 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Characteristic Function Approach to Deep Implicit Generative Modeling
Sep 16, 2019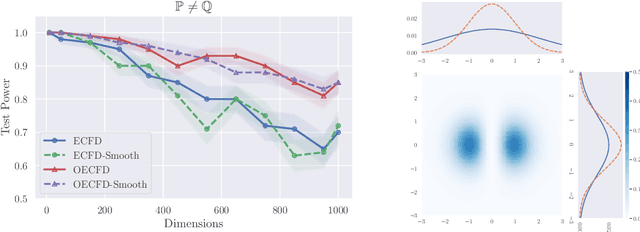
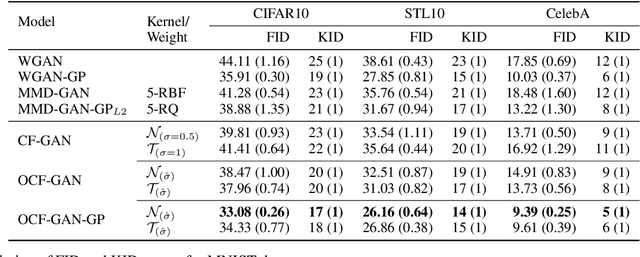
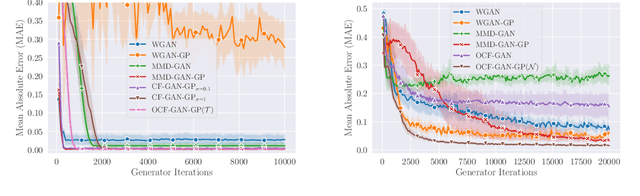
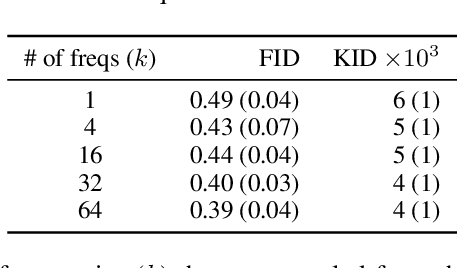
In this paper, we formulate the problem of learning an Implicit Generative Model (IGM) as minimizing the expected distance between characteristic functions. Specifically, we match the characteristic functions of the real and generated data distributions under a suitably-chosen weighting distribution. This distance measure, which we term as the characteristic function distance (CFD), can be (approximately) computed with linear time-complexity in the number of samples, compared to the quadratic-time Maximum Mean Discrepancy (MMD). By replacing the discrepancy measure in the critic of a GAN with the CFD, we obtain a model that is simple to implement and stable to train; the proposed metric enjoys desirable theoretical properties including continuity and differentiability with respect to generator parameters, and continuity in the weak topology. We further propose a variation of the CFD in which the weighting distribution parameters are also optimized during training; this obviates the need for manual tuning and leads to an improvement in test power relative to CFD. Experiments show that our proposed method outperforms WGAN and MMD-GAN variants on a variety of unsupervised image generation benchmark datasets.
