 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Abstract Meaning Representation Parsing to the Clinical Narrative -- the SPRING THYME parser
May 15, 2024This paper is dedicated to the design and evaluation of the first AMR parser tailored for clinical notes. Our objective was to facilitate the precise transformation of the clinical notes into structured AMR expressions, thereby enhancing the interpretability and usability of clinical text data at scale. Leveraging the colon cancer dataset from the Temporal Histories of Your Medical Events (THYME) corpus, we adapted a state-of-the-art AMR parser utilizing continuous training. Our approach incorporates data augmentation techniques to enhance the accuracy of AMR structure predictions. Notably, through this learning strategy, our parser achieved an impressive F1 score of 88% on the THYME corpus's colon cancer dataset. Moreover, our research delved into the efficacy of data required for domain adaptation within the realm of clinical notes, presenting domain adaptation data requirements for AMR parsing. This exploration not only underscores the parser's robust performance but also highlights its potential in facilitating a deeper understanding of clinical narratives through structured semantic representations.
CAMRA: Copilot for AMR Annotation
Nov 18, 2023



In this paper, we introduce CAMRA (Copilot for AMR Annotatations), a cutting-edge web-based tool designed for constructing Abstract Meaning Representation (AMR) from natural language text. CAMRA offers a novel approach to deep lexical semantics annotation such as AMR, treating AMR annotation akin to coding in programming languages. Leveraging the familiarity of programming paradigms, CAMRA encompasses all essential features of existing AMR editors, including example lookup, while going a step further by integrating Propbank roleset lookup as an autocomplete feature within the tool. Notably, CAMRA incorporates AMR parser models as coding co-pilots, greatly enhancing the efficiency and accuracy of AMR annotators. To demonstrate the tool's capabilities, we provide a live demo accessible at: https://camra.colorado.edu
Dependency Dialogue Acts -- Annotation Scheme and Case Study
Feb 25, 2023



In this paper, we introduce Dependency Dialogue Acts (DDA), a novel framework for capturing the structure of speaker-intentions in multi-party dialogues. DDA combines and adapts features from existing dialogue annotation frameworks, and emphasizes the multi-relational response structure of dialogues in addition to the dialogue acts and rhetorical relations. It represents the functional, discourse, and response structure in multi-party multi-threaded conversations. A few key features distinguish DDA from existing dialogue annotation frameworks such as SWBD-DAMSL and the ISO 24617-2 standard. First, DDA prioritizes the relational structure of the dialogue units and the dialog context, annotating both dialog acts and rhetorical relations as response relations to particular utterances. Second, DDA embraces overloading in dialogues, encouraging annotators to specify multiple response relations and dialog acts for each dialog unit. Lastly, DDA places an emphasis on adequately capturing how a speaker is using the full dialog context to plan and organize their speech. With these features, DDA is highly expressive and recall-oriented with regard to conversation dynamics between multiple speakers. In what follows, we present the DDA annotation framework and case studies annotating DDA structures in multi-party, multi-threaded conversations.
* The 13th International Workshop on Spoken Dialogue Systems Technology
Many Faces of Feature Importance: Comparing Built-in and Post-hoc Feature Importance in Text Classification
Oct 18, 2019

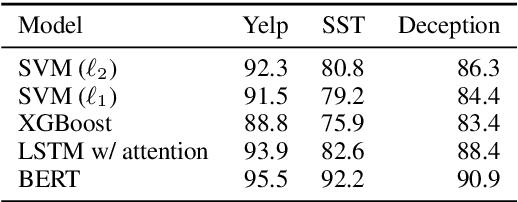

Feature importance is commonly used to explain machine predictions. While feature importance can be derived from a machine learning model with a variety of methods, the consistency of feature importance via different methods remains understudied. In this work, we systematically compare feature importance from built-in mechanisms in a model such as attention values and post-hoc methods that approximate model behavior such as LIME. Using text classification as a testbed, we find that 1) no matter which method we use, important features from traditional models such as SVM and XGBoost are more similar with each other, than with deep learning models; 2) post-hoc methods tend to generate more similar important features for two models than built-in methods. We further demonstrate how such similarity varies across instances. Notably, important features do not always resemble each other better when two models agree on the predicted label than when they disagree.