 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDDA: Explanation-driven Data Augmentation to Improve Model and Explanation Alignment
Jun 19, 2021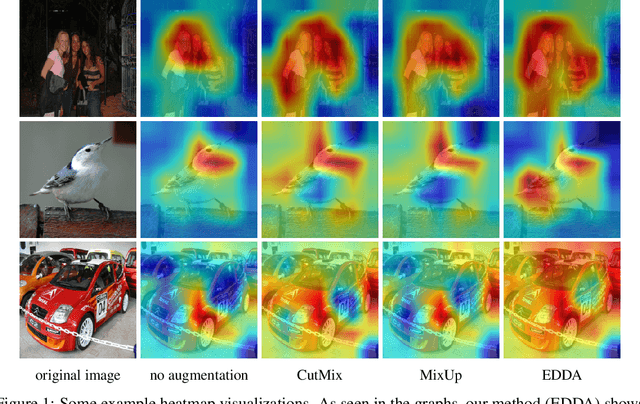
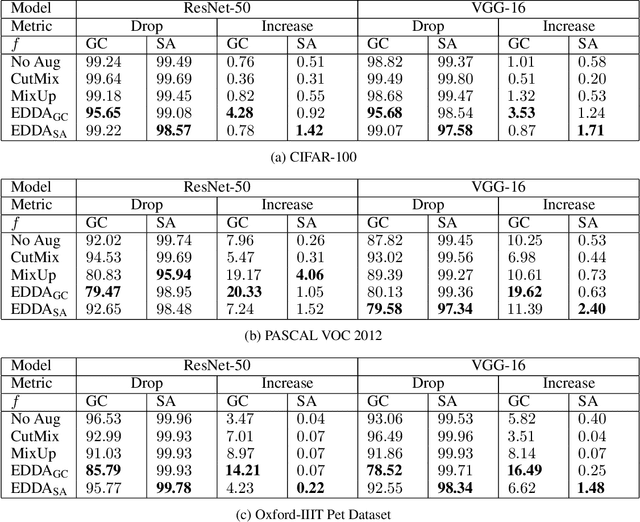
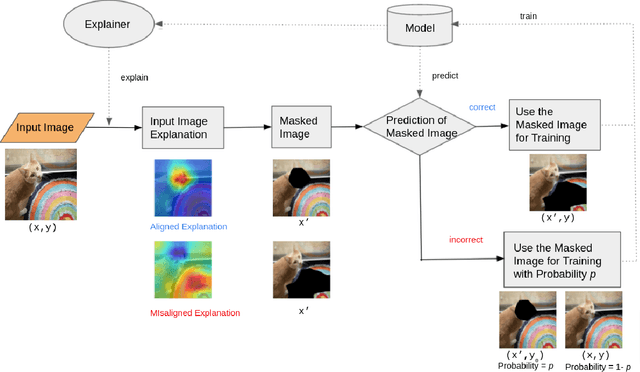
Recent years have seen the introduction of a range of methods for post-hoc explainability of image classifier predictions. However, these post-hoc explanations may not always align perfectly with classifier predictions, which poses a significant challenge when attempting to debug models based on such explanations. To this end, we seek a methodology that can improve alignment between model predictions and explanation method that is both agnostic to the model and explanation classes and which does not require ground truth explanations. We achieve this through a novel explanation-driven data augmentation (EDDA) method that augments the training data with occlusions of existing data stemming from model-explanations; this is based on the simple motivating principle that occluding salient regions for the model prediction should decrease the model confidence in the prediction, while occluding non-salient regions should not change the prediction -- if the model and explainer are aligned. To verify that this augmentation method improves model and explainer alignment, we evaluate the methodology on a variety of datasets, image classification models, and explanation methods. We verify in all cases that our explanation-driven data augmentation method improves alignment of the model and explanation in comparison to no data augmentation and non-explanation driven data augmentation methods. In conclusion, this approach provides a novel model- and explainer-agnostic methodology for improving alignment between model predictions and explanations, which we see as a critical step forward for practical deployment and debugging of image classification models.
