 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Fool Me Twice: Adapting to Adversity in the Wild with Experience-Driven Reasoning
May 29, 2026In robotics, dangers and adversity modes are often embodiment-specific and relative to each agent. A frontier of autonomous mobile robotics is to enable agents to operate effectively in the wild in unseen unstructured environments. A significant challenge in unseen unstructured environments is that it may not be possible to predict all the dangers to the specific robot. Although recent work has used large foundation vision-language models (VLMs) to preemptively predict an exhaustive list of common-sense dangers, it remains difficult to capture possible interaction and embodiment-dependent adversities. We propose a continual learning framework for a mobile embodied agent to learn online from disturbances and attribute anomalous behaviours to causes through semantics, enabling better prediction and planning of the world in the future. Our framework, "Don't Fool Me Twice", first observes disturbances and describes their effects on the robot; this description is augmented with visual context to query a VLM to predict possible causes; the local disturbance is characterized using kernel regression, which allows for efficient, few-shot modeling of transient anomalies. We leverage semantic voxel-centric modeling to estimate epistemic uncertainty, enabling richer downstream recovery by treating interaction-driven disturbances as learnable spatial behaviors. We present four hypotheses and validate them in simulation and on hardware across embodiments and adversity modes.
sense2vec - A Fast and Accurate Method for Word Sense Disambiguation In Neural Word Embeddings
Nov 19, 2015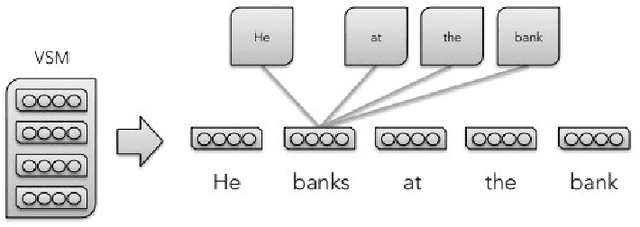
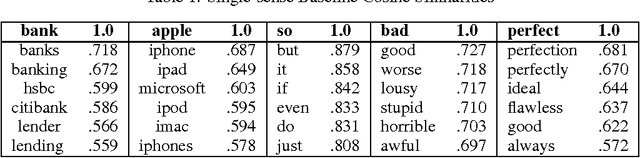
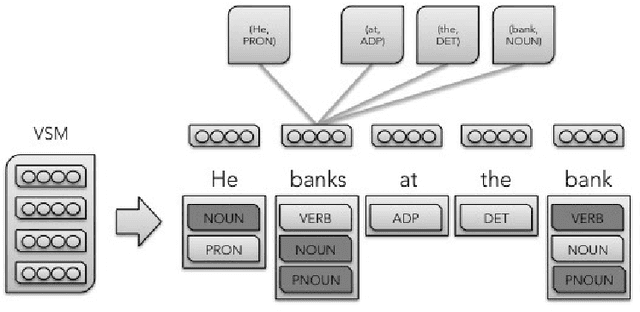
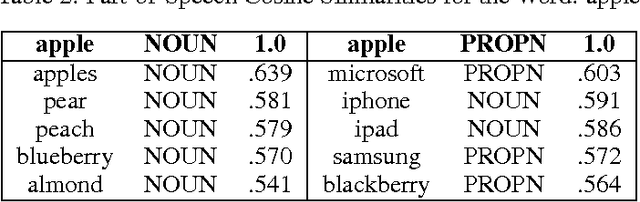
Neural word representations have proven useful in Natural Language Processing (NLP) tasks due to their ability to efficiently model complex semantic and syntactic word relationships. However, most techniques model only one representation per word, despite the fact that a single word can have multiple meanings or "senses". Some techniques model words by using multiple vectors that are clustered based on context. However, recent neural approaches rarely focus on the application to a consuming NLP algorithm. Furthermore, the training process of recent word-sense models is expensive relative to single-sense embedding processes. This paper presents a novel approach which addresses these concerns by modeling multiple embeddings for each word based on supervised disambiguation, which provides a fast and accurate way for a consuming NLP model to select a sense-disambiguated embedding. We demonstrate that these embeddings can disambiguate both contrastive senses such as nominal and verbal senses as well as nuanced senses such as sarcasm. We further evaluate Part-of-Speech disambiguated embeddings on neural dependency parsing, yielding a greater than 8% average error reduction in unlabeled attachment scores across 6 languages.