 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounting as a minimal probe of language model reliability
May 03, 2026Large language models perform strongly on benchmarks in mathematical reasoning, coding and document analysis, suggesting a broad ability to follow instructions. However, it remains unclear whether such success reflects general logical competence, repeated application of learned procedures, or pattern matching that mimics rule execution. We investigate this question by introducing Stable Counting Capacity, an assay in which models count repeated symbols until failure. The assay removes knowledge dependencies, semantics and ambiguity from evaluation, avoids lexical and tokenization confounds, and provides a direct measure of procedural reliability beyond standard knowledge-based benchmarks. Here we show, across more than 100 model variants, that stable counting capacity remains far below advertised context limits. Model behavior is consistent neither with open-ended logic nor with stable application of a learned rule, but instead with use of a finite set of count-like internal states, analogous to counting on fingers. Once this resource is exhausted, the appearance of rule following disappears and exact execution collapses into guessing, even with additional test-time compute. These findings show that fluent performance in current language models does not guarantee general, reliable rule following.
Characterizing and Optimizing the Spatial Kernel of Multi Resolution Hash Encodings
Feb 11, 2026Multi-Resolution Hash Encoding (MHE), the foundational technique behind Instant Neural Graphics Primitives, provides a powerful parameterization for neural fields. However, its spatial behavior lacks rigorous understanding from a physical systems perspective, leading to reliance on heuristics for hyperparameter selection. This work introduces a novel analytical approach that characterizes MHE by examining its Point Spread Function (PSF), which is analogous to the Green's function of the system. This methodology enables a quantification of the encoding's spatial resolution and fidelity. We derive a closed-form approximation for the collision-free PSF, uncovering inherent grid-induced anisotropy and a logarithmic spatial profile. We establish that the idealized spatial bandwidth, specifically the Full Width at Half Maximum (FWHM), is determined by the average resolution, $N_{\text{avg}}$. This leads to a counterintuitive finding: the effective resolution of the model is governed by the broadened empirical FWHM (and therefore $N_{\text{avg}}$), rather than the finest resolution $N_{\max}$, a broadening effect we demonstrate arises from optimization dynamics. Furthermore, we analyze the impact of finite hash capacity, demonstrating how collisions introduce speckle noise and degrade the Signal-to-Noise Ratio (SNR). Leveraging these theoretical insights, we propose Rotated MHE (R-MHE), an architecture that applies distinct rotations to the input coordinates at each resolution level. R-MHE mitigates anisotropy while maintaining the efficiency and parameter count of the original MHE. This study establishes a methodology based on physical principles that moves beyond heuristics to characterize and optimize MHE.
* ICLR 2026 (Poster); LaTeX source; 11 figures; 7 tables
FOLIO: Natural Language Reasoning with First-Order Logic
Sep 02, 2022
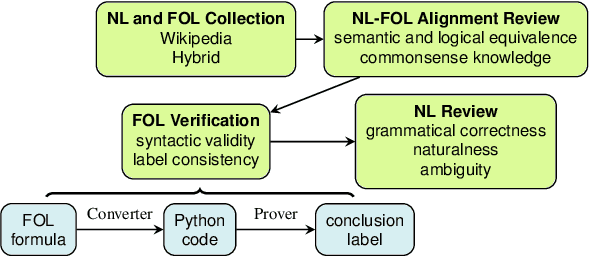
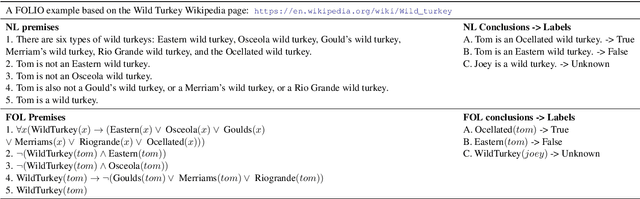
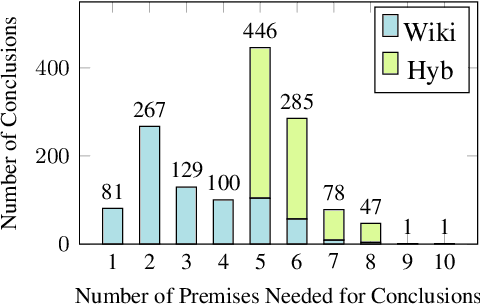
We present FOLIO, a human-annotated, open-domain, and logically complex and diverse dataset for reasoning in natural language (NL), equipped with first order logic (FOL) annotations. FOLIO consists of 1,435 examples (unique conclusions), each paired with one of 487 sets of premises which serve as rules to be used to deductively reason for the validity of each conclusion. The logical correctness of premises and conclusions is ensured by their parallel FOL annotations, which are automatically verified by our FOL inference engine. In addition to the main NL reasoning task, NL-FOL pairs in FOLIO automatically constitute a new NL-FOL translation dataset using FOL as the logical form. Our experiments on FOLIO systematically evaluate the FOL reasoning ability of supervised fine-tuning on medium-sized language models (BERT, RoBERTa) and few-shot prompting on large language models (GPT-NeoX, OPT, GPT-3, Codex). For NL-FOL translation, we experiment with GPT-3 and Codex. Our results show that one of the most capable Large Language Model (LLM) publicly available, GPT-3 davinci, achieves only slightly better than random results with few-shot prompting on a subset of FOLIO, and the model is especially bad at predicting the correct truth values for False and Unknown conclusions. Our dataset and code are available at https://github.com/Yale-LILY/FOLIO.