 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoolbox: A Python toolbox to benchmark the robustness of machine learning models
Mar 20, 2018Even todays most advanced machine learning models are easily fooled by almost imperceptible perturbations of their inputs. Foolbox is a new Python package to generate such adversarial perturbations and to quantify and compare the robustness of machine learning models. It is build around the idea that the most comparable robustness measure is the minimum perturbation needed to craft an adversarial example. To this end, Foolbox provides reference implementations of most published adversarial attack methods alongside some new ones, all of which perform internal hyperparameter tuning to find the minimum adversarial perturbation. Additionally, Foolbox interfaces with most popular deep learning frameworks such as PyTorch, Keras, TensorFlow, Theano and MXNet and allows different adversarial criteria such as targeted misclassification and top-k misclassification as well as different distance measures. The code is licensed under the MIT license and is openly available at https://github.com/bethgelab/foolbox . The most up-to-date documentation can be found at http://foolbox.readthedocs.io .
Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models
Feb 16, 2018
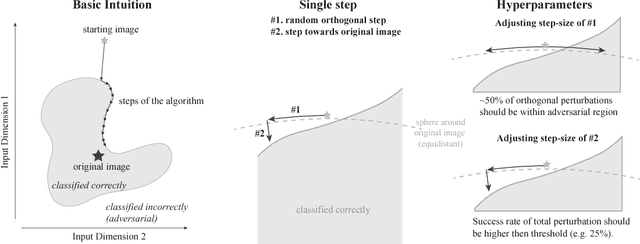


Many machine learning algorithms are vulnerable to almost imperceptible perturbations of their inputs. So far it was unclear how much risk adversarial perturbations carry for the safety of real-world machine learning applications because most methods used to generate such perturbations rely either on detailed model information (gradient-based attacks) or on confidence scores such as class probabilities (score-based attacks), neither of which are available in most real-world scenarios. In many such cases one currently needs to retreat to transfer-based attacks which rely on cumbersome substitute models, need access to the training data and can be defended against. Here we emphasise the importance of attacks which solely rely on the final model decision. Such decision-based attacks are (1) applicable to real-world black-box models such as autonomous cars, (2) need less knowledge and are easier to apply than transfer-based attacks and (3) are more robust to simple defences than gradient- or score-based attacks. Previous attacks in this category were limited to simple models or simple datasets. Here we introduce the Boundary Attack, a decision-based attack that starts from a large adversarial perturbation and then seeks to reduce the perturbation while staying adversarial. The attack is conceptually simple, requires close to no hyperparameter tuning, does not rely on substitute models and is competitive with the best gradient-based attacks in standard computer vision tasks like ImageNet. We apply the attack on two black-box algorithms from Clarifai.com. The Boundary Attack in particular and the class of decision-based attacks in general open new avenues to study the robustness of machine learning models and raise new questions regarding the safety of deployed machine learning systems. An implementation of the attack is available as part of Foolbox at https://github.com/bethgelab/foolbox .
Comparing deep neural networks against humans: object recognition when the signal gets weaker
Jun 21, 2017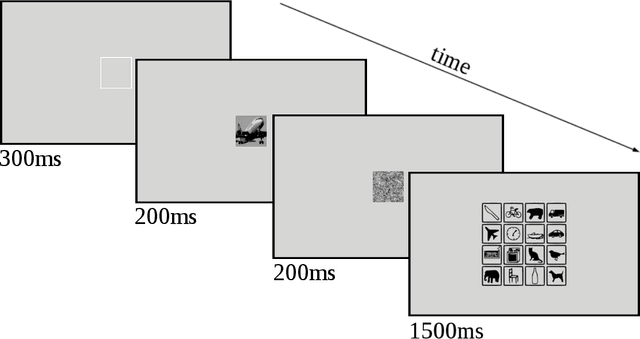

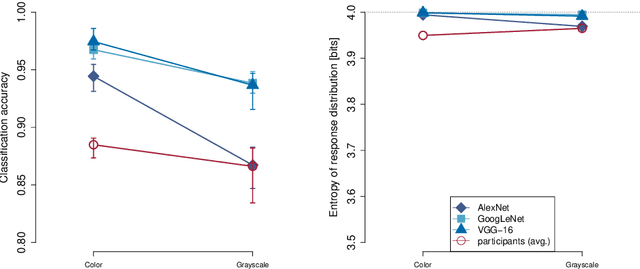
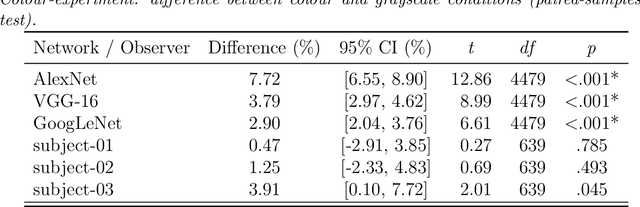
Human visual object recognition is typically rapid and seemingly effortless, as well as largely independent of viewpoint and object orientation. Until very recently, animate visual systems were the only ones capable of this remarkable computational feat. This has changed with the rise of a class of computer vision algorithms called deep neural networks (DNNs) that achieve human-level classification performance on object recognition tasks. Furthermore, a growing number of studies report similarities in the way DNNs and the human visual system process objects, suggesting that current DNNs may be good models of human visual object recognition. Yet there clearly exist important architectural and processing differences between state-of-the-art DNNs and the primate visual system. The potential behavioural consequences of these differences are not well understood. We aim to address this issue by comparing human and DNN generalisation abilities towards image degradations. We find the human visual system to be more robust to image manipulations like contrast reduction, additive noise or novel eidolon-distortions. In addition, we find progressively diverging classification error-patterns between man and DNNs when the signal gets weaker, indicating that there may still be marked differences in the way humans and current DNNs perform visual object recognition. We envision that our findings as well as our carefully measured and freely available behavioural datasets provide a new useful benchmark for the computer vision community to improve the robustness of DNNs and a motivation for neuroscientists to search for mechanisms in the brain that could facilitate this robustness.