 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance portability through machine learning guided kernel selection in SYCL libraries
Aug 30, 2020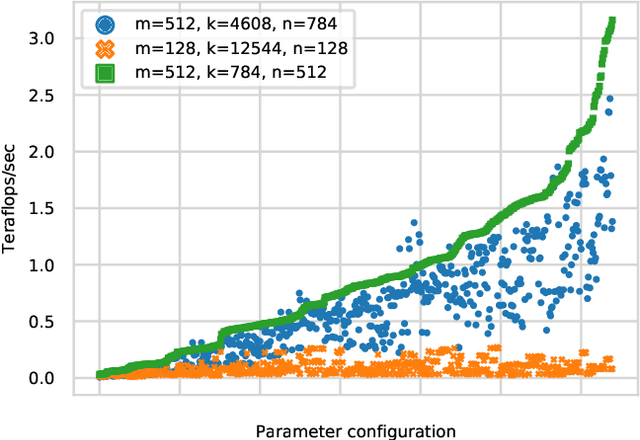
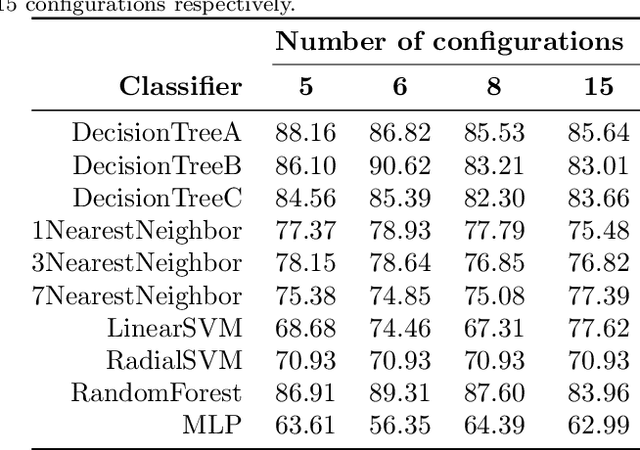
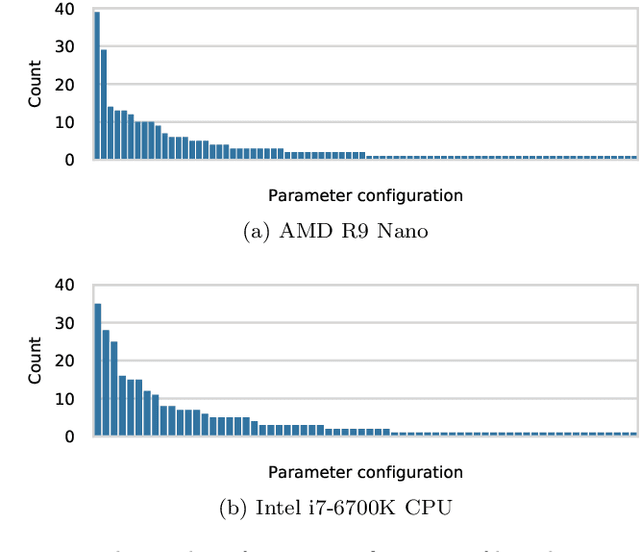

Automatically tuning parallel compute kernels allows libraries and frameworks to achieve performance on a wide range of hardware, however these techniques are typically focused on finding optimal kernel parameters for particular input sizes and parameters. General purpose compute libraries must be able to cater to all inputs and parameters provided by a user, and so these techniques are of limited use. Additionally, parallel programming frameworks such as SYCL require that the kernels be deployed in a binary format embedded within the library. As such it is impractical to deploy a large number of possible kernel configurations without inflating the library size. Machine learning methods can be used to mitigate against both of these problems and provide performance for general purpose routines with a limited number of kernel configurations. We show that unsupervised clustering methods can be used to select a subset of the possible kernels that should be deployed and that simple classification methods can be trained to select from these kernels at runtime to give good performance. As these techniques are fully automated, relying only on benchmark data, the tuning process for new hardware or problems does not require any developer effort or expertise.
