 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDravidianMultiModality: A Dataset for Multi-modal Sentiment Analysis in Tamil and Malayalam
Jun 09, 2021


Human communication is inherently multimodal and asynchronous. Analyzing human emotions and sentiment is an emerging field of artificial intelligence. We are witnessing an increasing amount of multimodal content in local languages on social media about products and other topics. However, there are not many multimodal resources available for under-resourced Dravidian languages. Our study aims to create a multimodal sentiment analysis dataset for the under-resourced Tamil and Malayalam languages. First, we downloaded product or movies review videos from YouTube for Tamil and Malayalam. Next, we created captions for the videos with the help of annotators. Then we labelled the videos for sentiment, and verified the inter-annotator agreement using Fleiss's Kappa. This is the first multimodal sentiment analysis dataset for Tamil and Malayalam by volunteer annotators.
Contextual Modulation for Relation-Level Metaphor Identification
Oct 12, 2020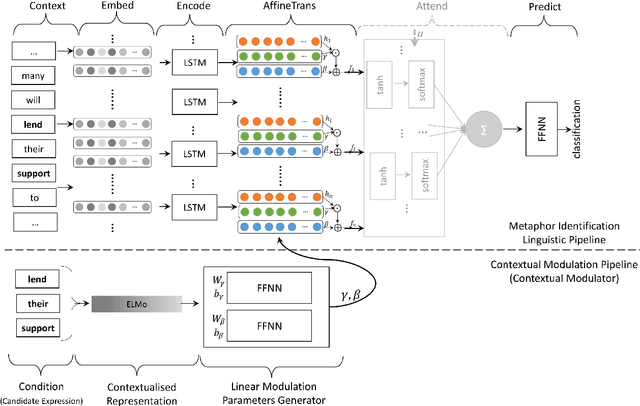
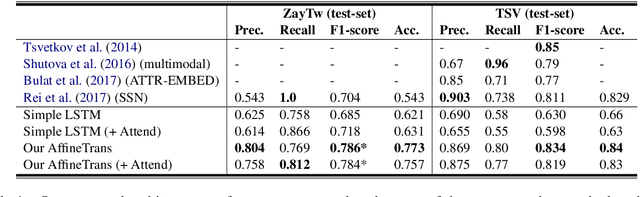

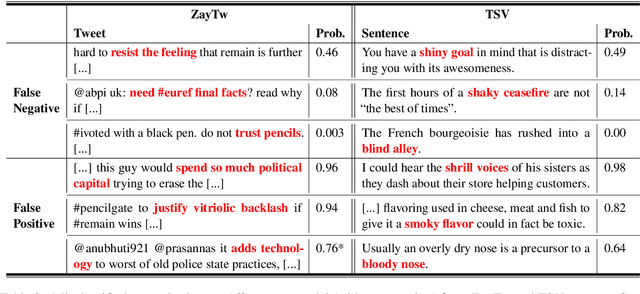
Identifying metaphors in text is very challenging and requires comprehending the underlying comparison. The automation of this cognitive process has gained wide attention lately. However, the majority of existing approaches concentrate on word-level identification by treating the task as either single-word classification or sequential labelling without explicitly modelling the interaction between the metaphor components. On the other hand, while existing relation-level approaches implicitly model this interaction, they ignore the context where the metaphor occurs. In this work, we address these limitations by introducing a novel architecture for identifying relation-level metaphoric expressions of certain grammatical relations based on contextual modulation. In a methodology inspired by works in visual reasoning, our approach is based on conditioning the neural network computation on the deep contextualised features of the candidate expressions using feature-wise linear modulation. We demonstrate that the proposed architecture achieves state-of-the-art results on benchmark datasets. The proposed methodology is generic and could be applied to other textual classification problems that benefit from contextual interaction.