Integrated Grad-CAM: Sensitivity-Aware Visual Explanation of Deep Convolutional Networks via Integrated Gradient-Based Scoring
Feb 15, 2021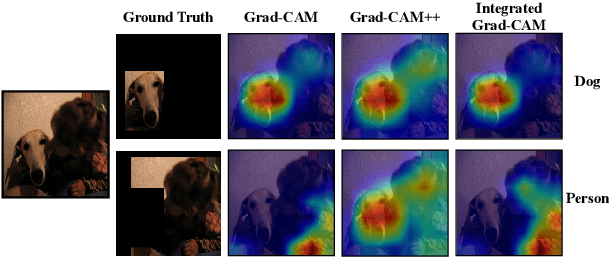
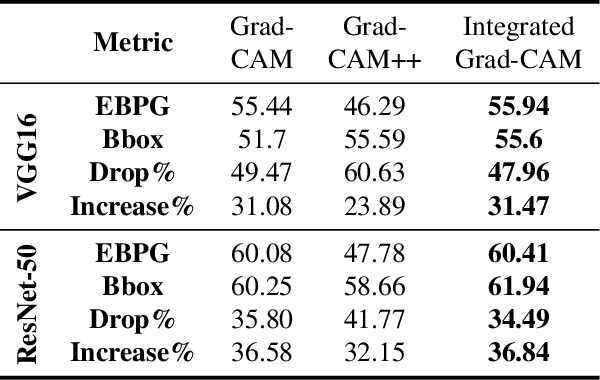

Visualizing the features captured by Convolutional Neural Networks (CNNs) is one of the conventional approaches to interpret the predictions made by these models in numerous image recognition applications. Grad-CAM is a popular solution that provides such a visualization by combining the activation maps obtained from the model. However, the average gradient-based terms deployed in this method underestimates the contribution of the representations discovered by the model to its predictions. Addressing this problem, we introduce a solution to tackle this issue by computing the path integral of the gradient-based terms in Grad-CAM. We conduct a thorough analysis to demonstrate the improvement achieved by our method in measuring the importance of the extracted representations for the CNN's predictions, which yields to our method's administration in object localization and model interpretation.
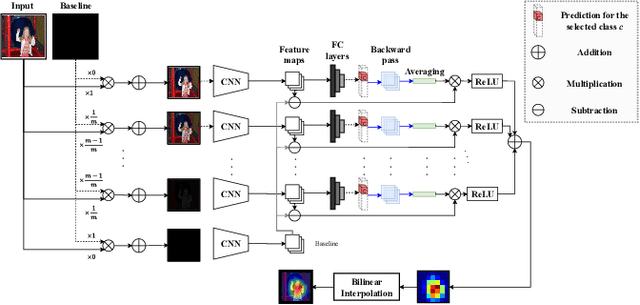
Ada-SISE: Adaptive Semantic Input Sampling for Efficient Explanation of Convolutional Neural Networks
Feb 15, 2021
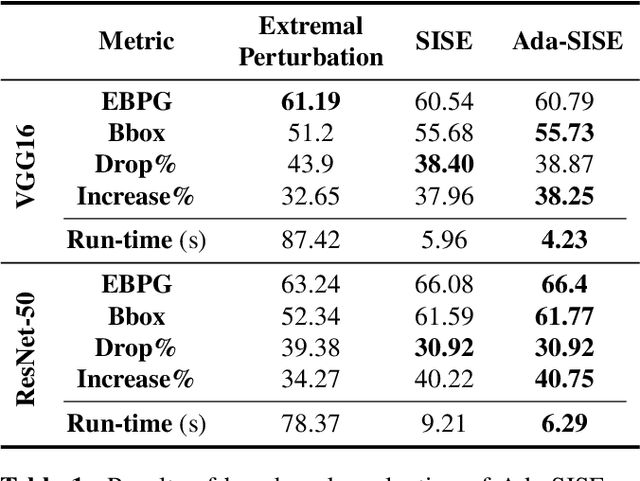
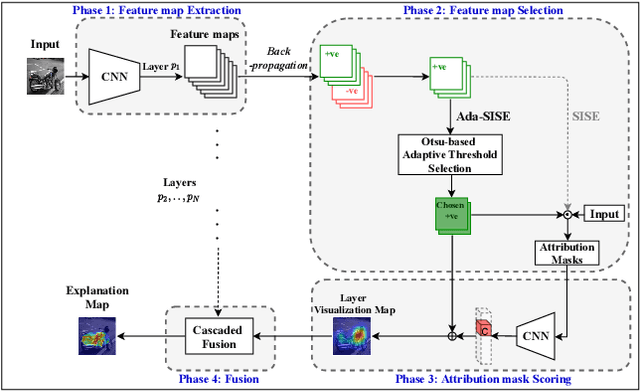

Explainable AI (XAI) is an active research area to interpret a neural network's decision by ensuring transparency and trust in the task-specified learned models. Recently, perturbation-based model analysis has shown better interpretation, but backpropagation techniques are still prevailing because of their computational efficiency. In this work, we combine both approaches as a hybrid visual explanation algorithm and propose an efficient interpretation method for convolutional neural networks. Our method adaptively selects the most critical features that mainly contribute towards a prediction to probe the model by finding the activated features. Experimental results show that the proposed method can reduce the execution time up to 30% while enhancing competitive interpretability without compromising the quality of explanation generated.
