 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARB: Advanced Reasoning Benchmark for Large Language Models
Jul 28, 2023



Large Language Models (LLMs) have demonstrated remarkable performance on various quantitative reasoning and knowledge benchmarks. However, many of these benchmarks are losing utility as LLMs get increasingly high scores, despite not yet reaching expert performance in these domains. We introduce ARB, a novel benchmark composed of advanced reasoning problems in multiple fields. ARB presents a more challenging test than prior benchmarks, featuring problems in mathematics, physics, biology, chemistry, and law. As a subset of ARB, we introduce a challenging set of math and physics problems which require advanced symbolic reasoning and domain knowledge. We evaluate recent models such as GPT-4 and Claude on ARB and demonstrate that current models score well below 50% on more demanding tasks. In order to improve both automatic and assisted evaluation capabilities, we introduce a rubric-based evaluation approach, allowing GPT-4 to score its own intermediate reasoning steps. Further, we conduct a human evaluation of the symbolic subset of ARB, finding promising agreement between annotators and GPT-4 rubric evaluation scores.
Large Language Models as Tax Attorneys: A Case Study in Legal Capabilities Emergence
Jun 12, 2023Better understanding of Large Language Models' (LLMs) legal analysis abilities can contribute to improving the efficiency of legal services, governing artificial intelligence, and leveraging LLMs to identify inconsistencies in law. This paper explores LLM capabilities in applying tax law. We choose this area of law because it has a structure that allows us to set up automated validation pipelines across thousands of examples, requires logical reasoning and maths skills, and enables us to test LLM capabilities in a manner relevant to real-world economic lives of citizens and companies. Our experiments demonstrate emerging legal understanding capabilities, with improved performance in each subsequent OpenAI model release. We experiment with retrieving and utilising the relevant legal authority to assess the impact of providing additional legal context to LLMs. Few-shot prompting, presenting examples of question-answer pairs, is also found to significantly enhance the performance of the most advanced model, GPT-4. The findings indicate that LLMs, particularly when combined with prompting enhancements and the correct legal texts, can perform at high levels of accuracy but not yet at expert tax lawyer levels. As LLMs continue to advance, their ability to reason about law autonomously could have significant implications for the legal profession and AI governance.
Large Language Models as Fiduciaries: A Case Study Toward Robustly Communicating With Artificial Intelligence Through Legal Standards
Jan 30, 2023Artificial Intelligence (AI) is taking on increasingly autonomous roles, e.g., browsing the web as a research assistant and managing money. But specifying goals and restrictions for AI behavior is difficult. Similar to how parties to a legal contract cannot foresee every potential "if-then" contingency of their future relationship, we cannot specify desired AI behavior for all circumstances. Legal standards facilitate robust communication of inherently vague and underspecified goals. Instructions (in the case of language models, "prompts") that employ legal standards will allow AI agents to develop shared understandings of the spirit of a directive that generalize expectations regarding acceptable actions to take in unspecified states of the world. Standards have built-in context that is lacking from other goal specification languages, such as plain language and programming languages. Through an empirical study on thousands of evaluation labels we constructed from U.S. court opinions, we demonstrate that large language models (LLMs) are beginning to exhibit an "understanding" of one of the most relevant legal standards for AI agents: fiduciary obligations. Performance comparisons across models suggest that, as LLMs continue to exhibit improved core capabilities, their legal standards understanding will also continue to improve. OpenAI's latest LLM has 78% accuracy on our data, their previous release has 73% accuracy, and a model from their 2020 GPT-3 paper has 27% accuracy (worse than random). Our research is an initial step toward a framework for evaluating AI understanding of legal standards more broadly, and for conducting reinforcement learning with legal feedback (RLLF).
Large Language Models as Corporate Lobbyists
Jan 17, 2023We demonstrate a proof-of-concept of a large language model conducting corporate lobbying related activities. An autoregressive large language model (OpenAI's text-davinci-003) determines if proposed U.S. Congressional bills are relevant to specific public companies and provides explanations and confidence levels. For the bills the model deems as relevant, the model drafts a letter to the sponsor of the bill in an attempt to persuade the congressperson to make changes to the proposed legislation. We use hundreds of novel ground-truth labels of the relevance of a bill to a company to benchmark the performance of the model, which outperforms the baseline of predicting the most common outcome of irrelevance. We also benchmark the performance of the previous OpenAI GPT-3 model (text-davinci-002), which was the state-of-the-art model on many academic natural language tasks until text-davinci-003 was recently released. The performance of text-davinci-002 is worse than a simple benchmark. These results suggest that, as large language models continue to exhibit improved natural language understanding capabilities, performance on lobbying related tasks will continue to improve. Longer-term, if AI begins to influence law in a manner that is not a direct extension of human intentions, this threatens the critical role that law as information could play in aligning AI with humans. Initially, AI is being used to simply augment human lobbyists for a small portion of their daily tasks. However, firms have an incentive to use less and less human oversight over automated assessments of policy ideas and the written communication to regulatory agencies and Congressional staffers. The core question raised is where to draw the line between human-driven and AI-driven policy influence.
Predicting and Understanding Law-Making with Word Vectors and an Ensemble Model
Apr 29, 2017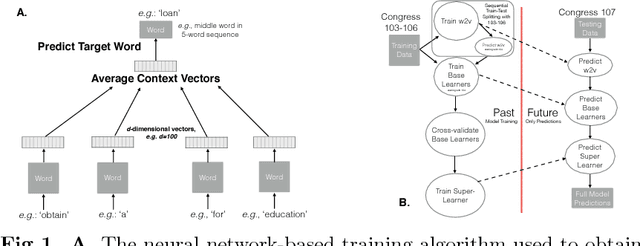