A Survey of Orthographic Information in Machine Translation
Aug 04, 2020Machine translation is one of the applications of natural language processing which has been explored in different languages. Recently researchers started paying attention towards machine translation for resource-poor languages and closely related languages. A widespread and underlying problem for these machine translation systems is the variation in orthographic conventions which causes many issues to traditional approaches. Two languages written in two different orthographies are not easily comparable, but orthographic information can also be used to improve the machine translation system. This article offers a survey of research regarding orthography's influence on machine translation of under-resourced languages. It introduces under-resourced languages in terms of machine translation and how orthographic information can be utilised to improve machine translation. We describe previous work in this area, discussing what underlying assumptions were made, and showing how orthographic knowledge improves the performance of machine translation of under-resourced languages. We discuss different types of machine translation and demonstrate a recent trend that seeks to link orthographic information with well-established machine translation methods. Considerable attention is given to current efforts of cognates information at different levels of machine translation and the lessons that can be drawn from this. Additionally, multilingual neural machine translation of closely related languages is given a particular focus in this survey. This article ends with a discussion of the way forward in machine translation with orthographic information, focusing on multilingual settings and bilingual lexicon induction.
ULD@NUIG at SemEval-2020 Task 9: Generative Morphemes with an Attention Model for Sentiment Analysis in Code-Mixed Text
Jul 27, 2020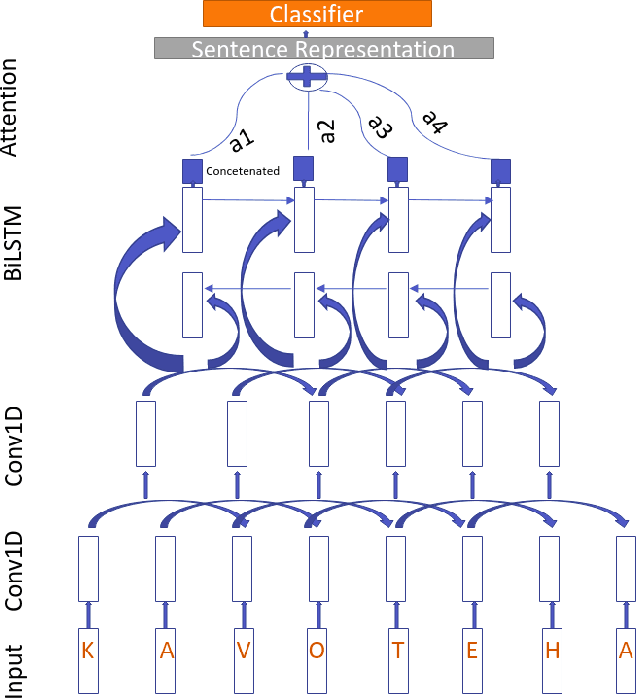
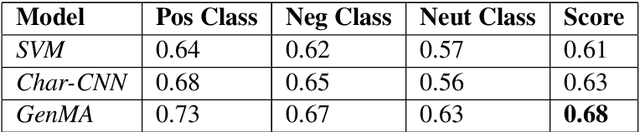
Code mixing is a common phenomena in multilingual societies where people switch from one language to another for various reasons. Recent advances in public communication over different social media sites have led to an increase in the frequency of code-mixed usage in written language. In this paper, we present the Generative Morphemes with Attention (GenMA) Model sentiment analysis system contributed to SemEval 2020 Task 9 SentiMix. The system aims to predict the sentiments of the given English-Hindi code-mixed tweets without using word-level language tags instead inferring this automatically using a morphological model. The system is based on a novel deep neural network (DNN) architecture, which has outperformed the baseline F1-score on the test data-set as well as the validation data-set. Our results can be found under the user name "koustava" on the "Sentimix Hindi English" page
