 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Sample-Based Musical Instruments Using Neural Audio Codec Language Models
Jul 22, 2024In this paper, we propose and investigate the use of neural audio codec language models for the automatic generation of sample-based musical instruments based on text or reference audio prompts. Our approach extends a generative audio framework to condition on pitch across an 88-key spectrum, velocity, and a combined text/audio embedding. We identify maintaining timbral consistency within the generated instruments as a major challenge. To tackle this issue, we introduce three distinct conditioning schemes. We analyze our methods through objective metrics and human listening tests, demonstrating that our approach can produce compelling musical instruments. Specifically, we introduce a new objective metric to evaluate the timbral consistency of the generated instruments and adapt the average Contrastive Language-Audio Pretraining (CLAP) score for the text-to-instrument case, noting that its naive application is unsuitable for assessing this task. Our findings reveal a complex interplay between timbral consistency, the quality of generated samples, and their correspondence to the input prompt.
DSP-informed bandwidth extension using locally-conditioned excitation and linear time-varying filter subnetworks
Jul 22, 2024



In this paper, we propose a dual-stage architecture for bandwidth extension (BWE) increasing the effective sampling rate of speech signals from 8 kHz to 48 kHz. Unlike existing end-to-end deep learning models, our proposed method explicitly models BWE using excitation and linear time-varying (LTV) filter stages. The excitation stage broadens the spectrum of the input, while the filtering stage properly shapes it based on outputs from an acoustic feature predictor. To this end, an acoustic feature loss term can implicitly promote the excitation subnetwork to produce white spectra in the upper frequency band to be synthesized. Experimental results demonstrate that the added inductive bias provided by our approach can improve upon BWE results using the generators from both SEANet or HiFi-GAN as exciters, and that our means of adapting processing with acoustic feature predictions is more effective than that used in HiFi-GAN-2. Secondary contributions include extensions of the SEANet model to accommodate local conditioning information, as well as the application of HiFi-GAN-2 for the BWE problem.
InstrumentGen: Generating Sample-Based Musical Instruments From Text
Nov 07, 2023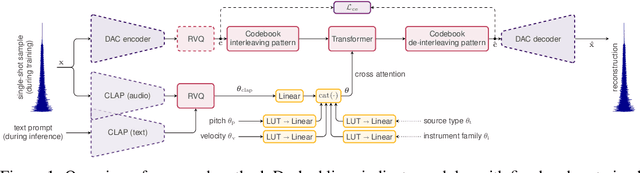
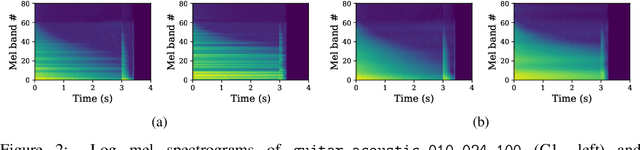
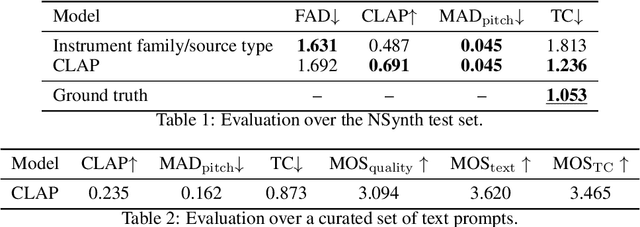
We introduce the text-to-instrument task, which aims at generating sample-based musical instruments based on textual prompts. Accordingly, we propose InstrumentGen, a model that extends a text-prompted generative audio framework to condition on instrument family, source type, pitch (across an 88-key spectrum), velocity, and a joint text/audio embedding. Furthermore, we present a differentiable loss function to evaluate the intra-instrument timbral consistency of sample-based instruments. Our results establish a foundational text-to-instrument baseline, extending research in the domain of automatic sample-based instrument generation.
