 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX4: Efficient Pure W4A4 LLM Inference via Intra-SM Compute Rebalancing
Jun 07, 2026W4A4 quantization promises full utilization of INT4 Tensor Cores, yet group dequantization overhead on CUDA Cores has driven existing systems to mixed-precision fallbacks. We present the first systematic study of how intra-SM compute balance governs this bottleneck. Through controlled benchmarks across four GPUs from Ampere and Ada architectures, we identify the Tensor Cores to CUDA Cores throughput ratio ($ρ$) as the primary hardware indicator: the W4A4-g128 kernel yields $2.0$--$2.5\times$ speedup on RTX~3090 ($ρ=16$) yet degrades to $0.43$--$0.47\times$ on A100 ($ρ=64$) in compute-bond scenarios, establishing W4A4 viability as platform-dependent rather than universally infeasible. Guided by this finding, we build \textbf{APEX4}, which co-designs pure INT4 GEMM kernels with $ρ$-aware granularity adaptation to mitigate the CUDA Cores dequantization bottleneck. APEX4 achieves perplexity within 0.63 of FP16 on LLaMA-2-70B and outperforms W4Ax Atom-g128 by 4.0\%--4.4\% in zero-shot accuracy. Deployed as a drop-in replacement in unmodified vLLM, it delivers up to $1.66\times$ end-to-end speedup on L40S ($ρ=8$), and $1.78\times$ on RTX~3090 ($ρ=16$), $2.09\times$ on A40 ($ρ=16$), while recovering A100 ($ρ=64$) to $1.20$--$1.40\times$ via the mixed-granularity mode.
Beyond Accuracy: Benchmarking Cross-Task Consistency in Unified Multimodal Models
Apr 27, 2026Unified Multimodal Models (uMMs) aim to support both visual understanding and visual generation within a shared representation. However, existing evaluation protocols assess these two capabilities independently and do not examine whether they are semantically aligned. As a result, it remains unclear whether current uMMs learn coherent unified representations that remain consistent across tasks given a visual concept. We introduce XTC-Bench, a scene-graph-grounded evaluation framework that measures cross-task visual semantic consistency. By deriving both generation prompts and understanding queries from a structured scene graph, our framework enables fact-level alignment analysis across objects, attributes, and relations. We propose Continuous Cross-Task Agreement (CCTA), a fine-grained metric that quantifies semantic agreement between generation and understanding over matched atomic facts, isolating internal consistency from standalone task accuracy. Extensive experiments on eight open-source and one commercial unified models reveal that high generation or understanding performance does not imply strong cross-task alignment, and architectural analysis shows consistency is governed by how tightly learning objectives are coupled across modalities, not by architectural unification alone. XTC-Bench provides a reproducible and model-agnostic framework for diagnosing representation-level misalignment, offering a concrete direction for advancing unified multimodal modeling beyond isolated task performance.
Supervised Knowledge May Hurt Novel Class Discovery Performance
Jun 06, 2023



Novel class discovery (NCD) aims to infer novel categories in an unlabeled dataset by leveraging prior knowledge of a labeled set comprising disjoint but related classes. Given that most existing literature focuses primarily on utilizing supervised knowledge from a labeled set at the methodology level, this paper considers the question: Is supervised knowledge always helpful at different levels of semantic relevance? To proceed, we first establish a novel metric, so-called transfer flow, to measure the semantic similarity between labeled/unlabeled datasets. To show the validity of the proposed metric, we build up a large-scale benchmark with various degrees of semantic similarities between labeled/unlabeled datasets on ImageNet by leveraging its hierarchical class structure. The results based on the proposed benchmark show that the proposed transfer flow is in line with the hierarchical class structure; and that NCD performance is consistent with the semantic similarities (measured by the proposed metric). Next, by using the proposed transfer flow, we conduct various empirical experiments with different levels of semantic similarity, yielding that supervised knowledge may hurt NCD performance. Specifically, using supervised information from a low-similarity labeled set may lead to a suboptimal result as compared to using pure self-supervised knowledge. These results reveal the inadequacy of the existing NCD literature which usually assumes that supervised knowledge is beneficial. Finally, we develop a pseudo-version of the transfer flow as a practical reference to decide if supervised knowledge should be used in NCD. Its effectiveness is supported by our empirical studies, which show that the pseudo transfer flow (with or without supervised knowledge) is consistent with the corresponding accuracy based on various datasets. Code is released at https://github.com/J-L-O/SK-Hurt-NCD
DocLangID: Improving Few-Shot Training to Identify the Language of Historical Documents
May 03, 2023



Language identification describes the task of recognizing the language of written text in documents. This information is crucial because it can be used to support the analysis of a document's vocabulary and context. Supervised learning methods in recent years have advanced the task of language identification. However, these methods usually require large labeled datasets, which often need to be included for various domains of images, such as documents or scene images. In this work, we propose DocLangID, a transfer learning approach to identify the language of unlabeled historical documents. We achieve this by first leveraging labeled data from a different but related domain of historical documents. Secondly, we implement a distance-based few-shot learning approach to adapt a convolutional neural network to new languages of the unlabeled dataset. By introducing small amounts of manually labeled examples from the set of unlabeled images, our feature extractor develops a better adaptability towards new and different data distributions of historical documents. We show that such a model can be effectively fine-tuned for the unlabeled set of images by only reusing the same few-shot examples. We showcase our work across 10 languages that mostly use the Latin script. Our experiments on historical documents demonstrate that our combined approach improves the language identification performance, achieving 74% recognition accuracy on the four unseen languages of the unlabeled dataset.
