 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing Topics with Multi-Word Expressions
Jul 06, 2009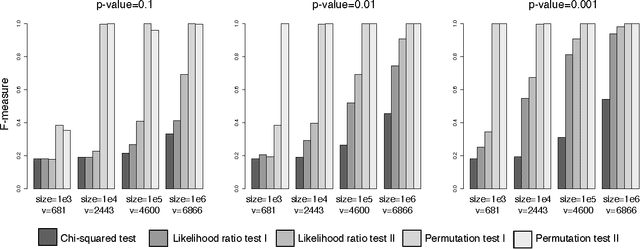
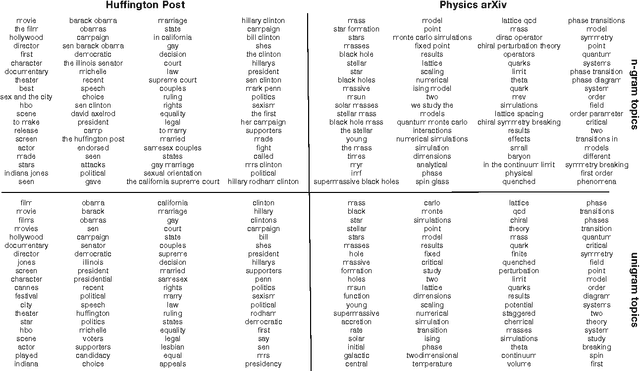
We describe a new method for visualizing topics, the distributions over terms that are automatically extracted from large text corpora using latent variable models. Our method finds significant $n$-grams related to a topic, which are then used to help understand and interpret the underlying distribution. Compared with the usual visualization, which simply lists the most probable topical terms, the multi-word expressions provide a better intuitive impression for what a topic is "about." Our approach is based on a language model of arbitrary length expressions, for which we develop a new methodology based on nested permutation tests to find significant phrases. We show that this method outperforms the more standard use of $\chi^2$ and likelihood ratio tests. We illustrate the topic presentations on corpora of scientific abstracts and news articles.
Cluster Expansions and Iterative Scaling for Maximum Entropy Language Models
Sep 09, 1995The maximum entropy method has recently been successfully introduced to a variety of natural language applications. In each of these applications, however, the power of the maximum entropy method is achieved at the cost of a considerable increase in computational requirements. In this paper we present a technique, closely related to the classical cluster expansion from statistical mechanics, for reducing the computational demands necessary to calculate conditional maximum entropy language models.