Towards automated kernel selection in machine learning systems: A SYCL case study
Mar 15, 2020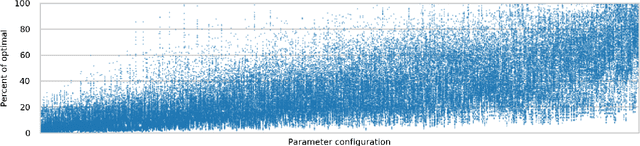
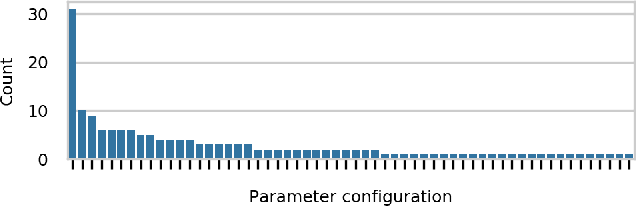
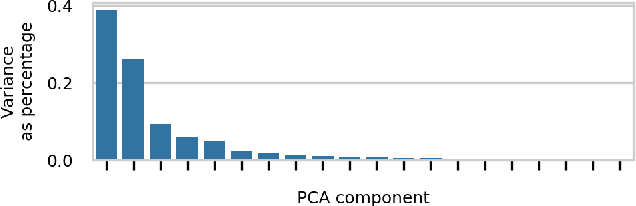
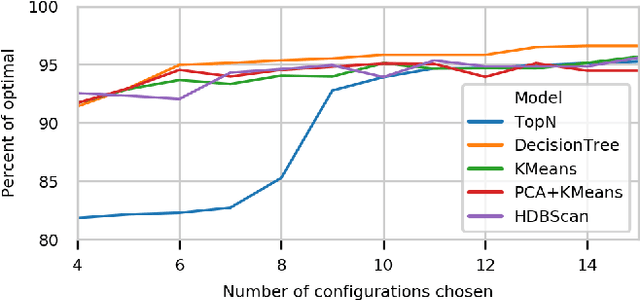
Automated tuning of compute kernels is a popular area of research, mainly focused on finding optimal kernel parameters for a problem with fixed input sizes. This approach is good for deploying machine learning models, where the network topology is constant, but machine learning research often involves changing network topologies and hyperparameters. Traditional kernel auto-tuning has limited impact in this case; a more general selection of kernels is required for libraries to accelerate machine learning research. In this paper we present initial results using machine learning to select kernels in a case study deploying high performance SYCL kernels in libraries that target a range of heterogeneous devices from desktop GPUs to embedded accelerators. The techniques investigated apply more generally and could similarly be integrated with other heterogeneous programming systems. By combining auto-tuning and machine learning these kernel selection processes can be deployed with little developer effort to achieve high performance on new hardware.
Cross-Platform Performance Portability Using Highly Parametrized SYCL Kernels
Apr 10, 2019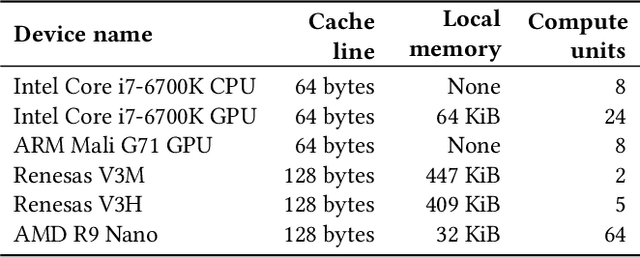
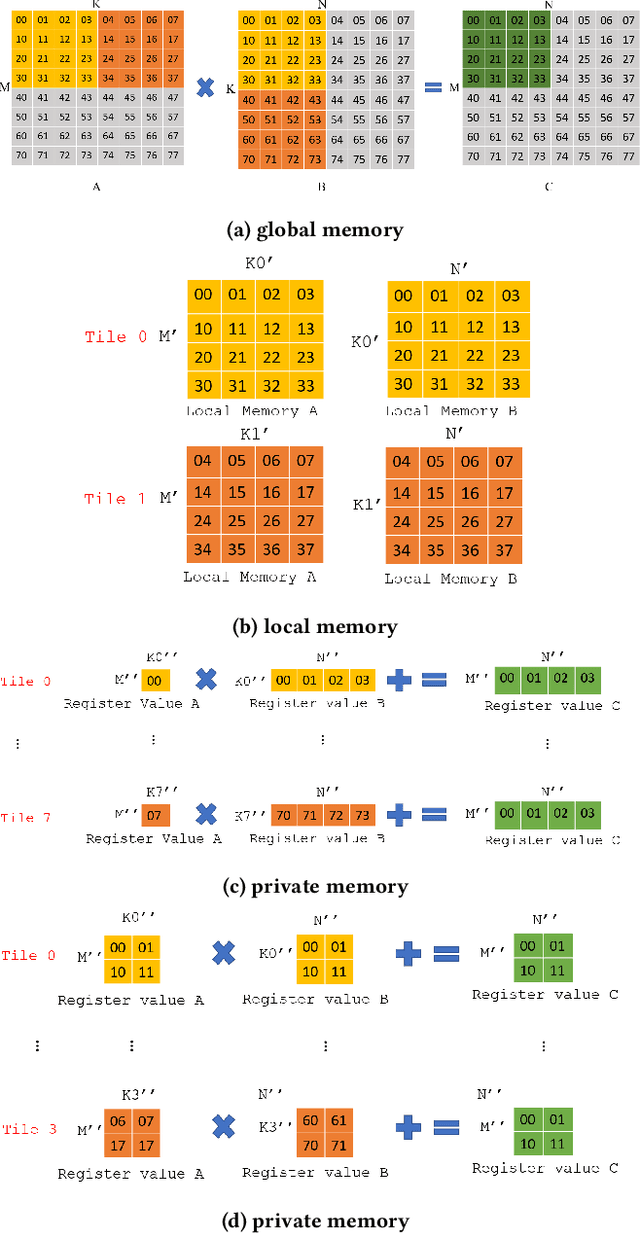
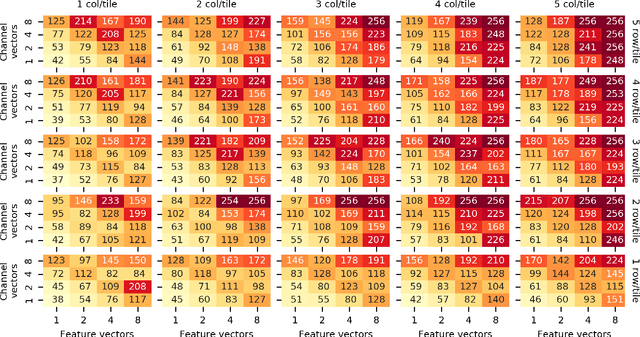
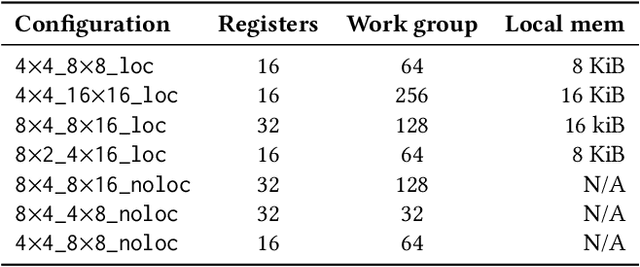
Over recent years heterogeneous systems have become more prevalent across HPC systems, with over 100 supercomputers in the TOP500 incorporating GPUs or other accelerators. These hardware platforms have different performance characteristics and optimization requirements. In order to make the most of multiple accelerators a developer has to provide implementations of their algorithms tuned for each device. Hardware vendors provide libraries targeting their devices specifically, which provide good performance but frequently have different API designs, hampering portability. The SYCL programming model allows users to write heterogeneous programs using completely standard C++, and so developers have access to the power of C++ templates when