Explaining Convolutional Neural Networks through Attribution-Based Input Sampling and Block-Wise Feature Aggregation
Oct 01, 2020
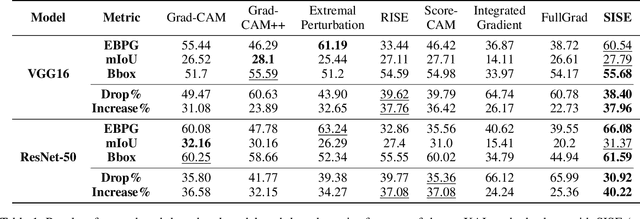
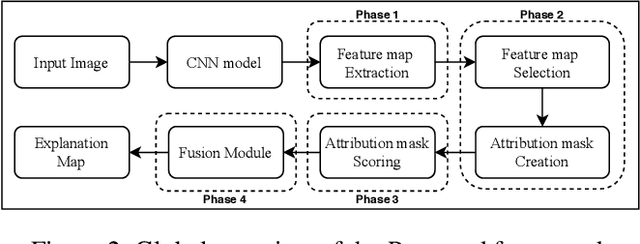
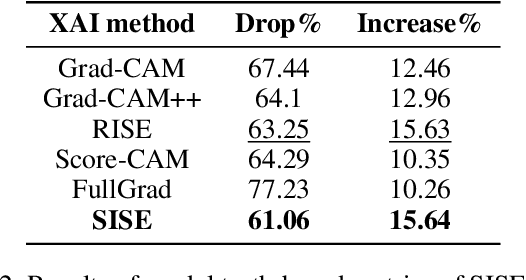
As an emerging field in Machine Learning, Explainable AI (XAI) has been offering remarkable performance in interpreting the decisions made by Convolutional Neural Networks (CNNs). To achieve visual explanations for CNNs, methods based on class activation mapping and randomized input sampling have gained great popularity. However, the attribution methods based on these techniques provide lower resolution and blurry explanation maps that limit their explanation power. To circumvent this issue, visualization based on various layers is sought. In this work, we collect visualization maps from multiple layers of the model based on an attribution-based input sampling technique and aggregate them to reach a fine-grained and complete explanation. We also propose a layer selection strategy that applies to the whole family of CNN-based models, based on which our extraction framework is applied to visualize the last layers of each convolutional block of the model. Moreover, we perform an empirical analysis of the efficacy of derived lower-level information to enhance the represented attributions. Comprehensive experiments conducted on shallow and deep models trained on natural and industrial datasets, using both ground-truth and model-truth based evaluation metrics validate our proposed algorithm by meeting or outperforming the state-of-the-art methods in terms of explanation ability and visual quality, demonstrating that our method shows stability regardless of the size of objects or instances to be explained.
Adversarial Shapley Value Experience Replay for Task-Free Continual Learning
Aug 31, 2020
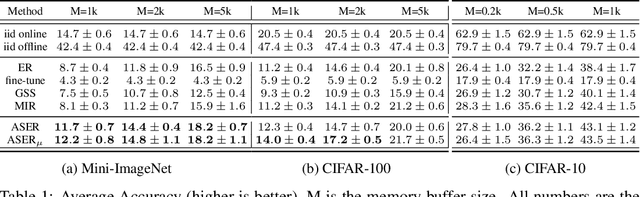
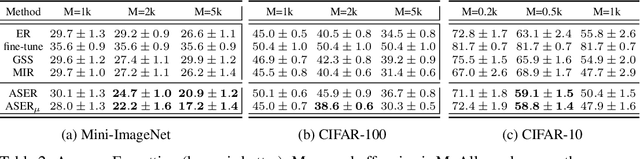
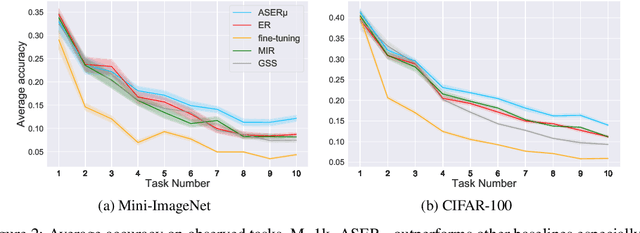
Continual learning is a branch of deep learning that seeks to strike a balance between learning stability and plasticity. In this paper, we specifically focus on the task-free setting where data are streamed online without task metadata and clear task boundaries. A simple and highly effective algorithm class for this setting is known as Experience Replay (ER) that selectively stores data samples from previous experience and leverages them to interleave memory-based and online batch learning updates. Recent advances in ER have proposed novel methods for scoring which samples to store in memory and which memory samples to interleave with online data during learning updates. In this paper, we contribute a novel Adversarial Shapley value ER (ASER) method that scores memory data samples according to their ability to preserve latent decision boundaries for previously observed classes (to maintain learning stability and avoid forgetting) while interfering with latent decision boundaries of current classes being learned (to encourage plasticity and optimal learning of new class boundaries). Overall, we observe that ASER provides competitive or improved performance on a variety of datasets compared to state-of-the-art ER-based continual learning methods.