Information-Theoretic Lower Bounds for Compressive Sensing with Generative Models
Aug 28, 2019
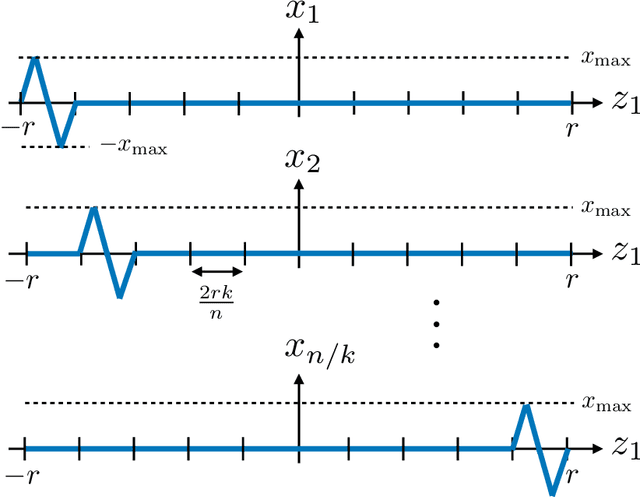
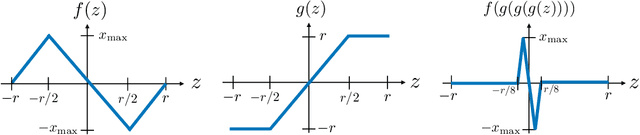
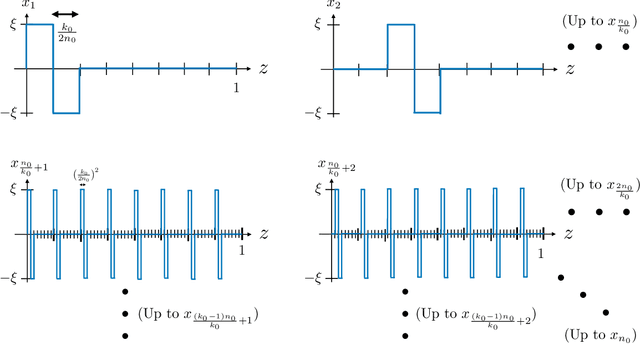
The goal of standard compressive sensing is to estimate an unknown vector from linear measurements under the assumption of sparsity in some basis. Recently, it has been shown that significantly fewer measurements may be required if the sparsity assumption is replaced by the assumption that the unknown vector lies near the range of a suitably-chosen generative model. In particular, in (Bora {\em et al.}, 2017) it was shown that roughly $O(k\log L)$ random Gaussian measurements suffice for accurate recovery when the $k$-input generative model is bounded and $L$-Lipschitz, and that $O(kd \log w)$ measurements suffice for $k$-input ReLU networks with depth $d$ and width $w$. In this paper, we establish corresponding algorithm-independent lower bounds on the sample complexity using tools from minimax statistical analysis. In accordance with the above upper bounds, our results are summarized as follows: (i) We construct an $L$-Lipschitz generative model capable of generating group-sparse signals, and show that the resulting necessary number of measurements is $\Omega(k \log L)$; (ii) Using similar ideas, we construct two-layer ReLU networks of high width requiring $\Omega(k \log w)$ measurements, as well as lower-width deep ReLU networks requiring $\Omega(k d)$ measurements. As a result, we establish that the scaling laws derived in (Bora {\em et al.}, 2017) are optimal or near-optimal in the absence of further assumptions.
Learning Erdős-Rényi Random Graphs via Edge Detecting Queries
May 11, 2019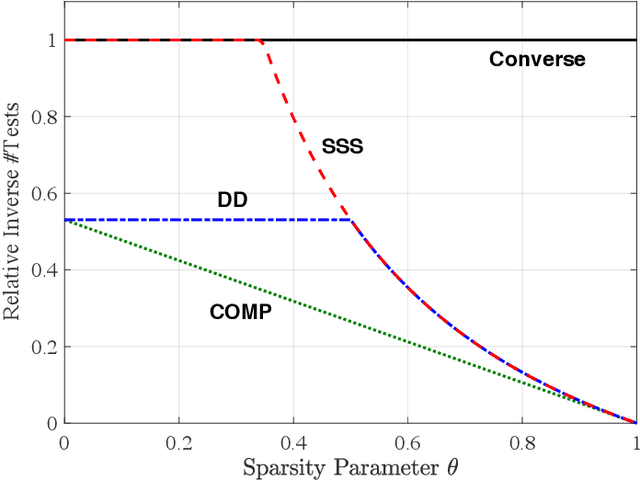
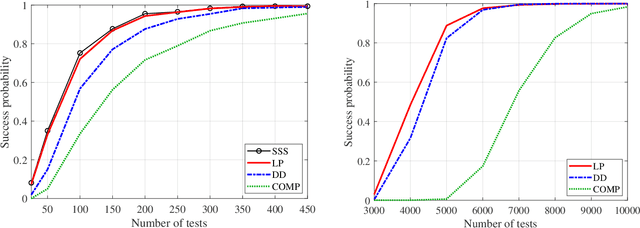
In this paper, we consider the problem of learning an unknown graph via queries on groups of nodes, with the result indicating whether or not at least one edge is present among those nodes. While learning arbitrary graphs with $n$ nodes and $k$ edges is known to be hard the sense of requiring $\Omega( \min\{ k^2 \log n, n^2\})$ tests (even when a small probability of error is allowed), we show that learning an Erd\H{o}s-R\'enyi random graph with an average of $\bar{k}$ edges is much easier; namely, one can attain asymptotically vanishing error probability with only $O(\bar{k} \log n)$ tests. We establish such bounds for a variety of algorithms inspired by the group testing problem, with explicit constant factors indicating a near-optimal number of tests, and in some cases asymptotic optimality including constant factors. In addition, we present an alternative design that permits a near-optimal sublinear decoding time of $O(\bar{k} \log^2 \bar{k} + \bar{k} \log n)$.
