 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Aware Probing: From Sentence Length Prediction to Idiom Identification how reliant are Neural Language Models on Topic?
Mar 04, 2024Transformer-based Neural Language Models achieve state-of-the-art performance on various natural language processing tasks. However, an open question is the extent to which these models rely on word-order/syntactic or word co-occurrence/topic-based information when processing natural language. This work contributes to this debate by addressing the question of whether these models primarily use topic as a signal, by exploring the relationship between Transformer-based models' (BERT and RoBERTa's) performance on a range of probing tasks in English, from simple lexical tasks such as sentence length prediction to complex semantic tasks such as idiom token identification, and the sensitivity of these tasks to the topic information. To this end, we propose a novel probing method which we call topic-aware probing. Our initial results indicate that Transformer-based models encode both topic and non-topic information in their intermediate layers, but also that the facility of these models to distinguish idiomatic usage is primarily based on their ability to identify and encode topic. Furthermore, our analysis of these models' performance on other standard probing tasks suggests that tasks that are relatively insensitive to the topic information are also tasks that are relatively difficult for these models.
Analyzing Operator States and the Impact of AI-Enhanced Decision Support in Control Rooms: A Human-in-the-Loop Specialized Reinforcement Learning Framework for Intervention Strategies
Feb 20, 2024In complex industrial and chemical process control rooms, effective decision-making is crucial for safety and efficiency. The experiments in this paper evaluate the impact and applications of an AI-based decision support system integrated into an improved human-machine interface, using dynamic influence diagrams, a hidden Markov model, and deep reinforcement learning. The enhanced support system aims to reduce operator workload, improve situational awareness, and provide different intervention strategies to the operator adapted to the current state of both the system and human performance. Such a system can be particularly useful in cases of information overload when many alarms and inputs are presented all within the same time window, or for junior operators during training. A comprehensive cross-data analysis was conducted, involving 47 participants and a diverse range of data sources such as smartwatch metrics, eye-tracking data, process logs, and responses from questionnaires. The results indicate interesting insights regarding the effectiveness of the approach in aiding decision-making, decreasing perceived workload, and increasing situational awareness for the scenarios considered. Additionally, the results provide valuable insights to compare differences between styles of information gathering when using the system by individual participants. These findings are particularly relevant when predicting the overall performance of the individual participant and their capacity to successfully handle a plant upset and the alarms connected to it using process and human-machine interaction logs in real-time. These predictions enable the development of more effective intervention strategies.
TWIG: Towards pre-hoc Hyperparameter Optimisation and Cross-Graph Generalisation via Simulated KGE Models
Feb 08, 2024



In this paper we introduce TWIG (Topologically-Weighted Intelligence Generation), a novel, embedding-free paradigm for simulating the output of KGEs that uses a tiny fraction of the parameters. TWIG learns weights from inputs that consist of topological features of the graph data, with no coding for latent representations of entities or edges. Our experiments on the UMLS dataset show that a single TWIG neural network can predict the results of state-of-the-art ComplEx-N3 KGE model nearly exactly on across all hyperparameter configurations. To do this it uses a total of 2590 learnable parameters, but accurately predicts the results of 1215 different hyperparameter combinations with a combined cost of 29,322,000 parameters. Based on these results, we make two claims: 1) that KGEs do not learn latent semantics, but only latent representations of structural patterns; 2) that hyperparameter choice in KGEs is a deterministic function of the KGE model and graph structure. We further hypothesise that, as TWIG can simulate KGEs without embeddings, that node and edge embeddings are not needed to learn to accurately predict new facts in KGs. Finally, we formulate all of our findings under the umbrella of the ``Structural Generalisation Hypothesis", which suggests that ``twiggy" embedding-free / data-structure-based learning methods can allow a single neural network to simulate KGE performance, and perhaps solve the Link Prediction task, across many KGs from diverse domains and with different semantics.
Hierarchical Framework for Interpretable and Probabilistic Model-Based Safe Reinforcement Learning
Oct 28, 2023



The difficulty of identifying the physical model of complex systems has led to exploring methods that do not rely on such complex modeling of the systems. Deep reinforcement learning has been the pioneer for solving this problem without the need for relying on the physical model of complex systems by just interacting with it. However, it uses a black-box learning approach that makes it difficult to be applied within real-world and safety-critical systems without providing explanations of the actions derived by the model. Furthermore, an open research question in deep reinforcement learning is how to focus the policy learning of critical decisions within a sparse domain. This paper proposes a novel approach for the use of deep reinforcement learning in safety-critical systems. It combines the advantages of probabilistic modeling and reinforcement learning with the added benefits of interpretability and works in collaboration and synchronization with conventional decision-making strategies. The BC-SRLA is activated in specific situations which are identified autonomously through the fused information of probabilistic model and reinforcement learning, such as abnormal conditions or when the system is near-to-failure. Further, it is initialized with a baseline policy using policy cloning to allow minimum interactions with the environment to address the challenges associated with using RL in safety-critical industries. The effectiveness of the BC-SRLA is demonstrated through a case study in maintenance applied to turbofan engines, where it shows superior performance to the prior art and other baselines.
