 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Individual Decision-Making Style: Exploring Behavioral Stylometry in Chess
Aug 02, 2022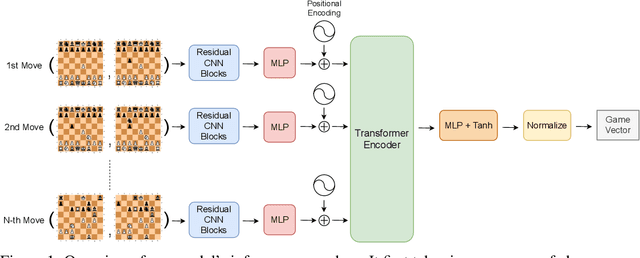
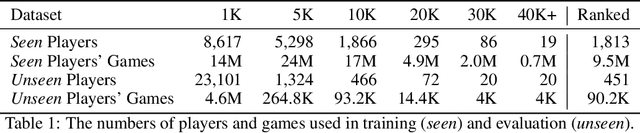
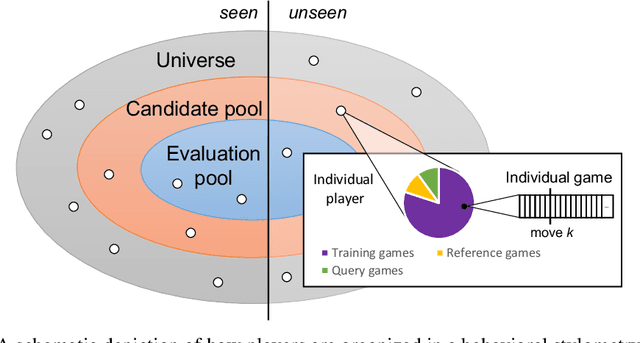
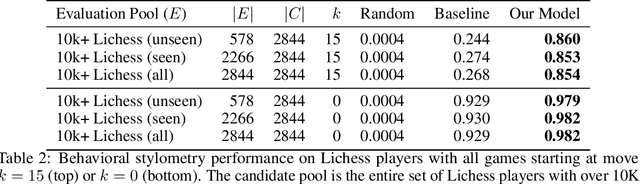
The advent of machine learning models that surpass human decision-making ability in complex domains has initiated a movement towards building AI systems that interact with humans. Many building blocks are essential for this activity, with a central one being the algorithmic characterization of human behavior. While much of the existing work focuses on aggregate human behavior, an important long-range goal is to develop behavioral models that specialize to individual people and can differentiate among them. To formalize this process, we study the problem of behavioral stylometry, in which the task is to identify a decision-maker from their decisions alone. We present a transformer-based approach to behavioral stylometry in the context of chess, where one attempts to identify the player who played a set of games. Our method operates in a few-shot classification framework, and can correctly identify a player from among thousands of candidate players with 98% accuracy given only 100 labeled games. Even when trained on amateur play, our method generalises to out-of-distribution samples of Grandmaster players, despite the dramatic differences between amateur and world-class players. Finally, we consider more broadly what our resulting embeddings reveal about human style in chess, as well as the potential ethical implications of powerful methods for identifying individuals from behavioral data.
Mimetic Models: Ethical Implications of AI that Acts Like You
Jul 19, 2022An emerging theme in artificial intelligence research is the creation of models to simulate the decisions and behavior of specific people, in domains including game-playing, text generation, and artistic expression. These models go beyond earlier approaches in the way they are tailored to individuals, and the way they are designed for interaction rather than simply the reproduction of fixed, pre-computed behaviors. We refer to these as mimetic models, and in this paper we develop a framework for characterizing the ethical and social issues raised by their growing availability. Our framework includes a number of distinct scenarios for the use of such models, and considers the impacts on a range of different participants, including the target being modeled, the operator who deploys the model, and the entities that interact with it.
Core-periphery Models for Hypergraphs
Jun 01, 2022



We introduce a random hypergraph model for core-periphery structure. By leveraging our model's sufficient statistics, we develop a novel statistical inference algorithm that is able to scale to large hypergraphs with runtime that is practically linear wrt. the number of nodes in the graph after a preprocessing step that is almost linear in the number of hyperedges, as well as a scalable sampling algorithm. Our inference algorithm is capable of learning embeddings that correspond to the reputation (rank) of a node within the hypergraph. We also give theoretical bounds on the size of the core of hypergraphs generated by our model. We experiment with hypergraph data that range to $\sim 10^5$ hyperedges mined from the Microsoft Academic Graph, Stack Exchange, and GitHub and show that our model outperforms baselines wrt. producing good fits.