A Sentiment Analysis Dataset for Code-Mixed Malayalam-English
May 30, 2020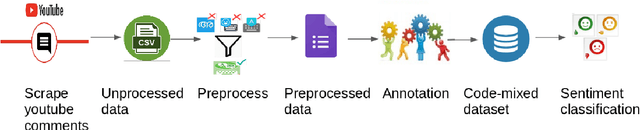
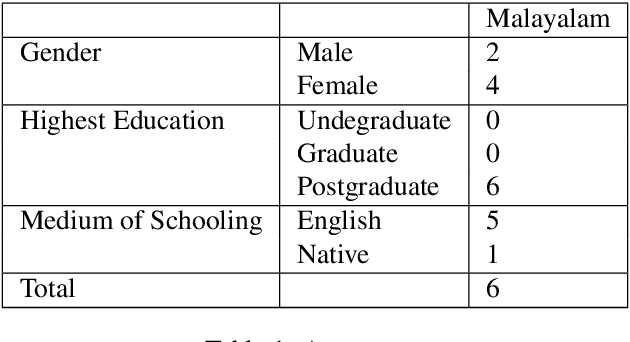
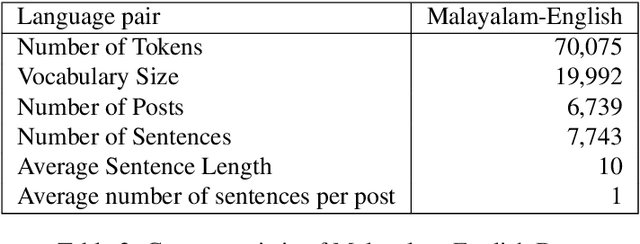

There is an increasing demand for sentiment analysis of text from social media which are mostly code-mixed. Systems trained on monolingual data fail for code-mixed data due to the complexity of mixing at different levels of the text. However, very few resources are available for code-mixed data to create models specific for this data. Although much research in multilingual and cross-lingual sentiment analysis has used semi-supervised or unsupervised methods, supervised methods still performs better. Only a few datasets for popular languages such as English-Spanish, English-Hindi, and English-Chinese are available. There are no resources available for Malayalam-English code-mixed data. This paper presents a new gold standard corpus for sentiment analysis of code-mixed text in Malayalam-English annotated by voluntary annotators. This gold standard corpus obtained a Krippendorff's alpha above 0.8 for the dataset. We use this new corpus to provide the benchmark for sentiment analysis in Malayalam-English code-mixed texts.
Corpus Creation for Sentiment Analysis in Code-Mixed Tamil-English Text
May 30, 2020

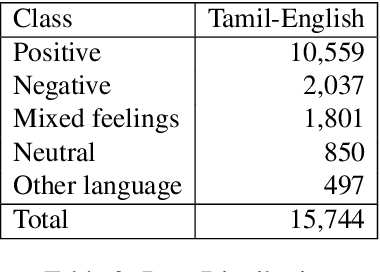
Understanding the sentiment of a comment from a video or an image is an essential task in many applications. Sentiment analysis of a text can be useful for various decision-making processes. One such application is to analyse the popular sentiments of videos on social media based on viewer comments. However, comments from social media do not follow strict rules of grammar, and they contain mixing of more than one language, often written in non-native scripts. Non-availability of annotated code-mixed data for a low-resourced language like Tamil also adds difficulty to this problem. To overcome this, we created a gold standard Tamil-English code-switched, sentiment-annotated corpus containing 15,744 comment posts from YouTube. In this paper, we describe the process of creating the corpus and assigning polarities. We present inter-annotator agreement and show the results of sentiment analysis trained on this corpus as a benchmark.