* arXiv admin note: text overlap with arXiv:2206.13433
Domain Terminology Integration into Machine Translation: Leveraging Large Language Models
Oct 22, 2023This paper discusses the methods that we used for our submissions to the WMT 2023 Terminology Shared Task for German-to-English (DE-EN), English-to-Czech (EN-CS), and Chinese-to-English (ZH-EN) language pairs. The task aims to advance machine translation (MT) by challenging participants to develop systems that accurately translate technical terms, ultimately enhancing communication and understanding in specialised domains. To this end, we conduct experiments that utilise large language models (LLMs) for two purposes: generating synthetic bilingual terminology-based data, and post-editing translations generated by an MT model through incorporating pre-approved terms. Our system employs a four-step process: (i) using an LLM to generate bilingual synthetic data based on the provided terminology, (ii) fine-tuning a generic encoder-decoder MT model, with a mix of the terminology-based synthetic data generated in the first step and a randomly sampled portion of the original generic training data, (iii) generating translations with the fine-tuned MT model, and (iv) finally, leveraging an LLM for terminology-constrained automatic post-editing of the translations that do not include the required terms. The results demonstrate the effectiveness of our proposed approach in improving the integration of pre-approved terms into translations. The number of terms incorporated into the translations of the blind dataset increases from an average of 36.67% with the generic model to an average of 72.88% by the end of the process. In other words, successful utilisation of terms nearly doubles across the three language pairs.
Specialized Deep Residual Policy Safe Reinforcement Learning-Based Controller for Complex and Continuous State-Action Spaces
Oct 15, 2023



Traditional controllers have limitations as they rely on prior knowledge about the physics of the problem, require modeling of dynamics, and struggle to adapt to abnormal situations. Deep reinforcement learning has the potential to address these problems by learning optimal control policies through exploration in an environment. For safety-critical environments, it is impractical to explore randomly, and replacing conventional controllers with black-box models is also undesirable. Also, it is expensive in continuous state and action spaces, unless the search space is constrained. To address these challenges we propose a specialized deep residual policy safe reinforcement learning with a cycle of learning approach adapted for complex and continuous state-action spaces. Residual policy learning allows learning a hybrid control architecture where the reinforcement learning agent acts in synchronous collaboration with the conventional controller. The cycle of learning initiates the policy through the expert trajectory and guides the exploration around it. Further, the specialization through the input-output hidden Markov model helps to optimize policy that lies within the region of interest (such as abnormality), where the reinforcement learning agent is required and is activated. The proposed solution is validated on the Tennessee Eastman process control.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023



We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
Idioms, Probing and Dangerous Things: Towards Structural Probing for Idiomaticity in Vector Space
Apr 27, 2023The goal of this paper is to learn more about how idiomatic information is structurally encoded in embeddings, using a structural probing method. We repurpose an existing English verbal multi-word expression (MWE) dataset to suit the probing framework and perform a comparative probing study of static (GloVe) and contextual (BERT) embeddings. Our experiments indicate that both encode some idiomatic information to varying degrees, but yield conflicting evidence as to whether idiomaticity is encoded in the vector norm, leaving this an open question. We also identify some limitations of the used dataset and highlight important directions for future work in improving its suitability for a probing analysis.
Probing Taxonomic and Thematic Embeddings for Taxonomic Information
Jan 25, 2023Modelling taxonomic and thematic relatedness is important for building AI with comprehensive natural language understanding. The goal of this paper is to learn more about how taxonomic information is structurally encoded in embeddings. To do this, we design a new hypernym-hyponym probing task and perform a comparative probing study of taxonomic and thematic SGNS and GloVe embeddings. Our experiments indicate that both types of embeddings encode some taxonomic information, but the amount, as well as the geometric properties of the encodings, are independently related to both the encoder architecture, as well as the embedding training data. Specifically, we find that only taxonomic embeddings carry taxonomic information in their norm, which is determined by the underlying distribution in the data.