Out of nearly 70,000 bills introduced in the U.S. Congress from 2001 to 2015, only 2,513 were enacted. We developed a machine learning approach to forecasting the probability that any bill will become law. Starting in 2001 with the 107th Congress, we trained models on data from previous Congresses, predicted all bills in the current Congress, and repeated until the 113th Congress served as the test. For prediction we scored each sentence of a bill with a language model that embeds legislative vocabulary into a high-dimensional, semantic-laden vector space. This language representation enables our investigation into which words increase the probability of enactment for any topic. To test the relative importance of text and context, we compared the text model to a context-only model that uses variables such as whether the bill's sponsor is in the majority party. To test the effect of changes to bills after their introduction on our ability to predict their final outcome, we compared using the bill text and meta-data available at the time of introduction with using the most recent data. At the time of introduction context-only predictions outperform text-only, and with the newest data text-only outperforms context-only. Combining text and context always performs best. We conducted a global sensitivity analysis on the combined model to determine important variables predicting enactment.
Gov2Vec: Learning Distributed Representations of Institutions and Their Legal Text
Sep 25, 2016



We compare policy differences across institutions by embedding representations of the entire legal corpus of each institution and the vocabulary shared across all corpora into a continuous vector space. We apply our method, Gov2Vec, to Supreme Court opinions, Presidential actions, and official summaries of Congressional bills. The model discerns meaningful differences between government branches. We also learn representations for more fine-grained word sources: individual Presidents and (2-year) Congresses. The similarities between learned representations of Congresses over time and sitting Presidents are negatively correlated with the bill veto rate, and the temporal ordering of Presidents and Congresses was implicitly learned from only text. With the resulting vectors we answer questions such as: how does Obama and the 113th House differ in addressing climate change and how does this vary from environmental or economic perspectives? Our work illustrates vector-arithmetic-based investigations of complex relationships between word sources based on their texts. We are extending this to create a more comprehensive legal semantic map.
Data-Driven Dynamic Decision Models
Mar 26, 2016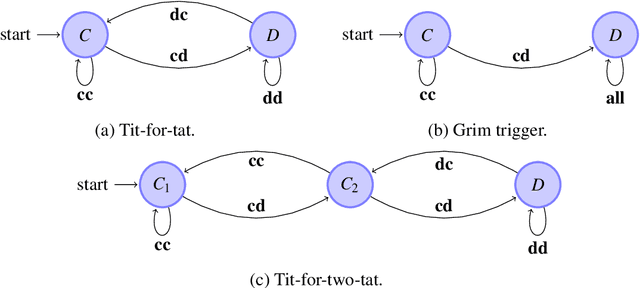
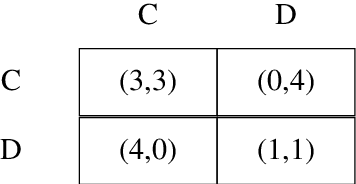


This article outlines a method for automatically generating models of dynamic decision-making that both have strong predictive power and are interpretable in human terms. This is useful for designing empirically grounded agent-based simulations and for gaining direct insight into observed dynamic processes. We use an efficient model representation and a genetic algorithm-based estimation process to generate simple approximations that explain most of the structure of complex stochastic processes. This method, implemented in C++ and R, scales well to large data sets. We apply our methods to empirical data from human subjects game experiments and international relations. We also demonstrate the method's ability to recover known data-generating processes by simulating data with agent-based models and correctly deriving the underlying decision models for multiple agent models and degrees of stochasticity.
* Published in the Proceedings of the 2015 Winter Simulation Conference