Support Recovery in the Phase Retrieval Model: Information-Theoretic Fundamental Limits
Jan 30, 2019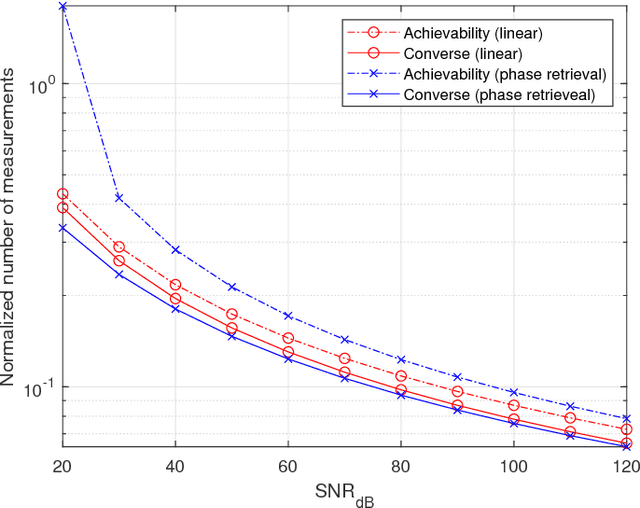
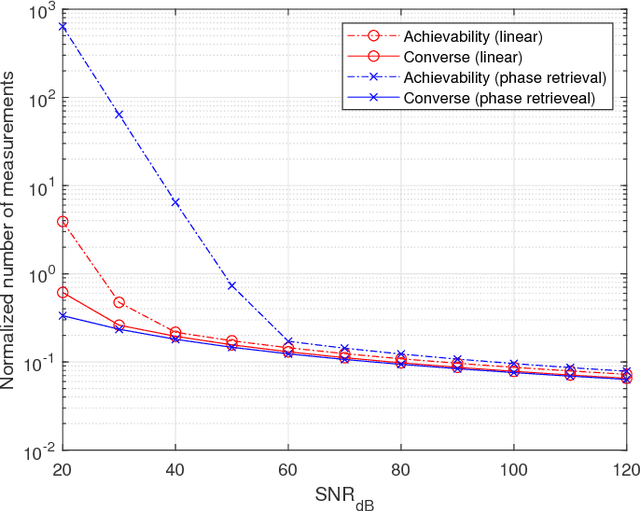
The support recovery problem consists of determining a sparse subset of variables that is relevant in generating a set of observations. In this paper, we study the support recovery problem in the phase retrieval model consisting of noisy phaseless measurements, which arises in a diverse range of settings such as optical detection, X-ray crystallography, electron microscopy, and coherent diffractive imaging. Our focus is on information-theoretic fundamental limits under an approximate recovery criterion, considering both discrete and Gaussian models for the sparse non-zero entries. In both cases, our bounds provide sharp thresholds with near-matching constant factors in several scaling regimes on the sparsity and signal-to-noise ratio. As a key step towards obtaining these results, we develop new concentration bounds for the conditional information content of log-concave random variables, which may be of independent interest.
An Introductory Guide to Fano's Inequality with Applications in Statistical Estimation
Jan 02, 2019
Information theory plays an indispensable role in the development of algorithm-independent impossibility results, both for communication problems and for seemingly distinct areas such as statistics and machine learning. While numerous information-theoretic tools have been proposed for this purpose, the oldest one remains arguably the most versatile and widespread: Fano's inequality. In this chapter, we provide a survey of Fano's inequality and its variants in the context of statistical estimation, adopting a versatile framework that covers a wide range of specific problems. We present a variety of key tools and techniques used for establishing impossibility results via this approach, and provide representative examples covering group testing, graphical model selection, sparse linear regression, density estimation, and convex optimization.
