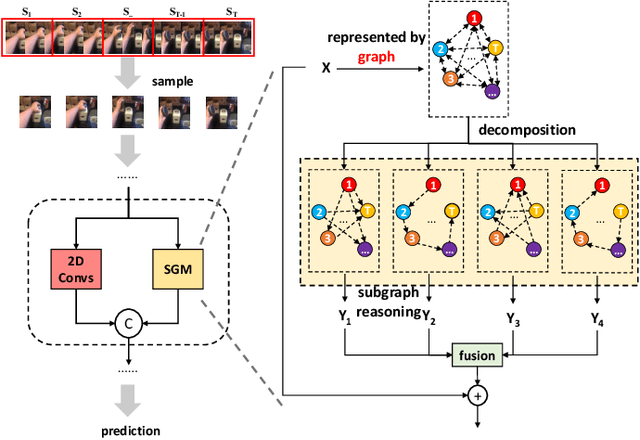

In the field of action recognition, video clips are always treated as ordered frames for subsequent processing. To achieve spatio-temporal perception, existing approaches propose to embed adjacent temporal interaction in the convolutional layer. The global semantic information can therefore be obtained by stacking multiple local layers hierarchically. However, such global temporal accumulation can only reflect the high-level semantics in deep layers, neglecting the potential low-level holistic clues in shallow layers. In this paper, we first propose to transform a video sequence into a graph to obtain direct long-term dependencies among temporal frames. To preserve sequential information during transformation, we devise a structured graph module (SGM), achieving fine-grained temporal interactions throughout the entire network. In particular, SGM divides the neighbors of each node into several temporal regions so as to extract global structural information with diverse sequential flows. Extensive experiments are performed on standard benchmark datasets, i.e., Something-Something V1 & V2, Diving48, Kinetics-400, UCF101, and HMDB51. The reported performance and analysis demonstrate that SGM can achieve outstanding precision with less computational complexity.
Learning PAC-Bayes Priors for Probabilistic Neural Networks
Sep 21, 2021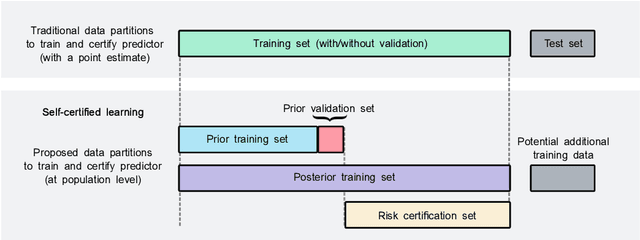
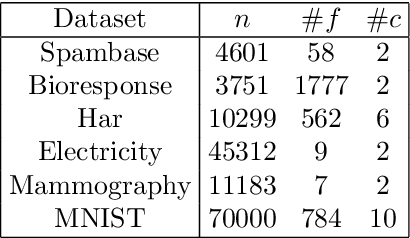
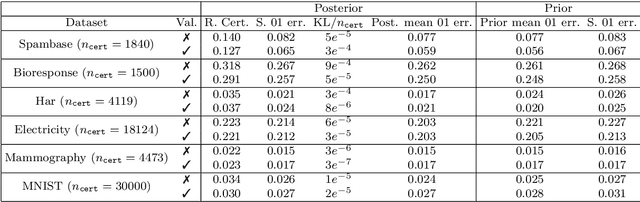
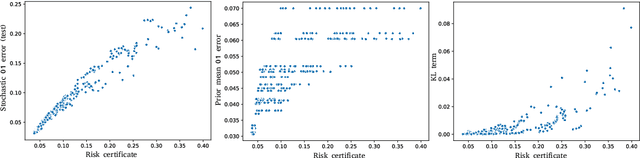
Recent works have investigated deep learning models trained by optimising PAC-Bayes bounds, with priors that are learnt on subsets of the data. This combination has been shown to lead not only to accurate classifiers, but also to remarkably tight risk certificates, bearing promise towards self-certified learning (i.e. use all the data to learn a predictor and certify its quality). In this work, we empirically investigate the role of the prior. We experiment on 6 datasets with different strategies and amounts of data to learn data-dependent PAC-Bayes priors, and we compare them in terms of their effect on test performance of the learnt predictors and tightness of their risk certificate. We ask what is the optimal amount of data which should be allocated for building the prior and show that the optimum may be dataset dependent. We demonstrate that using a small percentage of the prior-building data for validation of the prior leads to promising results. We include a comparison of underparameterised and overparameterised models, along with an empirical study of different training objectives and regularisation strategies to learn the prior distribution.