 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models in Analyzing Crash Narratives -- A Comparative Study of ChatGPT, BARD and GPT-4
Aug 25, 2023In traffic safety research, extracting information from crash narratives using text analysis is a common practice. With recent advancements of large language models (LLM), it would be useful to know how the popular LLM interfaces perform in classifying or extracting information from crash narratives. To explore this, our study has used the three most popular publicly available LLM interfaces- ChatGPT, BARD and GPT4. This study investigated their usefulness and boundaries in extracting information and answering queries related to accidents from 100 crash narratives from Iowa and Kansas. During the investigation, their capabilities and limitations were assessed and their responses to the queries were compared. Five questions were asked related to the narratives: 1) Who is at-fault? 2) What is the manner of collision? 3) Has the crash occurred in a work-zone? 4) Did the crash involve pedestrians? and 5) What are the sequence of harmful events in the crash? For questions 1 through 4, the overall similarity among the LLMs were 70%, 35%, 96% and 89%, respectively. The similarities were higher while answering direct questions requiring binary responses and significantly lower for complex questions. To compare the responses to question 5, network diagram and centrality measures were analyzed. The network diagram from the three LLMs were not always similar although they sometimes have the same influencing events with high in-degree, out-degree and betweenness centrality. This study suggests using multiple models to extract viable information from narratives. Also, caution must be practiced while using these interfaces to obtain crucial safety related information.
A data-driven personalized smart lighting recommender system
Apr 05, 2021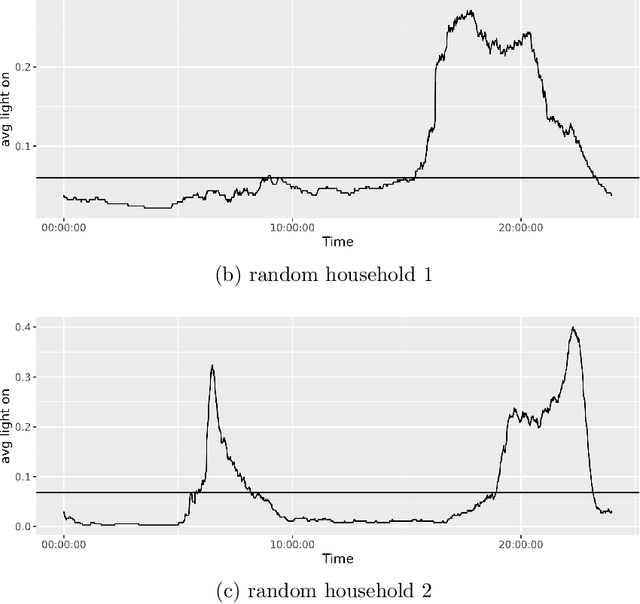
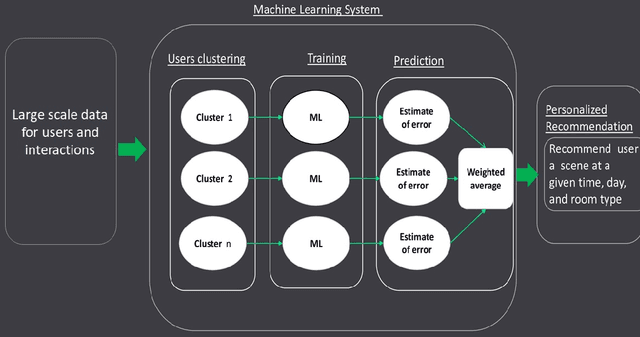
Recommender systems attempts to identify and recommend the most preferable item (product-service) to an individual user. These systems predict user interest in items based on related items, users, and the interactions between items and users. We aim to build an auto-routine and color scheme recommender system that leverages a wealth of historical data and machine learning methods. We introduce an unsupervised method to recommend a routine for lighting. Moreover, by analyzing users' daily logs, geographical location, temporal and usage information we understand user preference and predict their preferred color for lights. To do so, we cluster users based on their geographical information and usage distribution. We then build and train a predictive model within each cluster and aggregate the results. Results indicate that models based on similar users increases the prediction accuracy, with and without prior knowledge about user preferences.