Adversarially Robust Optimization with Gaussian Processes
Nov 01, 2018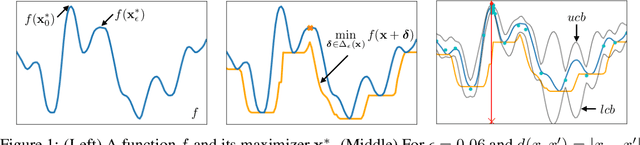
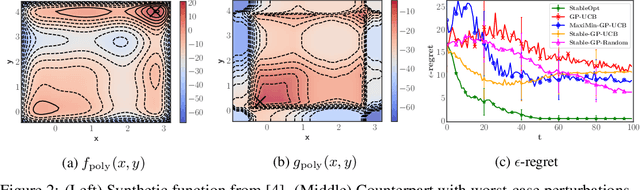
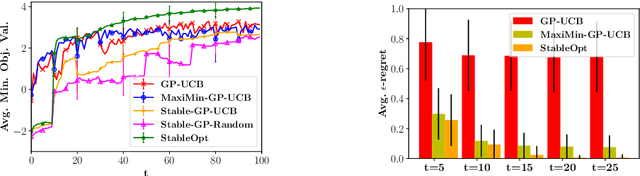
In this paper, we consider the problem of Gaussian process (GP) optimization with an added robustness requirement: The returned point may be perturbed by an adversary, and we require the function value to remain as high as possible even after this perturbation. This problem is motivated by settings in which the underlying functions during optimization and implementation stages are different, or when one is interested in finding an entire region of good inputs rather than only a single point. We show that standard GP optimization algorithms do not exhibit the desired robustness properties, and provide a novel confidence-bound based algorithm StableOpt for this purpose. We rigorously establish the required number of samples for StableOpt to find a near-optimal point, and we complement this guarantee with an algorithm-independent lower bound. We experimentally demonstrate several potential applications of interest using real-world data sets, and we show that StableOpt consistently succeeds in finding a stable maximizer where several baseline methods fail.
Lower Bounds on Regret for Noisy Gaussian Process Bandit Optimization
May 31, 2018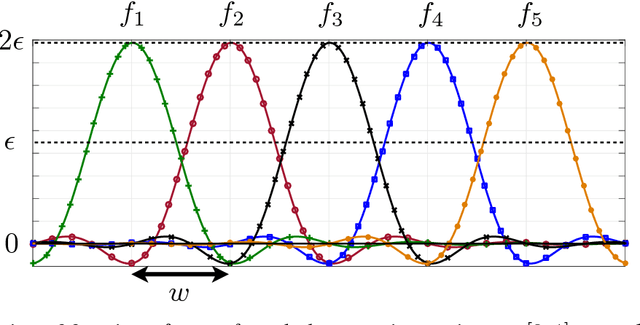

In this paper, we consider the problem of sequentially optimizing a black-box function $f$ based on noisy samples and bandit feedback. We assume that $f$ is smooth in the sense of having a bounded norm in some reproducing kernel Hilbert space (RKHS), yielding a commonly-considered non-Bayesian form of Gaussian process bandit optimization. We provide algorithm-independent lower bounds on the simple regret, measuring the suboptimality of a single point reported after $T$ rounds, and on the cumulative regret, measuring the sum of regrets over the $T$ chosen points. For the isotropic squared-exponential kernel in $d$ dimensions, we find that an average simple regret of $\epsilon$ requires $T = \Omega\big(\frac{1}{\epsilon^2} (\log\frac{1}{\epsilon})^{d/2}\big)$, and the average cumulative regret is at least $\Omega\big( \sqrt{T(\log T)^{d/2}} \big)$, thus matching existing upper bounds up to the replacement of $d/2$ by $2d+O(1)$ in both cases. For the Mat\'ern-$\nu$ kernel, we give analogous bounds of the form $\Omega\big( (\frac{1}{\epsilon})^{2+d/\nu}\big)$ and $\Omega\big( T^{\frac{\nu + d}{2\nu + d}} \big)$, and discuss the resulting gaps to the existing upper bounds.