Propagated Perturbation of Adversarial Attack for well-known CNNs: Empirical Study and its Explanation
Sep 23, 2019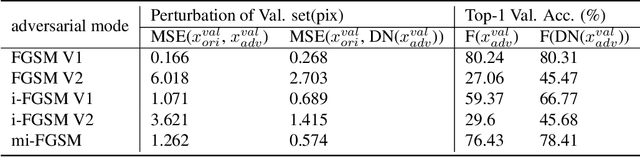
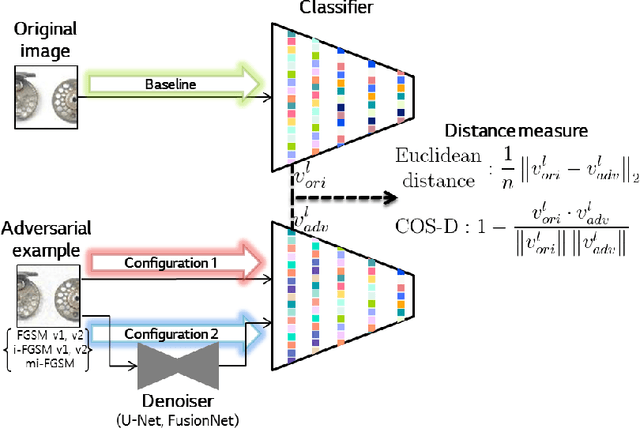
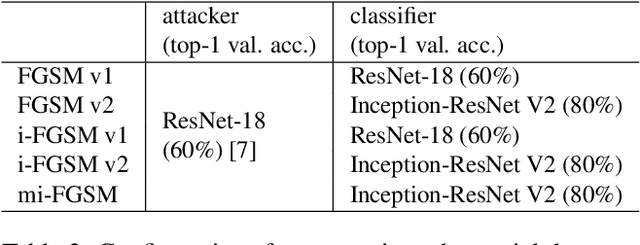
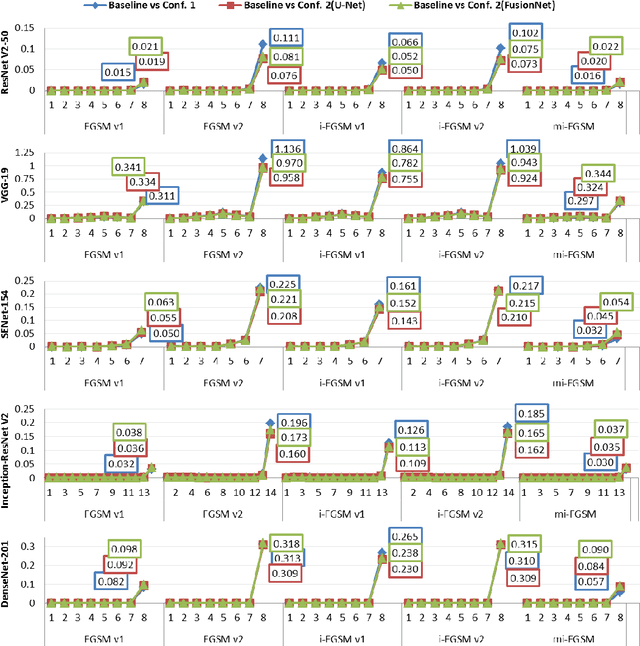
Deep Neural Network based classifiers are known to be vulnerable to perturbations of inputs constructed by an adversarial attack to force misclassification. Most studies have focused on how to make vulnerable noise by gradient based attack methods or to defense model from adversarial attack. The use of the denoiser model is one of a well-known solution to reduce the adversarial noise although classification performance had not significantly improved. In this study, we aim to analyze the propagation of adversarial attack as an explainable AI(XAI) point of view. Specifically, we examine the trend of adversarial perturbations through the CNN architectures. To analyze the propagated perturbation, we measured normalized Euclidean Distance and cosine distance in each CNN layer between the feature map of the perturbed image passed through denoiser and the non-perturbed original image. We used five well-known CNN based classifiers and three gradient-based adversarial attacks. From the experimental results, we observed that in most cases, Euclidean Distance explosively increases in the final fully connected layer while cosine distance fluctuated and disappeared at the last layer. This means that the use of denoiser can decrease the amount of noise. However, it failed to defense accuracy degradation.