 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exact Bitwise Reversible Integrator
Jul 15, 2022

At a fundamental level most physical equations are time reversible. In this paper we propose an integrator that preserves this property at the discrete computational level. Our simulations can be run forward and backwards and trace the same path exactly bitwise. We achieve this by implementing theoretically reversible integrators using a mix of fixed and floating point arithmetic. Our main application is in efficiently implementing the reverse step in the adjoint method used in optimization. Our integrator has applications in differential simulations and machine learning (backpropagation).
Ultrahyperbolic Representation Learning
Jul 01, 2020

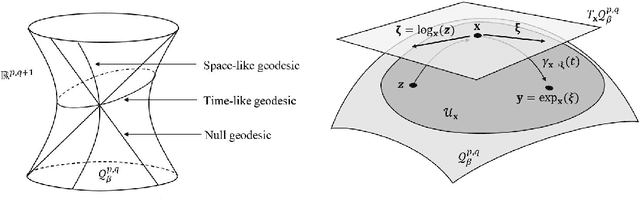
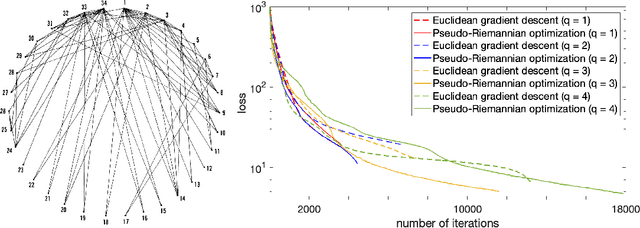
In machine learning, data is usually represented in a (flat) Euclidean space where distances between points are along straight lines. Researchers have recently considered more exotic (non-Euclidean) Riemannian manifolds such as hyperbolic space which is well suited for tree-like data. In this paper, we propose a representation living on a pseudo-Riemannian manifold with constant nonzero curvature. It is a generalization of hyperbolic and spherical geometries where the nondegenerate metric tensor is not positive definite. We provide the necessary learning tools in this geometry and extend gradient method optimization techniques. More specifically, we provide closed-form expressions for distances via geodesics and define a descent direction that guarantees the minimization of the objective problem. Our novel framework is applied to graph representations.
Computing Light Transport Gradients using the Adjoint Method
Jun 26, 2020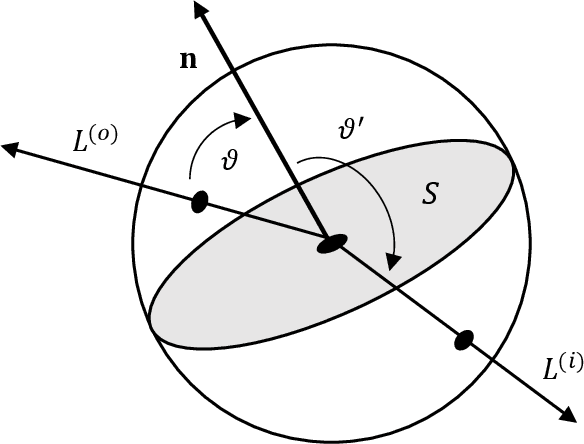
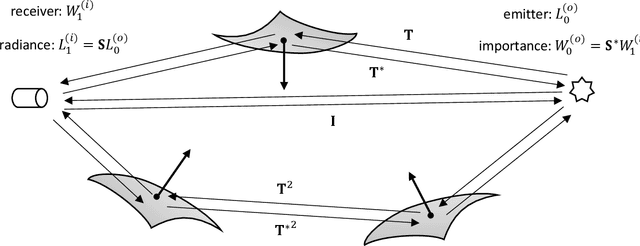
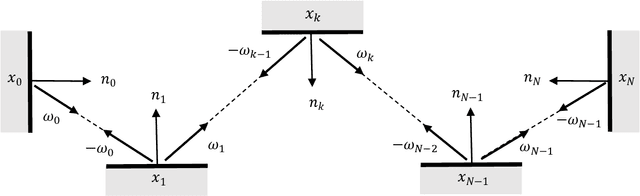
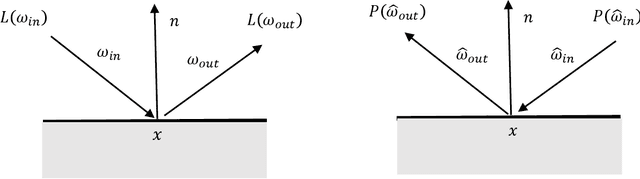
This paper proposes a new equation from continuous adjoint theory to compute the gradient of quantities governed by the Transport Theory of light. Unlike discrete gradients ala autograd, which work at the code level, we first formulate the continuous theory and then discretize it. The key insight of this paper is that computing gradients in Transport Theory is akin to computing the importance, a quantity adjoint to radiance that satisfies an adjoint equation. Importance tells us where to look for light that matters. This is one of the key insights of this paper. In fact, this mathematical journey started from a whimsical thought that these adjoints might be related. Computing gradients is therefore no more complicated than computing the importance field. This insight and the following paper hopefully will shed some light on this complicated problem and ease the implementations of gradient computations in existing path tracers.