Tight Regret Bounds for Bayesian Optimization in One Dimension
May 30, 2018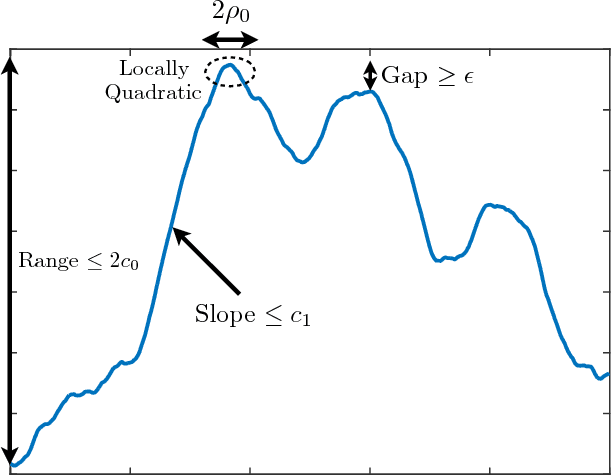
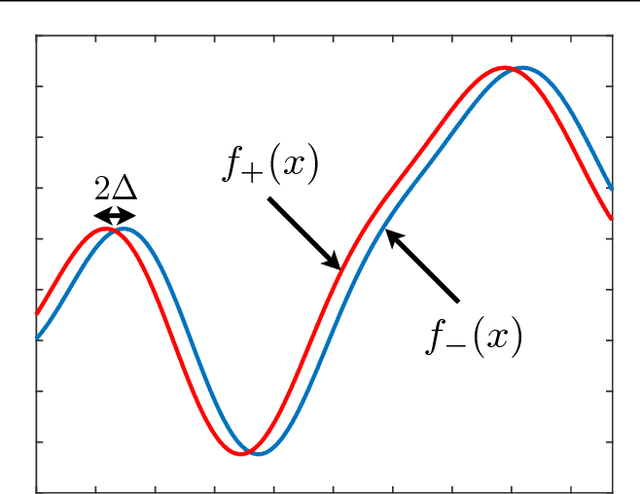
We consider the problem of Bayesian optimization (BO) in one dimension, under a Gaussian process prior and Gaussian sampling noise. We provide a theoretical analysis showing that, under fairly mild technical assumptions on the kernel, the best possible cumulative regret up to time $T$ behaves as $\Omega(\sqrt{T})$ and $O(\sqrt{T\log T})$. This gives a tight characterization up to a $\sqrt{\log T}$ factor, and includes the first non-trivial lower bound for noisy BO. Our assumptions are satisfied, for example, by the squared exponential and Mat\'ern-$\nu$ kernels, with the latter requiring $\nu > 2$. Our results certify the near-optimality of existing bounds (Srinivas {\em et al.}, 2009) for the SE kernel, while proving them to be strictly suboptimal for the Mat\'ern kernel with $\nu > 2$.
Learning-Based Compressive MRI
May 03, 2018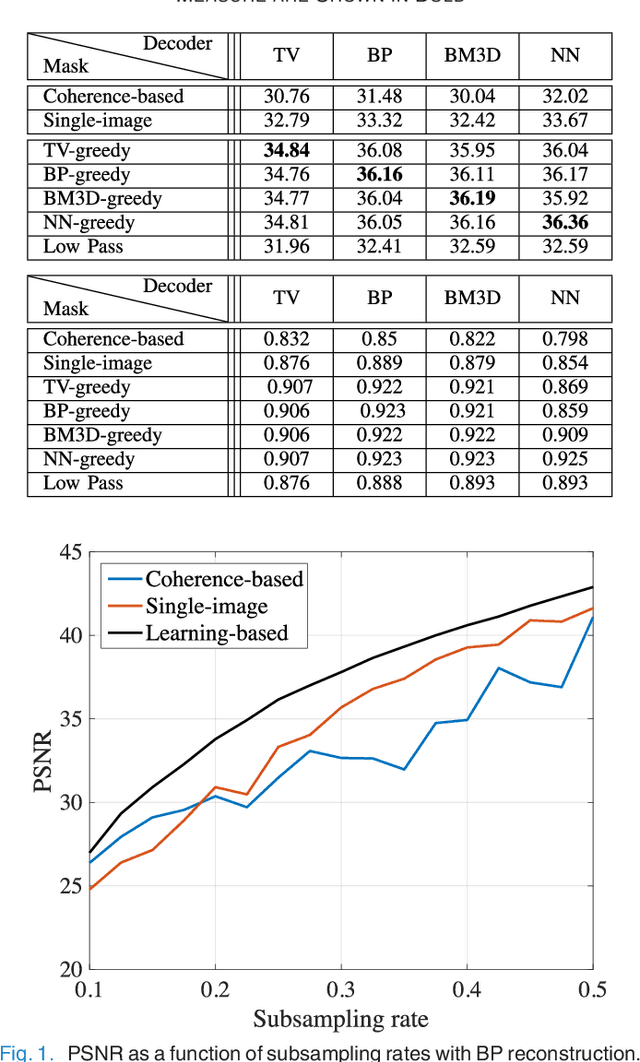

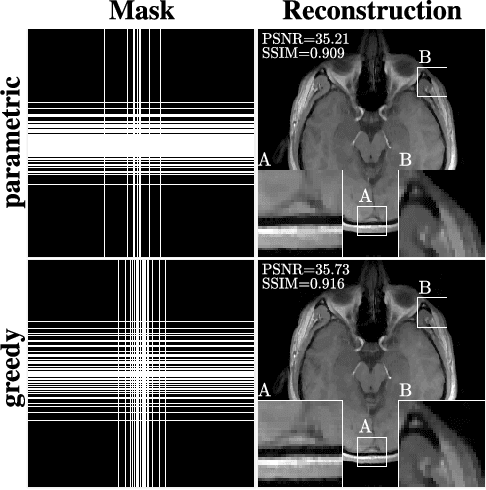
