 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU Acceleration of Sparse Fully Homomorphic Encrypted DNNs
Apr 13, 2026Fully homomorphic encryption (FHE) has recently attracted significant attention as both a cryptographic primitive and a systems challenge. Given the latest advances in accelerated computing, FHE presents a promising opportunity for progress, with applications ranging from machine learning to information security. We target the most computationally intensive operation in deep neural networks from a hardware perspective, matrix multiplication (matmul), and adapt it for execution on AMD GPUs. We propose a new optimized method that improves the runtime and complexity of ciphertext matmul by using FIDESlib, a recent open-source FHE library designed specifically for GPUs. By exploiting sparsity in both operands, our sparse matmul implementation outperforms its CPU counterpart by up to $3.0\times$ and reduces the time complexity from cubic to semi-linear, demonstrating an improvement over existing FHE matmul implementations.
STONNE: A Detailed Architectural Simulator for Flexible Neural Network Accelerators
Jun 10, 2020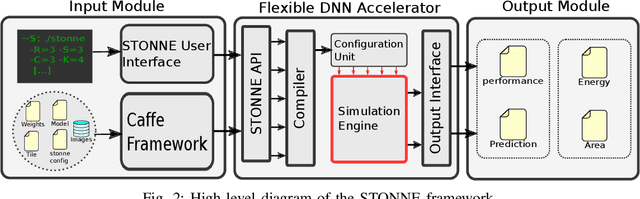
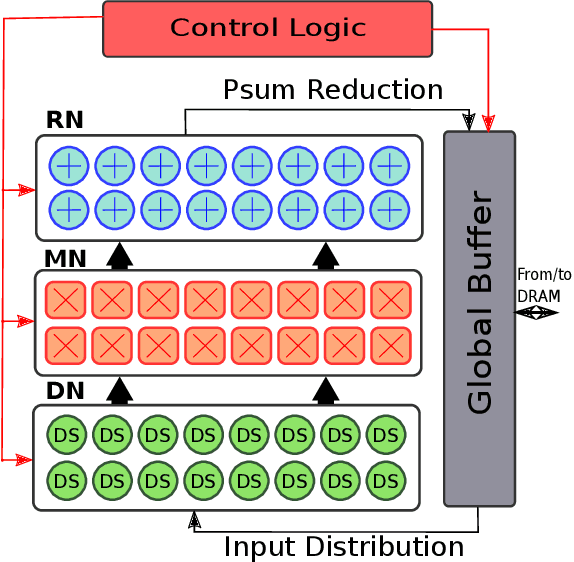
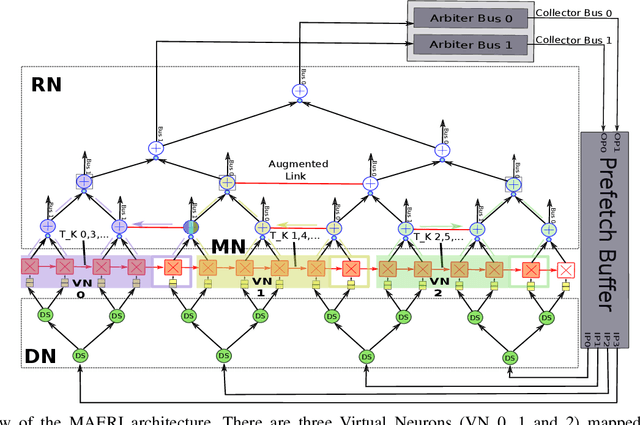
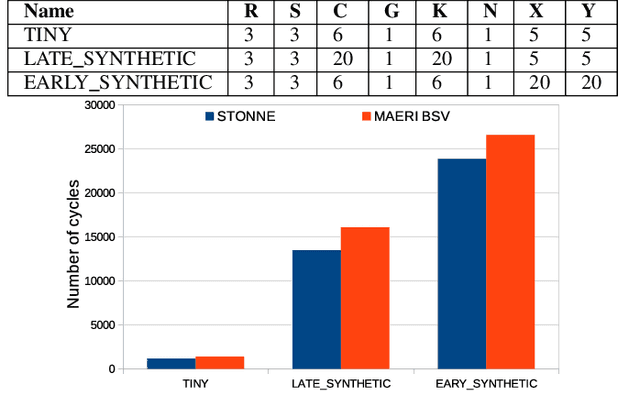
The design of specialized architectures for accelerating the inference procedure of Deep Neural Networks (DNNs) is a booming area of research nowadays. First-generation rigid proposals have been rapidly replaced by more advanced flexible accelerator architectures able to efficiently support a variety of layer types and dimensions. As the complexity of the designs grows, it is more and more appealing for researchers to have cycle-accurate simulation tools at their disposal to allow for fast and accurate design-space exploration, and rapid quantification of the efficacy of architectural enhancements during the early stages of a design. To this end, we present STONNE (Simulation TOol of Neural Network Engines), a cycle-accurate, highly-modular and highly-extensible simulation framework that enables end-to-end evaluation of flexible accelerator architectures running complete contemporary DNN models. We use STONNE to model the recently proposed MAERI architecture and show how it can closely approach the performance results of the publicly available BSV-coded MAERI implementation. Then, we conduct a comprehensive evaluation and demonstrate that the folding strategy implemented for MAERI results in very low compute unit utilization (25% on average across 5 DNN models) which in the end translates into poor performance.