Learning to Reason with Neural Networks: Generalization, Unseen Data and Boolean Measures
May 26, 2022
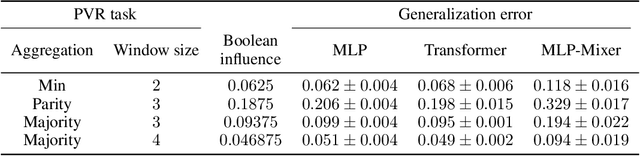
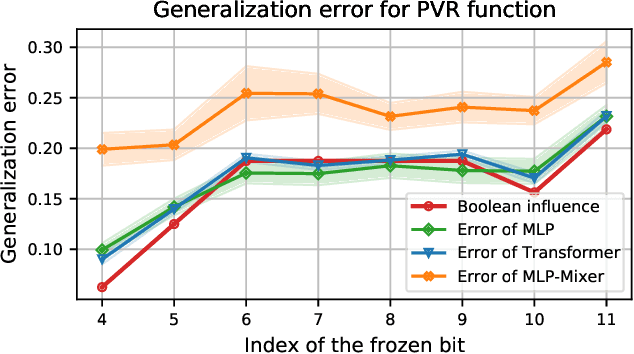
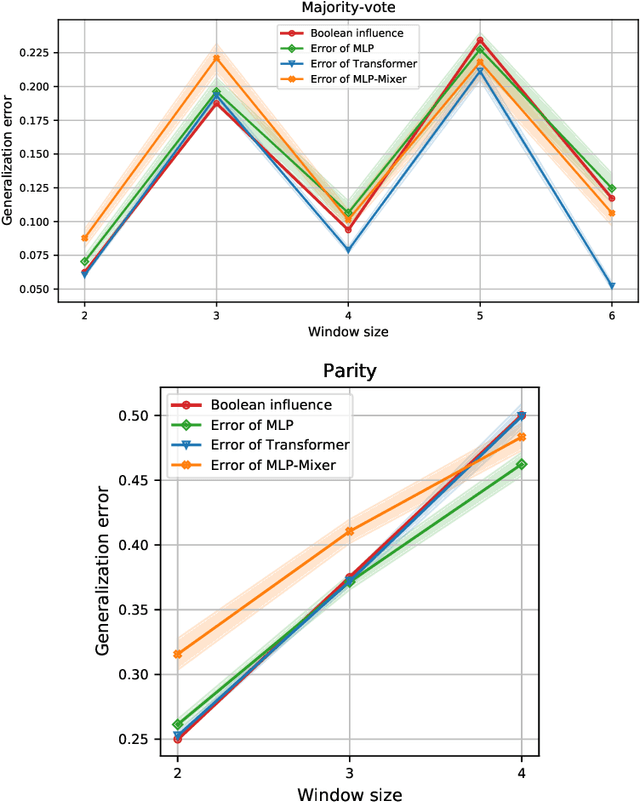
This paper considers the Pointer Value Retrieval (PVR) benchmark introduced in [ZRKB21], where a 'reasoning' function acts on a string of digits to produce the label. More generally, the paper considers the learning of logical functions with gradient descent (GD) on neural networks. It is first shown that in order to learn logical functions with gradient descent on symmetric neural networks, the generalization error can be lower-bounded in terms of the noise-stability of the target function, supporting a conjecture made in [ZRKB21]. It is then shown that in the distribution shift setting, when the data withholding corresponds to freezing a single feature (referred to as canonical holdout), the generalization error of gradient descent admits a tight characterization in terms of the Boolean influence for several relevant architectures. This is shown on linear models and supported experimentally on other models such as MLPs and Transformers. In particular, this puts forward the hypothesis that for such architectures and for learning logical functions such as PVR functions, GD tends to have an implicit bias towards low-degree representations, which in turn gives the Boolean influence for the generalization error under quadratic loss.
Models of fairness in federated learning
Dec 01, 2021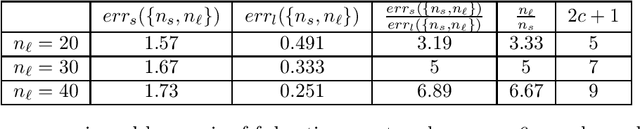
In many real-world situations, data is distributed across multiple locations and can't be combined for training. Federated learning is a novel distributed learning approach that allows multiple federating agents to jointly learn a model. While this approach might reduce the error each agent experiences, it also raises questions of fairness: to what extent can the error experienced by one agent be significantly lower than the error experienced by another agent? In this work, we consider two notions of fairness that each may be appropriate in different circumstances: "egalitarian fairness" (which aims to bound how dissimilar error rates can be) and "proportional fairness" (which aims to reward players for contributing more data). For egalitarian fairness, we obtain a tight multiplicative bound on how widely error rates can diverge between agents federating together. For proportional fairness, we show that sub-proportional error (relative to the number of data points contributed) is guaranteed for any individually rational federating coalition.