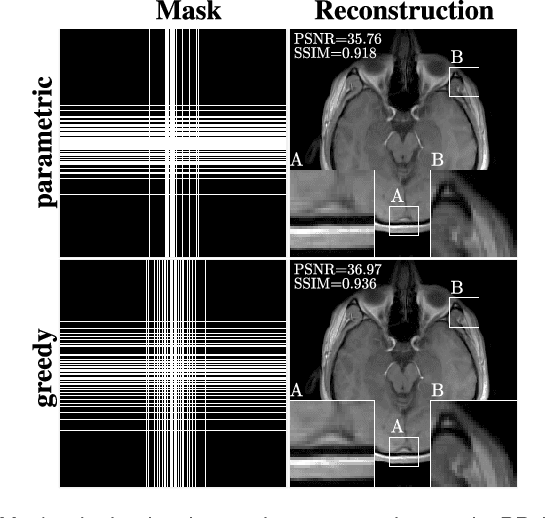
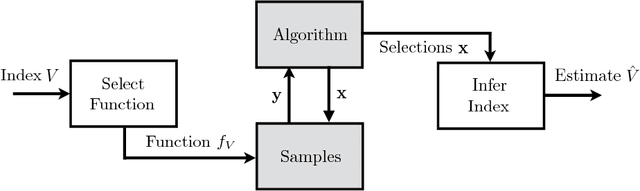
In the area of magnetic resonance imaging (MRI), an extensive range of non-linear reconstruction algorithms have been proposed that can be used with general Fourier subsampling patterns. However, the design of these subsampling patterns has typically been considered in isolation from the reconstruction rule and the anatomy under consideration. In this paper, we propose a learning-based framework for optimizing MRI subsampling patterns for a specific reconstruction rule and anatomy, considering both the noiseless and noisy settings. Our learning algorithm has access to a representative set of training signals, and searches for a sampling pattern that performs well on average for the signals in this set. We present a novel parameter-free greedy mask selection method, and show it to be effective for a variety of reconstruction rules and performance metrics. Moreover we also support our numerical findings by providing a rigorous justification of our framework via statistical learning theory.