Domain-Specific Text Generation for Machine Translation
Aug 11, 2022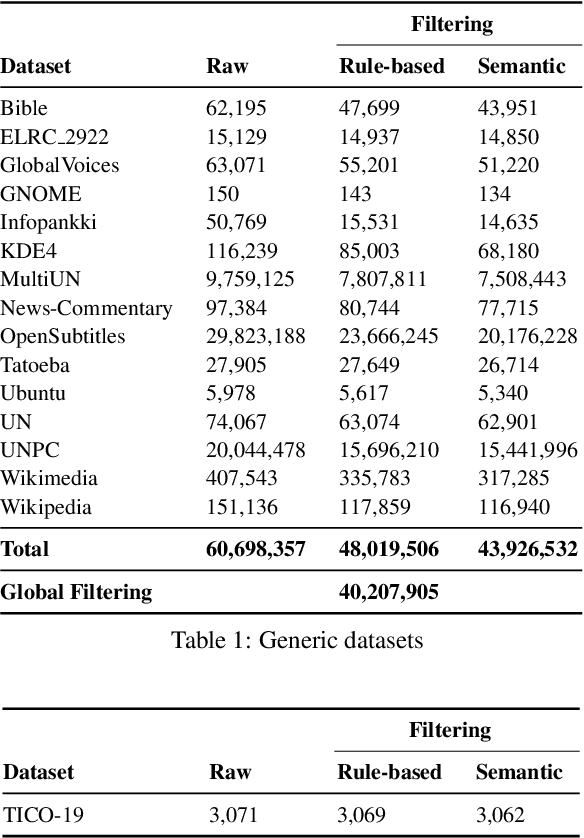
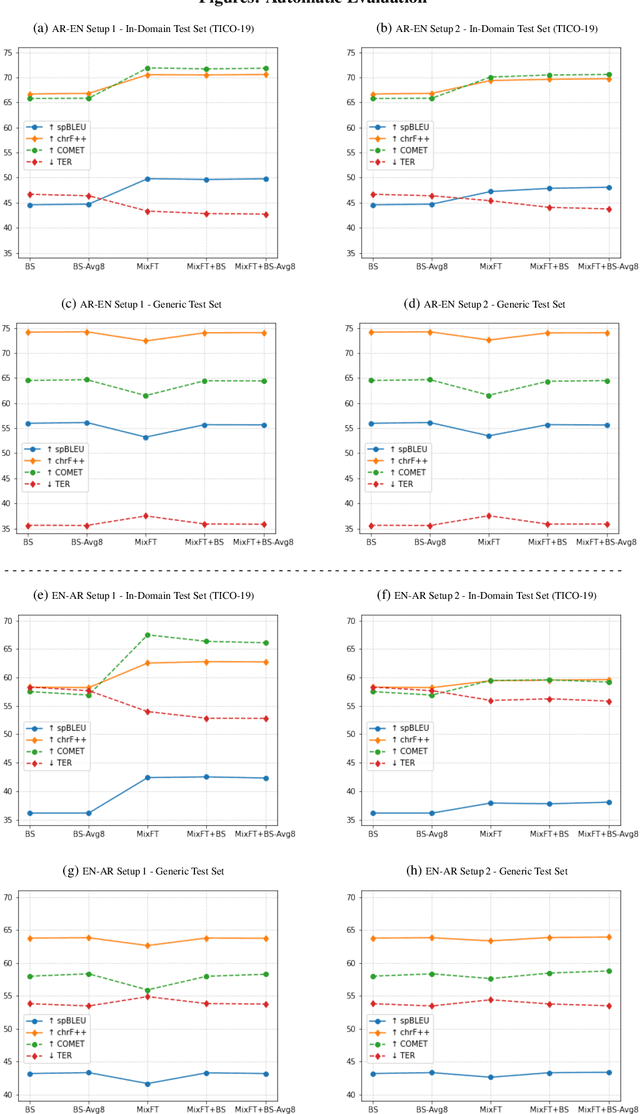
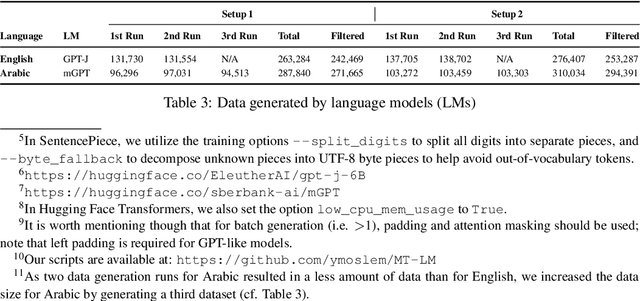
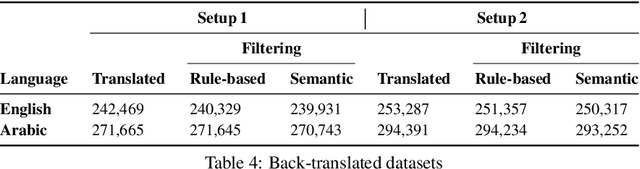
Preservation of domain knowledge from the source to target is crucial in any translation workflow. It is common in the translation industry to receive highly specialized projects, where there is hardly any parallel in-domain data. In such scenarios where there is insufficient in-domain data to fine-tune Machine Translation (MT) models, producing translations that are consistent with the relevant context is challenging. In this work, we propose a novel approach to domain adaptation leveraging state-of-the-art pretrained language models (LMs) for domain-specific data augmentation for MT, simulating the domain characteristics of either (a) a small bilingual dataset, or (b) the monolingual source text to be translated. Combining this idea with back-translation, we can generate huge amounts of synthetic bilingual in-domain data for both use cases. For our investigation, we use the state-of-the-art Transformer architecture. We employ mixed fine-tuning to train models that significantly improve translation of in-domain texts. More specifically, in both scenarios, our proposed methods achieve improvements of approximately 5-6 BLEU and 2-3 BLEU, respectively, on the Arabic-to-English and English-to-Arabic language pairs. Furthermore, the outcome of human evaluation corroborates the automatic evaluation results.