Approximate Decomposable Submodular Function Minimization for Cardinality-Based Components
Oct 28, 2021



Minimizing a sum of simple submodular functions of limited support is a special case of general submodular function minimization that has seen numerous applications in machine learning. We develop fast techniques for instances where components in the sum are cardinality-based, meaning they depend only on the size of the input set. This variant is one of the most widely applied in practice, encompassing, e.g., common energy functions arising in image segmentation and recent generalized hypergraph cut functions. We develop the first approximation algorithms for this problem, where the approximations can be quickly computed via reduction to a sparse graph cut problem, with graph sparsity controlled by the desired approximation factor. Our method relies on a new connection between sparse graph reduction techniques and piecewise linear approximations to concave functions. Our sparse reduction technique leads to significant improvements in theoretical runtimes, as well as substantial practical gains in problems ranging from benchmark image segmentation tasks to hypergraph clustering problems.
Pointer Value Retrieval: A new benchmark for understanding the limits of neural network generalization
Jul 27, 2021
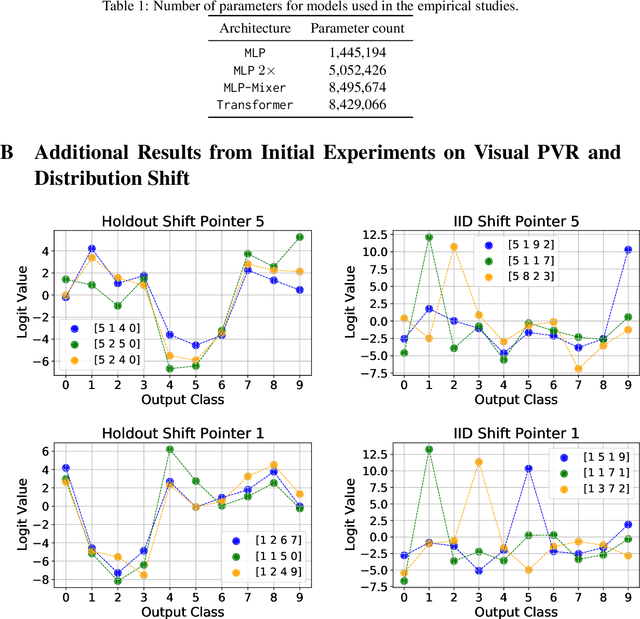

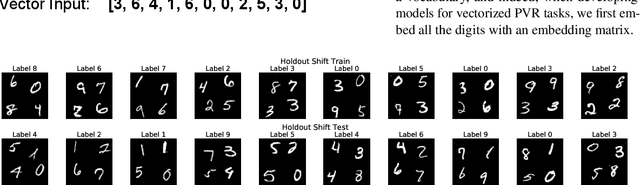
The successes of deep learning critically rely on the ability of neural networks to output meaningful predictions on unseen data -- generalization. Yet despite its criticality, there remain fundamental open questions on how neural networks generalize. How much do neural networks rely on memorization -- seeing highly similar training examples -- and how much are they capable of human-intelligence styled reasoning -- identifying abstract rules underlying the data? In this paper we introduce a novel benchmark, Pointer Value Retrieval (PVR) tasks, that explore the limits of neural network generalization. While PVR tasks can consist of visual as well as symbolic inputs, each with varying levels of difficulty, they all have a simple underlying rule. One part of the PVR task input acts as a pointer, giving the location of a different part of the input, which forms the value (and output). We demonstrate that this task structure provides a rich testbed for understanding generalization, with our empirical study showing large variations in neural network performance based on dataset size, task complexity and model architecture. The interaction of position, values and the pointer rule also allow the development of nuanced tests of generalization, by introducing distribution shift and increasing functional complexity. These reveal both subtle failures and surprising successes, suggesting many promising directions of exploration on this benchmark.
