 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Image-to-Point Distillation via Semantically Tolerant Contrastive Loss
Jan 12, 2023



An effective framework for learning 3D representations for perception tasks is distilling rich self-supervised image features via contrastive learning. However, image-to point representation learning for autonomous driving datasets faces two main challenges: 1) the abundance of self-similarity, which results in the contrastive losses pushing away semantically similar point and image regions and thus disturbing the local semantic structure of the learned representations, and 2) severe class imbalance as pretraining gets dominated by over-represented classes. We propose to alleviate the self-similarity problem through a novel semantically tolerant image-to-point contrastive loss that takes into consideration the semantic distance between positive and negative image regions to minimize contrasting semantically similar point and image regions. Additionally, we address class imbalance by designing a class-agnostic balanced loss that approximates the degree of class imbalance through an aggregate sample-to-samples semantic similarity measure. We demonstrate that our semantically-tolerant contrastive loss with class balancing improves state-of-the art 2D-to-3D representation learning in all evaluation settings on 3D semantic segmentation. Our method consistently outperforms state-of-the-art 2D-to-3D representation learning frameworks across a wide range of 2D self-supervised pretrained models.
Point Density-Aware Voxels for LiDAR 3D Object Detection
Mar 22, 2022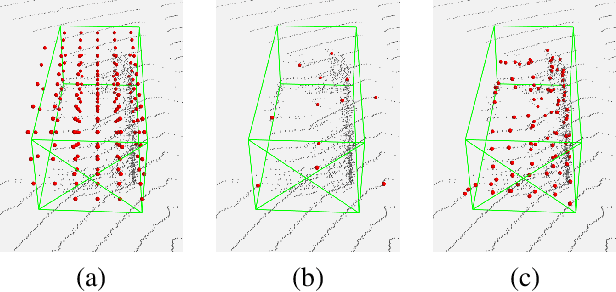
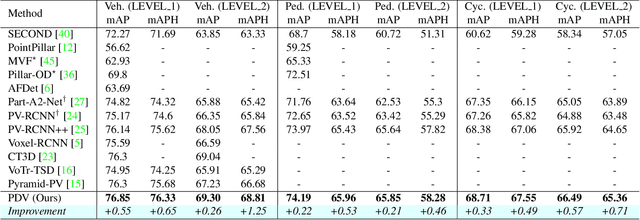
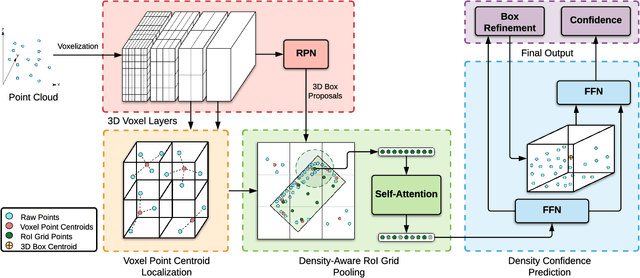
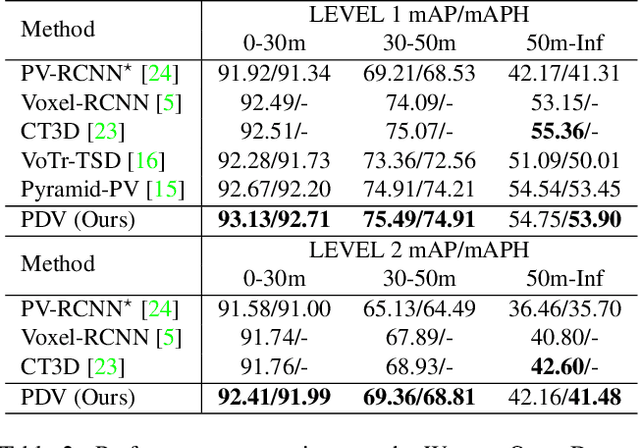
LiDAR has become one of the primary 3D object detection sensors in autonomous driving. However, LiDAR's diverging point pattern with increasing distance results in a non-uniform sampled point cloud ill-suited to discretized volumetric feature extraction. Current methods either rely on voxelized point clouds or use inefficient farthest point sampling to mitigate detrimental effects caused by density variation but largely ignore point density as a feature and its predictable relationship with distance from the LiDAR sensor. Our proposed solution, Point Density-Aware Voxel network (PDV), is an end-to-end two stage LiDAR 3D object detection architecture that is designed to account for these point density variations. PDV efficiently localizes voxel features from the 3D sparse convolution backbone through voxel point centroids. The spatially localized voxel features are then aggregated through a density-aware RoI grid pooling module using kernel density estimation (KDE) and self-attention with point density positional encoding. Finally, we exploit LiDAR's point density to distance relationship to refine our final bounding box confidences. PDV outperforms all state-of-the-art methods on the Waymo Open Dataset and achieves competitive results on the KITTI dataset. We provide a code release for PDV which is available at https://github.com/TRAILab/PDV.
