 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrune-then-Quantize or Quantize-then-Prune? Understanding the Impact of Compression Order in Joint Model Compression
Mar 19, 2026What happens when multiple compression methods are combined-does the order in which they are applied matter? Joint model compression has emerged as a powerful strategy to achieve higher efficiency by combining multiple methods such as pruning and quantization. A central but underexplored factor in joint model compression is the compression order, or the sequence of different methods within the compression pipeline. Most prior studies have either sidestepped the issue by assuming orthogonality between techniques, while a few have examined them only in highly constrained cases. Consequently, the broader role of compression order in shaping model performance remains poorly understood. In this paper, we address the overlooked problem of compression order and provide both theoretical and empirical analysis. We formulate the problem of optimizing the compression order and introduce the Progressive Intensity Hypothesis, which states that weaker perturbations should precede stronger ones. We provide theoretical guarantees showing that the relative benefit of one order increases with the underlying performance gap. Extensive experiments on both language and vision models validate the hypothesis, and further show its generality to broader setups such as multi-stage compression and mixed-precision quantization.
SynQ: Accurate Zero-shot Quantization by Synthesis-aware Fine-tuning
Mar 19, 2026How can we accurately quantize a pre-trained model without any data? Quantization algorithms are widely used for deploying neural networks on resource-constrained edge devices. Zero-shot Quantization (ZSQ) addresses the crucial and practical scenario where training data are inaccessible for privacy or security reasons. However, three significant challenges hinder the performance of existing ZSQ methods: 1) noise in the synthetic dataset, 2) predictions based on off-target patterns, and the 3) misguidance by erroneous hard labels. In this paper, we propose SynQ (Synthesis-aware Fine-tuning for Zero-shot Quantization), a carefully designed ZSQ framework to overcome the limitations of existing methods. SynQ minimizes the noise from the generated samples by exploiting a low-pass filter. Then, SynQ trains the quantized model to improve accuracy by aligning its class activation map with the pre-trained model. Furthermore, SynQ mitigates misguidance from the pre-trained model's error by leveraging only soft labels for difficult samples. Extensive experiments show that SynQ provides the state-of-the-art accuracy, over existing ZSQ methods.
LampQ: Towards Accurate Layer-wise Mixed Precision Quantization for Vision Transformers
Nov 14, 2025



How can we accurately quantize a pre-trained Vision Transformer model? Quantization algorithms compress Vision Transformers (ViTs) into low-bit formats, reducing memory and computation demands with minimal accuracy degradation. However, existing methods rely on uniform precision, ignoring the diverse sensitivity of ViT components to quantization. Metric-based Mixed Precision Quantization (MPQ) is a promising alternative, but previous MPQ methods for ViTs suffer from three major limitations: 1) coarse granularity, 2) mismatch in metric scale across component types, and 3) quantization-unaware bit allocation. In this paper, we propose LampQ (Layer-wise Mixed Precision Quantization for Vision Transformers), an accurate metric-based MPQ method for ViTs to overcome these limitations. LampQ performs layer-wise quantization to achieve both fine-grained control and efficient acceleration, incorporating a type-aware Fisher-based metric to measure sensitivity. Then, LampQ assigns bit-widths optimally through integer linear programming and further updates them iteratively. Extensive experiments show that LampQ provides the state-of-the-art performance in quantizing ViTs pre-trained on various tasks such as image classification, object detection, and zero-shot quantization.
Accurate Action Recommendation for Smart Home via Two-Level Encoders and Commonsense Knowledge
Aug 12, 2022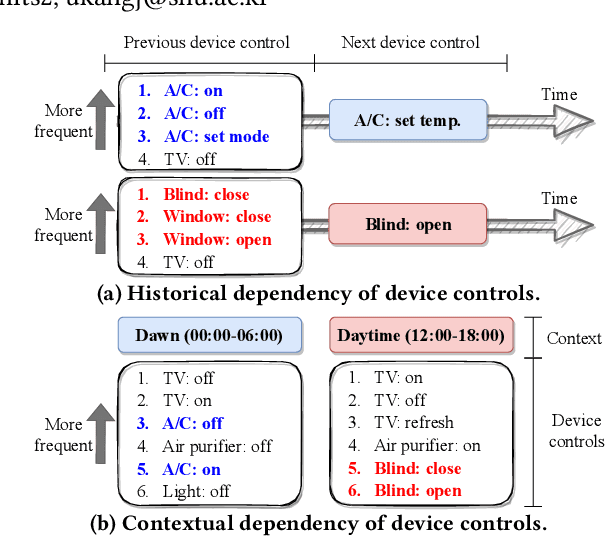
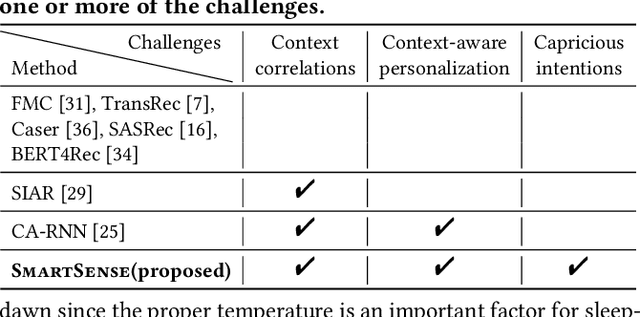
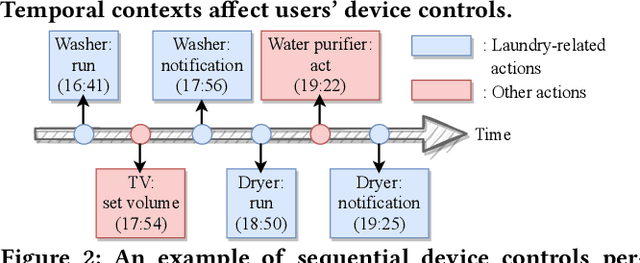
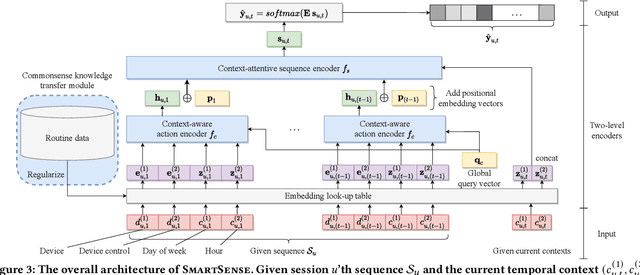
How can we accurately recommend actions for users to control their devices at home? Action recommendation for smart home has attracted increasing attention due to its potential impact on the markets of virtual assistants and Internet of Things (IoT). However, designing an effective action recommender system for smart home is challenging because it requires handling context correlations, considering both queried contexts and previous histories of users, and dealing with capricious intentions in history. In this work, we propose SmartSense, an accurate action recommendation method for smart home. For individual action, SmartSense summarizes its device control and its temporal contexts in a self-attentive manner, to reflect the importance of the correlation between them. SmartSense then summarizes sequences of users considering queried contexts in a query-attentive manner to extract the query-related patterns from the sequential actions. SmartSense also transfers the commonsense knowledge from routine data to better handle intentions in action sequences. As a result, SmartSense addresses all three main challenges of action recommendation for smart home, and achieves the state-of-the-art performance giving up to 9.8% higher mAP@1 than the best competitor.