Classification Benchmarks for Under-resourced Bengali Language based on Multichannel Convolutional-LSTM Network
Apr 19, 2020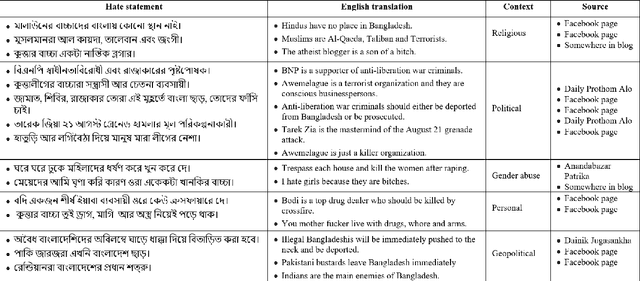
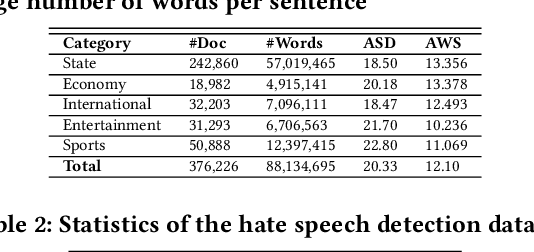
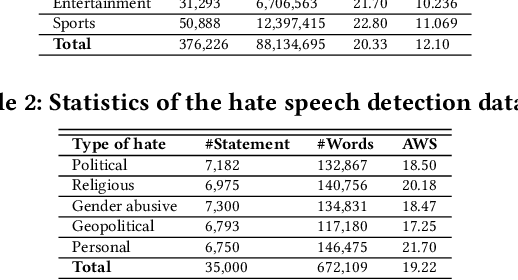
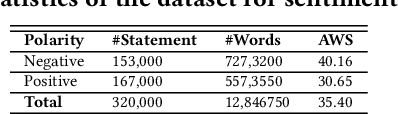
Exponential growths of social media and micro-blogging sites not only provide platforms for empowering freedom of expressions and individual voices but also enables people to express anti-social behaviour like online harassment, cyberbullying, and hate speech. Numerous works have been proposed to utilize these data for social and anti-social behaviours analysis, document characterization, and sentiment analysis by predicting the contexts mostly for highly resourced languages such as English. However, there are languages that are under-resources, e.g., South Asian languages like Bengali, Tamil, Assamese, Telugu that lack of computational resources for the NLP tasks. In this paper, we provide several classification benchmarks for Bengali, an under-resourced language. We prepared three datasets of expressing hate, commonly used topics, and opinions for hate speech detection, document classification, and sentiment analysis, respectively. We built the largest Bengali word embedding models to date based on 250 million articles, which we call BengFastText. We perform three different experiments, covering document classification, sentiment analysis, and hate speech detection. We incorporate word embeddings into a Multichannel Convolutional-LSTM (MConv-LSTM) network for predicting different types of hate speech, document classification, and sentiment analysis. Experiments demonstrate that BengFastText can capture the semantics of words from respective contexts correctly. Evaluations against several baseline embedding models, e.g., Word2Vec and GloVe yield up to 92.30%, 82.25%, and 90.45% F1-scores in case of document classification, sentiment analysis, and hate speech detection, respectively during 5-fold cross-validation tests.
Towards an Interoperable Ecosystem of AI and LT Platforms: A Roadmap for the Implementation of Different Levels of Interoperability
Apr 17, 2020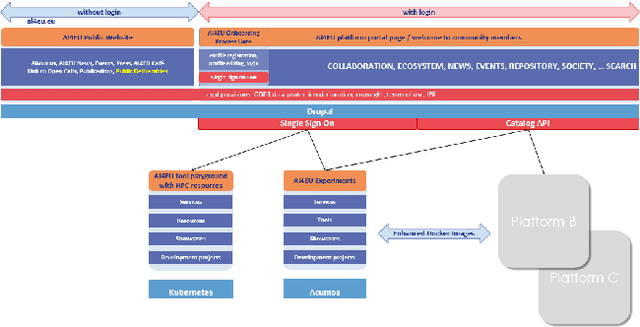
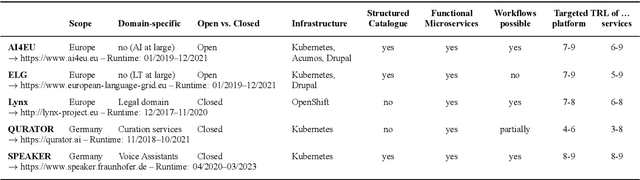

With regard to the wider area of AI/LT platform interoperability, we concentrate on two core aspects: (1) cross-platform search and discovery of resources and services; (2) composition of cross-platform service workflows. We devise five different levels (of increasing complexity) of platform interoperability that we suggest to implement in a wider federation of AI/LT platforms. We illustrate the approach using the five emerging AI/LT platforms AI4EU, ELG, Lynx, QURATOR and SPEAKER.
