 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometrical morphology
Mar 13, 2017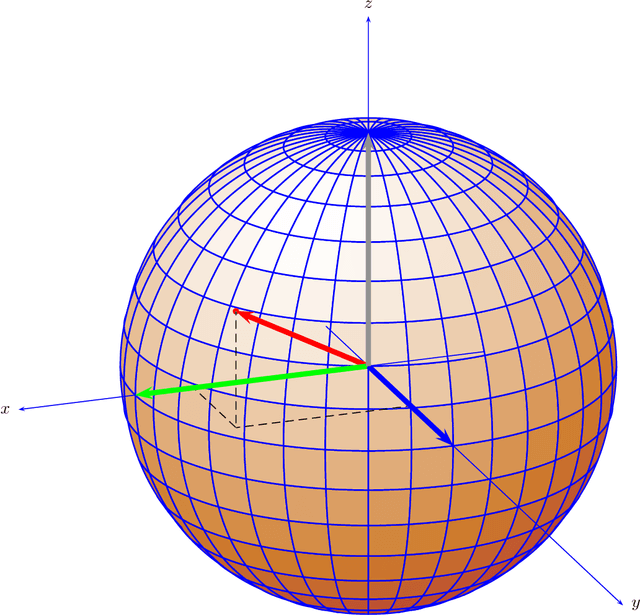



We explore inflectional morphology as an example of the relationship of the discrete and the continuous in linguistics. The grammar requests a form of a lexeme by specifying a set of feature values, which corresponds to a corner M of a hypercube in feature value space. The morphology responds to that request by providing a morpheme, or a set of morphemes, whose vector sum is geometrically closest to the corner M. In short, the chosen morpheme $\mu$ is the morpheme (or set of morphemes) that maximizes the inner product of $\mu$ and M.
Using eigenvectors of the bigram graph to infer morpheme identity
Jul 02, 2002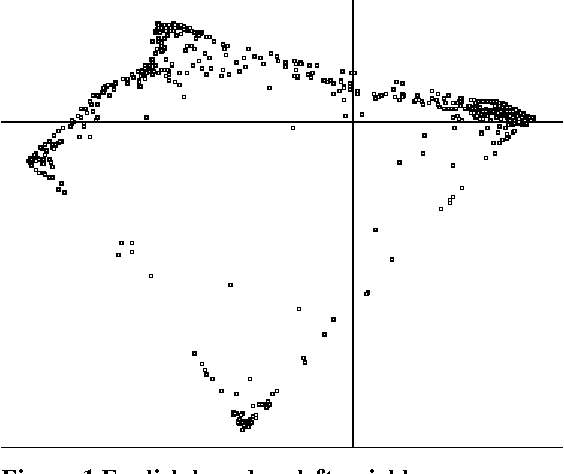
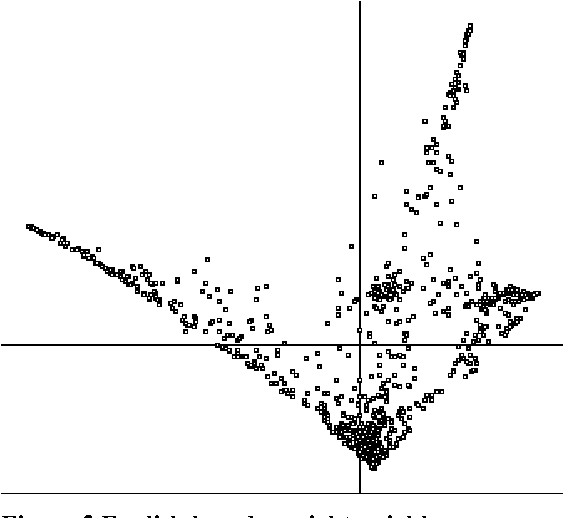
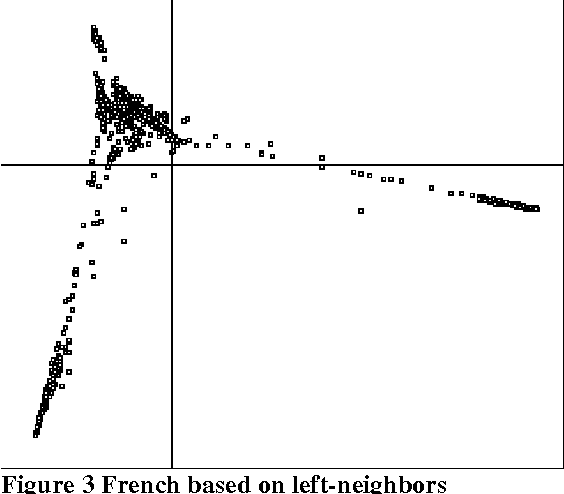
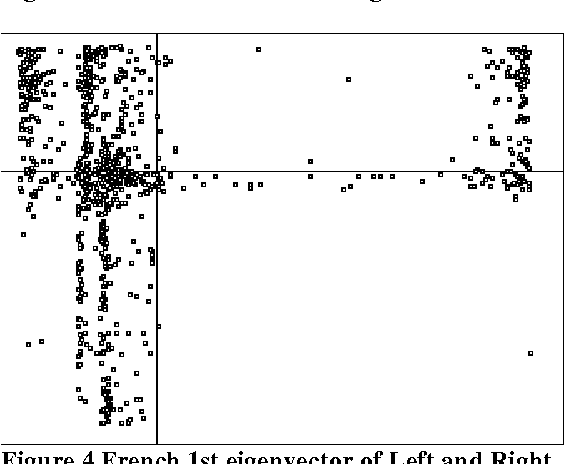
This paper describes the results of some experiments exploring statistical methods to infer syntactic behavior of words and morphemes from a raw corpus in an unsupervised fashion. It shares certain points in common with Brown et al (1992) and work that has grown out of that: it employs statistical techniques to analyze syntactic behavior based on what words occur adjacent to a given word. However, we use an eigenvector decomposition of a nearest-neighbor graph to produce a two-dimensional rendering of the words of a corpus in which words of the same syntactic category tend to form neighborhoods. We exploit this technique for extending the value of automatic learning of morphology. In particular, we look at the suffixes derived from a corpus by unsupervised learning of morphology, and we ask which of these suffixes have a consistent syntactic function (e.g., in English, -tion is primarily a mark of nouns, but -s marks both noun plurals and 3rd person present on verbs), and we determine that this method works well for this task.