Removing Distortion Effects in Music Using Deep Neural Networks
Feb 03, 2022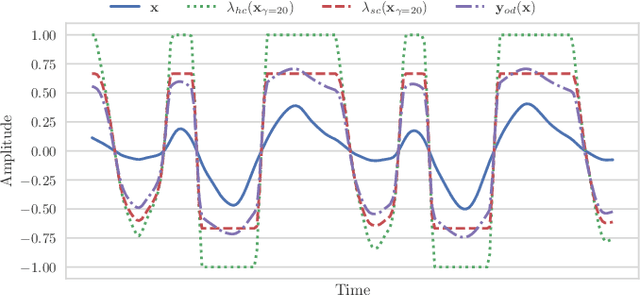
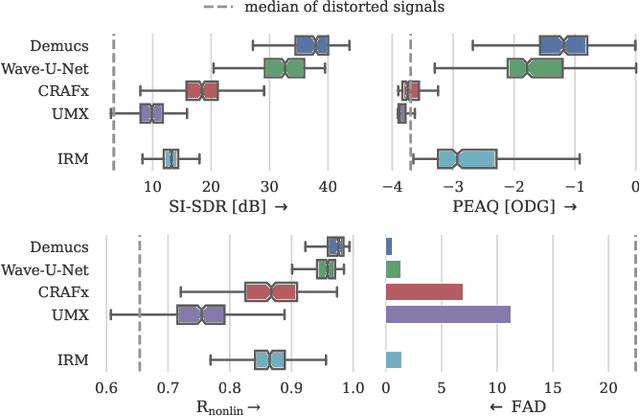
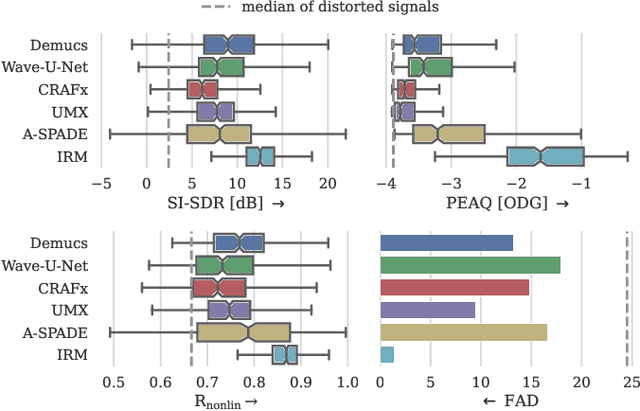
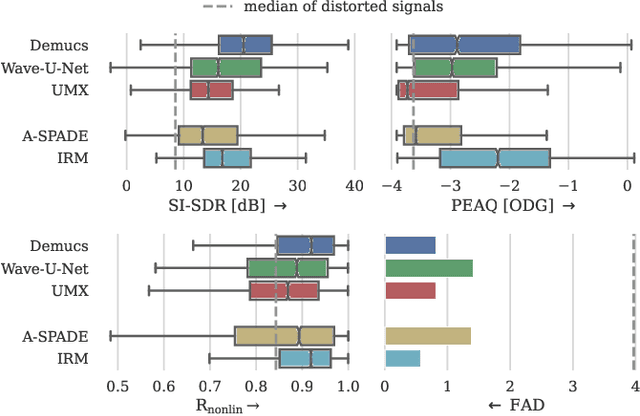
Audio effects are an essential element in the context of music production, and therefore, modeling analog audio effects has been extensively researched for decades using system-identification methods, circuit simulation, and recently, deep learning. However, only few works tackled the reconstruction of signals that were processed using an audio effect unit. Given the recent advances in music source separation and automatic mixing, the removal of audio effects could facilitate an automatic remixing system. This paper focuses on removing distortion and clipping applied to guitar tracks for music production while presenting a comparative investigation of different deep neural network (DNN) architectures on this task. We achieve exceptionally good results in distortion removal using DNNs for effects that superimpose the clean signal to the distorted signal, while the task is more challenging if the clean signal is not superimposed. Nevertheless, in the latter case, the neural models under evaluation surpass one state-of-the-art declipping system in terms of source-to-distortion ratio, leading to better quality and faster inference.