Temporal Analysis of Entity Relatedness and its Evolution using Wikipedia and DBpedia
Dec 12, 2018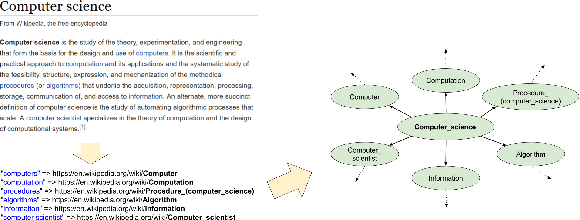
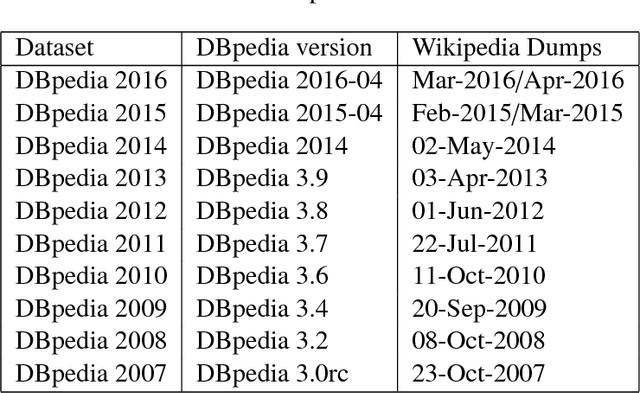
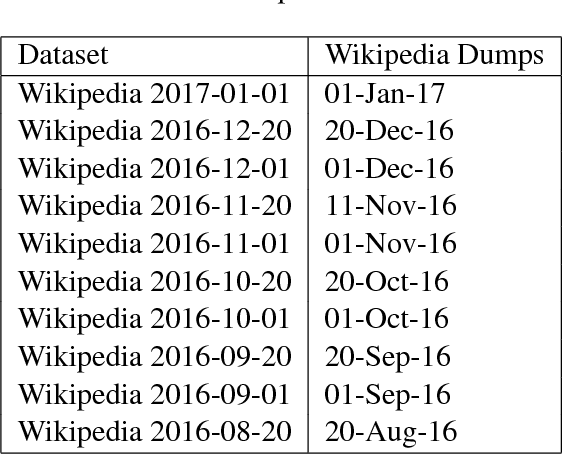
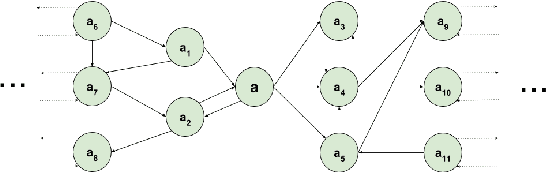
Many researchers have made use of the Wikipedia network for relatedness and similarity tasks. However, most approaches use only the most recent information and not historical changes in the network. We provide an analysis of entity relatedness using temporal graph-based approaches over different versions of the Wikipedia article link network and DBpedia, which is an open-source knowledge base extracted from Wikipedia. We consider creating the Wikipedia article link network as both a union and intersection of edges over multiple time points and present a novel variation of the Jaccard index to weight edges based on their transience. We evaluate our results against the KORE dataset, which was created in 2010, and show that using the 2010 Wikipedia article link network produces the strongest result, suggesting that semantic similarity is time sensitive. We then show that integrating multiple time frames in our methods can give a better overall similarity demonstrating that temporal evolution can have an important effect on entity relatedness.