A Closer Look at Novel Class Discovery from the Labeled Set
Sep 21, 2022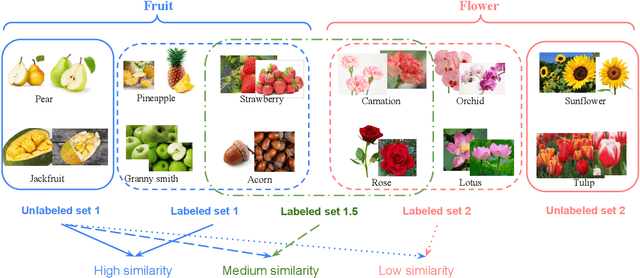
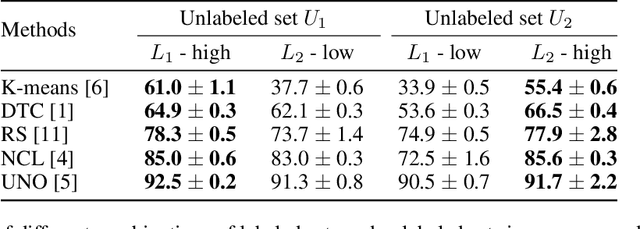
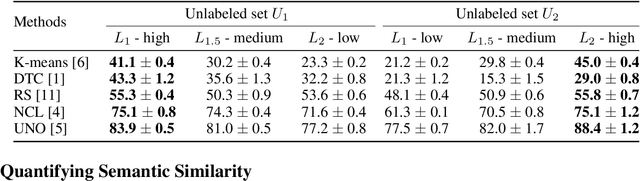
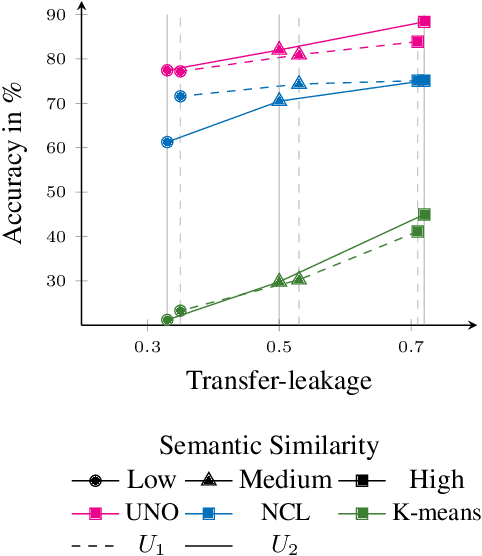
Novel class discovery (NCD) aims to infer novel categories in an unlabeled dataset leveraging prior knowledge of a labeled set comprising disjoint but related classes. Existing research focuses primarily on utilizing the labeled set at the methodological level, with less emphasis on the analysis of the labeled set itself. Thus, in this paper, we rethink novel class discovery from the labeled set and focus on two core questions: (i) Given a specific unlabeled set, what kind of labeled set can best support novel class discovery? (ii) A fundamental premise of NCD is that the labeled set must be related to the unlabeled set, but how can we measure this relation? For (i), we propose and substantiate the hypothesis that NCD could benefit more from a labeled set with a large degree of semantic similarity to the unlabeled set. Specifically, we establish an extensive and large-scale benchmark with varying degrees of semantic similarity between labeled/unlabeled datasets on ImageNet by leveraging its hierarchical class structure. As a sharp contrast, the existing NCD benchmarks are developed based on labeled sets with different number of categories and images, and completely ignore the semantic relation. For (ii), we introduce a mathematical definition for quantifying the semantic similarity between labeled and unlabeled sets. In addition, we use this metric to confirm the validity of our proposed benchmark and demonstrate that it highly correlates with NCD performance. Furthermore, without quantitative analysis, previous works commonly believe that label information is always beneficial. However, counterintuitively, our experimental results show that using labels may lead to sub-optimal outcomes in low-similarity settings.