developing compute kernels. In this paper we show that by writing highly parameterized kernels for matrix multiplies and convolutions we achieve performance competitive with vendor implementations across different architectures. Furthermore, tuning for new devices amounts to choosing the combinations of kernel parameters that perform best on the hardware.
Accelerated Neural Networks on OpenCL Devices Using SYCL-DNN
Apr 08, 2019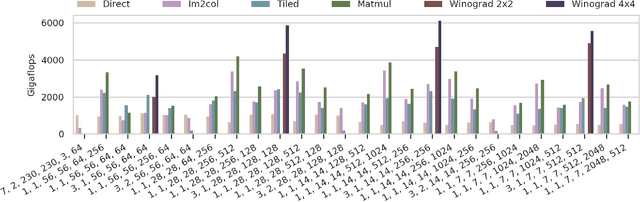

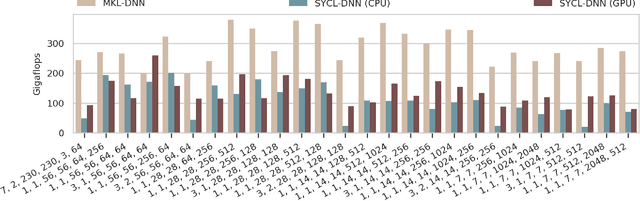
Over the past few years machine learning has seen a renewed explosion of interest, following a number of studies showing the effectiveness of neural networks in a range of tasks which had previously been considered incredibly hard. Neural networks' effectiveness in the fields of image recognition and natural language processing stems primarily from the vast amounts of data available to companies and researchers, coupled with the huge amounts of compute power available in modern accelerators such as GPUs, FPGAs and ASICs. There are a number of approaches available to developers for utilizing GPGPU technologies such as SYCL, OpenCL and CUDA, however many applications require the same low level mathematical routines. Libraries dedicated to accelerating these common routines allow developers to easily make full use of the available hardware without requiring low level knowledge of the hardware themselves, however such libraries are often provided by hardware manufacturers for specific hardware such as cuDNN for Nvidia hardware or MIOpen for AMD hardware. SYCL-DNN is a new open-source library dedicated to providing accelerated routines for neural network operations which are hardware and vendor agnostic. Built on top of the SYCL open standard and written entirely in standard C++, SYCL-DNN allows a user to easily accelerate neural network code for a wide range of hardware using a modern C++ interface. The library is tested on AMD's OpenCL for GPU, Intel's OpenCL for CPU and GPU, ARM's OpenCL for Mali GPUs as well as ComputeAorta's OpenCL for R-Car CV engine and host CPU. In this talk we will present performance figures for SYCL-DNN on this range of hardware, and discuss how high performance was achieved on such a varied set of accelerators with such different hardware features.