Using a Cross-Task Grid of Linear Probes to Interpret CNN Model Predictions On Retinal Images
Jul 23, 2021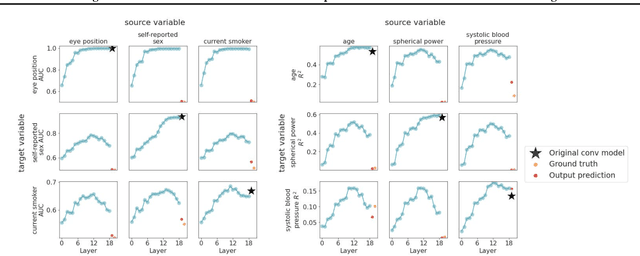
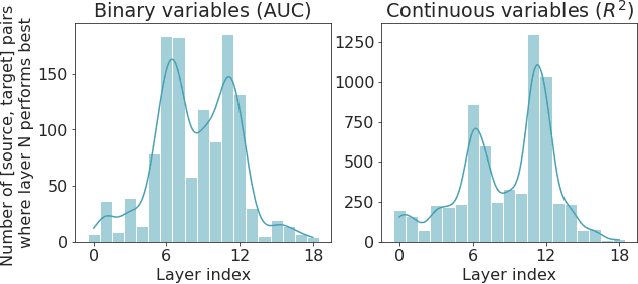
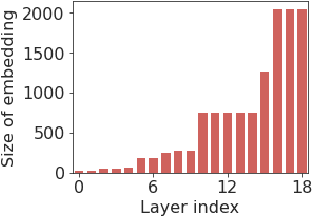
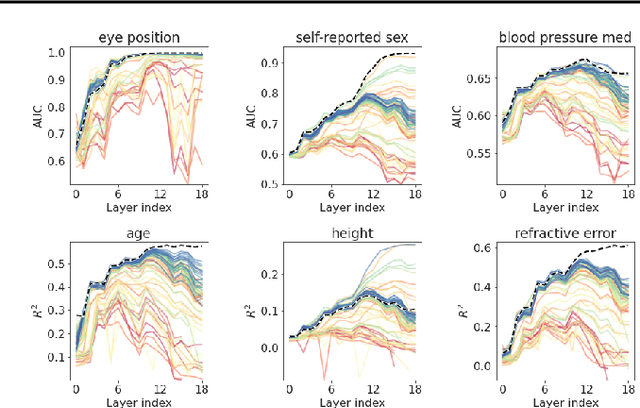
We analyze a dataset of retinal images using linear probes: linear regression models trained on some "target" task, using embeddings from a deep convolutional (CNN) model trained on some "source" task as input. We use this method across all possible pairings of 93 tasks in the UK Biobank dataset of retinal images, leading to ~164k different models. We analyze the performance of these linear probes by source and target task and by layer depth. We observe that representations from the middle layers of the network are more generalizable. We find that some target tasks are easily predicted irrespective of the source task, and that some other target tasks are more accurately predicted from correlated source tasks than from embeddings trained on the same task.
Optimality and Stability in Federated Learning: A Game-theoretic Approach
Jun 17, 2021

Federated learning is a distributed learning paradigm where multiple agents, each only with access to local data, jointly learn a global model. There has recently been an explosion of research aiming not only to improve the accuracy rates of federated learning, but also provide certain guarantees around social good properties such as total error. One branch of this research has taken a game-theoretic approach, and in particular, prior work has viewed federated learning as a hedonic game, where error-minimizing players arrange themselves into federating coalitions. This past work proves the existence of stable coalition partitions, but leaves open a wide range of questions, including how far from optimal these stable solutions are. In this work, we motivate and define a notion of optimality given by the average error rates among federating agents (players). First, we provide and prove the correctness of an efficient algorithm to calculate an optimal (error minimizing) arrangement of players. Next, we analyze the relationship between the stability and optimality of an arrangement. First, we show that for some regions of parameter space, all stable arrangements are optimal (Price of Anarchy equal to 1). However, we show this is not true for all settings: there exist examples of stable arrangements with higher cost than optimal (Price of Anarchy greater than 1). Finally, we give the first constant-factor bound on the performance gap between stability and optimality, proving that the total error of the worst stable solution can be no higher than 9 times the total error of an optimal solution (Price of Anarchy bound of 9).
The Generalized Mean Densest Subgraph Problem
Jun 04, 2021



Finding dense subgraphs of a large graph is a standard problem in graph mining that has been studied extensively both for its theoretical richness and its many practical applications. In this paper we introduce a new family of dense subgraph objectives, parameterized by a single parameter $p$, based on computing generalized means of degree sequences of a subgraph. Our objective captures both the standard densest subgraph problem and the maximum $k$-core as special cases, and provides a way to interpolate between and extrapolate beyond these two objectives when searching for other notions of dense subgraphs. In terms of algorithmic contributions, we first show that our objective can be minimized in polynomial time for all $p \geq 1$ using repeated submodular minimization. A major contribution of our work is analyzing the performance of different types of peeling algorithms for dense subgraphs both in theory and practice. We prove that the standard peeling algorithm can perform arbitrarily poorly on our generalized objective, but we then design a more sophisticated peeling method which for $p \geq 1$ has an approximation guarantee that is always at least $1/2$ and converges to 1 as $p \rightarrow \infty$. In practice, we show that this algorithm obtains extremely good approximations to the optimal solution, scales to large graphs, and highlights a range of different meaningful notions of density on graphs coming from numerous domains. Furthermore, it is typically able to approximate the densest subgraph problem better than the standard peeling algorithm, by better accounting for how the removal of one node affects other nodes in its neighborhood.