Dense Voxel Fusion for 3D Object Detection
Mar 02, 2022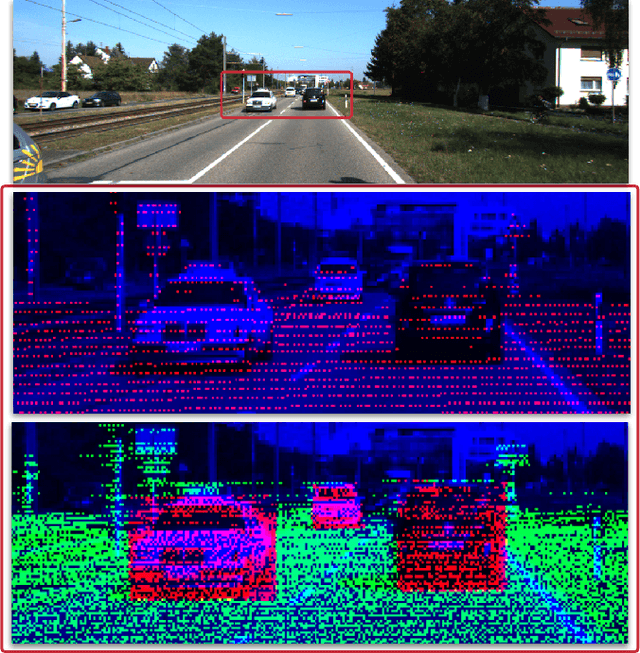
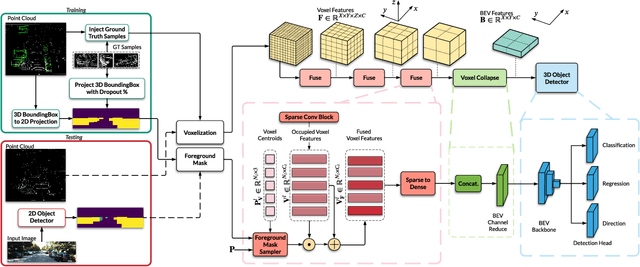
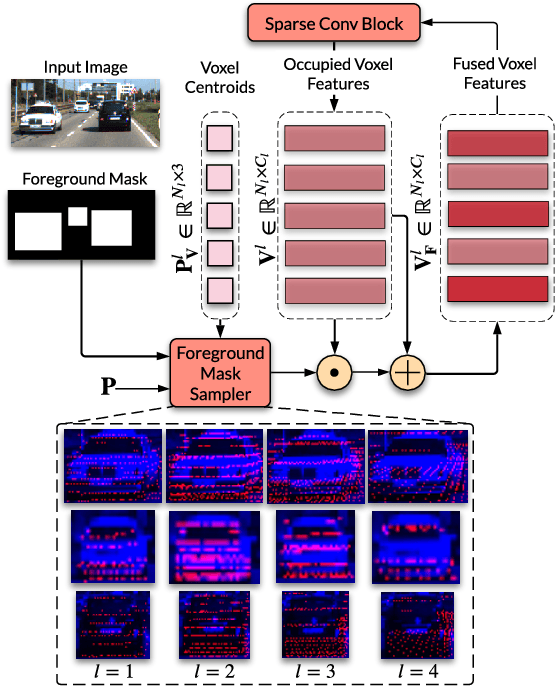
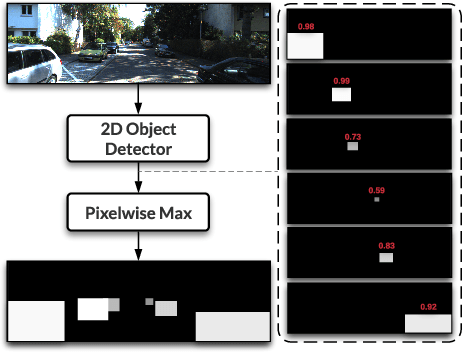
Camera and LiDAR sensor modalities provide complementary appearance and geometric information useful for detecting 3D objects for autonomous vehicle applications. However, current fusion models underperform state-of-art LiDAR-only methods on 3D object detection benchmarks. Our proposed solution, Dense Voxel Fusion (DVF) is a sequential fusion method that generates multi-scale multi-modal dense voxel feature representations, improving expressiveness in low point density regions. To enhance multi-modal learning, we train directly with ground truth 2D bounding box labels, avoiding noisy, detector-specific, 2D predictions. Additionally, we use LiDAR ground truth sampling to simulate missed 2D detections and to accelerate training convergence. Both DVF and the multi-modal training approaches can be applied to any voxel-based LiDAR backbone without introducing additional learnable parameters. DVF outperforms existing sparse fusion detectors, ranking $1^{st}$ among all published fusion methods on KITTI's 3D car detection benchmark at the time of submission and significantly improves 3D vehicle detection performance of voxel-based methods on the Waymo Open Dataset. We also show that our proposed multi-modal training strategy results in better generalization compared to training using erroneous 2D predictions.
Pattern-Aware Data Augmentation for LiDAR 3D Object Detection
Nov 30, 2021



Autonomous driving datasets are often skewed and in particular, lack training data for objects at farther distances from the ego vehicle. The imbalance of data causes a performance degradation as the distance of the detected objects increases. In this paper, we propose pattern-aware ground truth sampling, a data augmentation technique that downsamples an object's point cloud based on the LiDAR's characteristics. Specifically, we mimic the natural diverging point pattern variation that occurs for objects at depth to simulate samples at farther distances. Thus, the network has more diverse training examples and can generalize to detecting farther objects more effectively. We evaluate against existing data augmentation techniques that use point removal or perturbation methods and find that our method outperforms all of them. Additionally, we propose using equal element AP bins to evaluate the performance of 3D object detectors across distance. We improve the performance of PV-RCNN on the car class by more than 0.7 percent on the KITTI validation split at distances greater than 25 m.
* Published paper in the IEEE Intelligent Transportation Systems Conference - ITSC 2021