 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera-Only 3D Panoptic Scene Completion for Autonomous Driving through Differentiable Object Shapes
May 14, 2025



Autonomous vehicles need a complete map of their surroundings to plan and act. This has sparked research into the tasks of 3D occupancy prediction, 3D scene completion, and 3D panoptic scene completion, which predict a dense map of the ego vehicle's surroundings as a voxel grid. Scene completion extends occupancy prediction by predicting occluded regions of the voxel grid, and panoptic scene completion further extends this task by also distinguishing object instances within the same class; both aspects are crucial for path planning and decision-making. However, 3D panoptic scene completion is currently underexplored. This work introduces a novel framework for 3D panoptic scene completion that extends existing 3D semantic scene completion models. We propose an Object Module and Panoptic Module that can easily be integrated with 3D occupancy and scene completion methods presented in the literature. Our approach leverages the available annotations in occupancy benchmarks, allowing individual object shapes to be learned as a differentiable problem. The code is available at https://github.com/nicolamarinello/OffsetOcc .
MonoCInIS: Camera Independent Monocular 3D Object Detection using Instance Segmentation
Oct 01, 2021
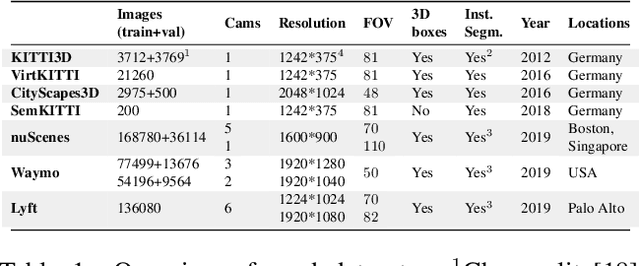
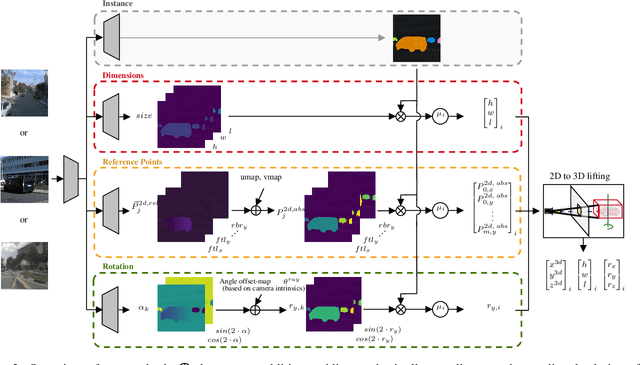
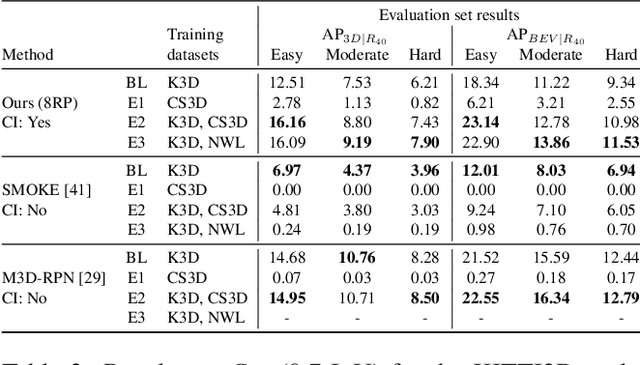
Monocular 3D object detection has recently shown promising results, however there remain challenging problems. One of those is the lack of invariance to different camera intrinsic parameters, which can be observed across different 3D object datasets. Little effort has been made to exploit the combination of heterogeneous 3D object datasets. In contrast to general intuition, we show that more data does not automatically guarantee a better performance, but rather, methods need to have a degree of 'camera independence' in order to benefit from large and heterogeneous training data. In this paper we propose a category-level pose estimation method based on instance segmentation, using camera independent geometric reasoning to cope with the varying camera viewpoints and intrinsics of different datasets. Every pixel of an instance predicts the object dimensions, the 3D object reference points projected in 2D image space and, optionally, the local viewing angle. Camera intrinsics are only used outside of the learned network to lift the predicted 2D reference points to 3D. We surpass camera independent methods on the challenging KITTI3D benchmark and show the key benefits compared to camera dependent methods.