High-Dimensional Bayesian Optimization via Additive Models with Overlapping Groups
Mar 28, 2018
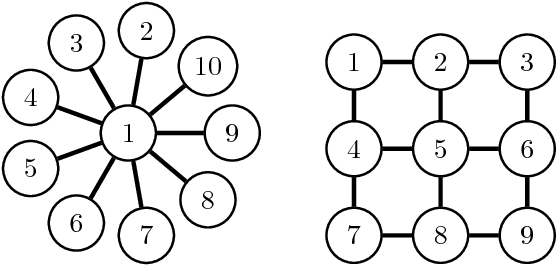
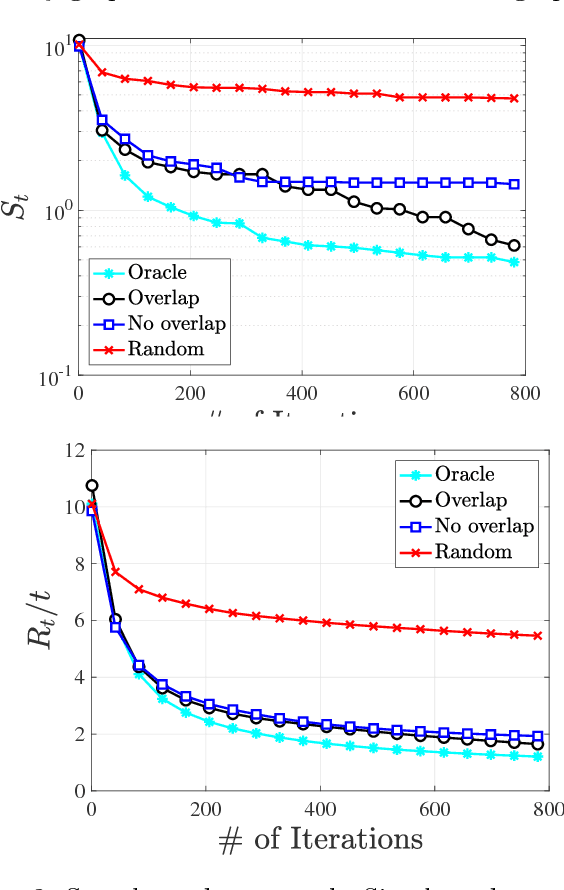
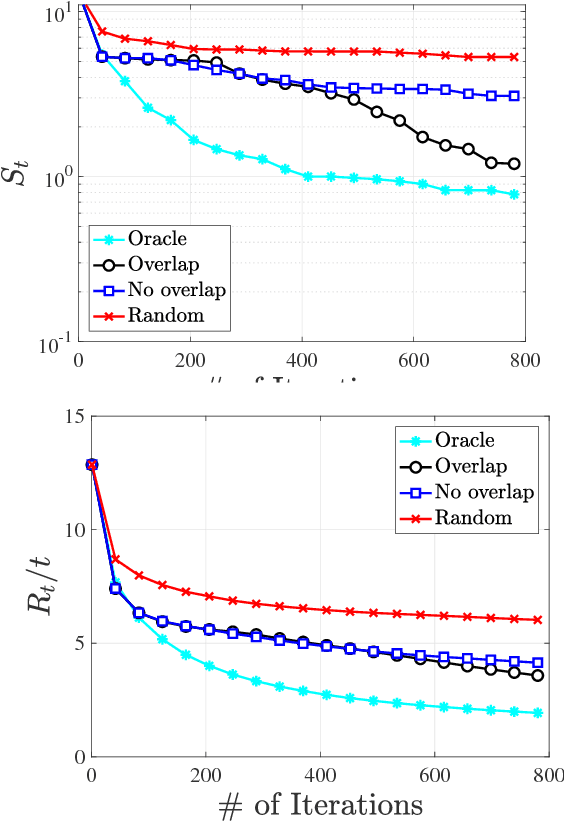
Bayesian optimization (BO) is a popular technique for sequential black-box function optimization, with applications including parameter tuning, robotics, environmental monitoring, and more. One of the most important challenges in BO is the development of algorithms that scale to high dimensions, which remains a key open problem despite recent progress. In this paper, we consider the approach of Kandasamy et al. (2015), in which the high-dimensional function decomposes as a sum of lower-dimensional functions on subsets of the underlying variables. In particular, we significantly generalize this approach by lifting the assumption that the subsets are disjoint, and consider additive models with arbitrary overlap among the subsets. By representing the dependencies via a graph, we deduce an efficient message passing algorithm for optimizing the acquisition function. In addition, we provide an algorithm for learning the graph from samples based on Gibbs sampling. We empirically demonstrate the effectiveness of our methods on both synthetic and real-world data.