 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ(D)O-ES: Population-based Quality (Diversity) Optimisation for Post Hoc Ensemble Selection in AutoML
Aug 02, 2023



Automated machine learning (AutoML) systems commonly ensemble models post hoc to improve predictive performance, typically via greedy ensemble selection (GES). However, we believe that GES may not always be optimal, as it performs a simple deterministic greedy search. In this work, we introduce two novel population-based ensemble selection methods, QO-ES and QDO-ES, and compare them to GES. While QO-ES optimises solely for predictive performance, QDO-ES also considers the diversity of ensembles within the population, maintaining a diverse set of well-performing ensembles during optimisation based on ideas of quality diversity optimisation. The methods are evaluated using 71 classification datasets from the AutoML benchmark, demonstrating that QO-ES and QDO-ES often outrank GES, albeit only statistically significant on validation data. Our results further suggest that diversity can be beneficial for post hoc ensembling but also increases the risk of overfitting.
CMA-ES for Post Hoc Ensembling in AutoML: A Great Success and Salvageable Failure
Jul 01, 2023Many state-of-the-art automated machine learning (AutoML) systems use greedy ensemble selection (GES) by Caruana et al. (2004) to ensemble models found during model selection post hoc. Thereby, boosting predictive performance and likely following Auto-Sklearn 1's insight that alternatives, like stacking or gradient-free numerical optimization, overfit. Overfitting in Auto-Sklearn 1 is much more likely than in other AutoML systems because it uses only low-quality validation data for post hoc ensembling. Therefore, we were motivated to analyze whether Auto-Sklearn 1's insight holds true for systems with higher-quality validation data. Consequently, we compared the performance of covariance matrix adaptation evolution strategy (CMA-ES), state-of-the-art gradient-free numerical optimization, to GES on the 71 classification datasets from the AutoML benchmark for AutoGluon. We found that Auto-Sklearn's insight depends on the chosen metric. For the metric ROC AUC, CMA-ES overfits drastically and is outperformed by GES -- statistically significantly for multi-class classification. For the metric balanced accuracy, CMA-ES does not overfit and outperforms GES significantly. Motivated by the successful application of CMA-ES for balanced accuracy, we explored methods to stop CMA-ES from overfitting for ROC AUC. We propose a method to normalize the weights produced by CMA-ES, inspired by GES, that avoids overfitting for CMA-ES and makes CMA-ES perform better than or similar to GES for ROC AUC.
Assembled-OpenML: Creating Efficient Benchmarks for Ensembles in AutoML with OpenML
Jul 01, 2023Automated Machine Learning (AutoML) frameworks regularly use ensembles. Developers need to compare different ensemble techniques to select appropriate techniques for an AutoML framework from the many potential techniques. So far, the comparison of ensemble techniques is often computationally expensive, because many base models must be trained and evaluated one or multiple times. Therefore, we present Assembled-OpenML. Assembled-OpenML is a Python tool, which builds meta-datasets for ensembles using OpenML. A meta-dataset, called Metatask, consists of the data of an OpenML task, the task's dataset, and prediction data from model evaluations for the task. We can make the comparison of ensemble techniques computationally cheaper by using the predictions stored in a metatask instead of training and evaluating base models. To introduce Assembled-OpenML, we describe the first version of our tool. Moreover, we present an example of using Assembled-OpenML to compare a set of ensemble techniques. For this example comparison, we built a benchmark using Assembled-OpenML and implemented ensemble techniques expecting predictions instead of base models as input. In our example comparison, we gathered the prediction data of $1523$ base models for $31$ datasets. Obtaining the prediction data for all base models using Assembled-OpenML took ${\sim} 1$ hour in total. In comparison, obtaining the prediction data by training and evaluating just one base model on the most computationally expensive dataset took ${\sim} 37$ minutes.
Per-Instance Algorithm Selection for Recommender Systems via Instance Clustering
Dec 30, 2020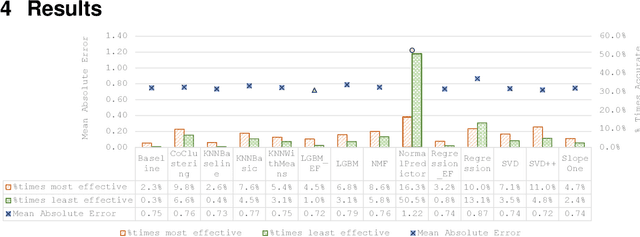


Recommendation algorithms perform differently if the users, recommendation contexts, applications, and user interfaces vary even slightly. It is similarly observed in other fields, such as combinatorial problem solving, that algorithms perform differently for each instance presented. In those fields, meta-learning is successfully used to predict an optimal algorithm for each instance, to improve overall system performance. Per-instance algorithm selection has thus far been unsuccessful for recommender systems. In this paper we propose a per-instance meta-learner that clusters data instances and predicts the best algorithm for unseen instances according to cluster membership. We test our approach using 10 collaborative- and 4 content-based filtering algorithms, for varying clustering parameters, and find a significant improvement over the best performing base algorithm at alpha=0.053 (MAE: 0.7107 vs LightGBM 0.7214; t-test). We also explore the performances of our base algorithms on a ratings dataset and empirically show that the error of a perfect algorithm selector monotonically decreases for larger pools of algorithm. To the best of our knowledge, this is the first effective meta-learning technique for per-instance algorithm selection in recommender systems.
Finite Group Equivariant Neural Networks for Games
Sep 10, 2020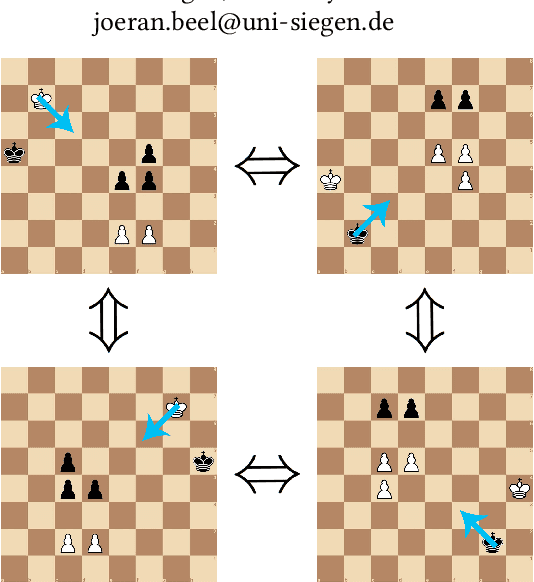
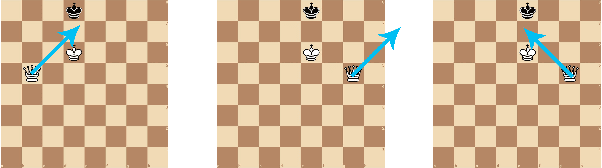
Games such as go, chess and checkers have multiple equivalent game states, i.e. multiple board positions where symmetrical and opposite moves should be made. These equivalences are not exploited by current state of the art neural agents which instead must relearn similar information, thereby wasting computing time. Group equivariant CNNs in existing work create networks which can exploit symmetries to improve learning, however, they lack the expressiveness to correctly reflect the move embeddings necessary for games. We introduce Finite Group Neural Networks (FGNNs), a method for creating agents with an innate understanding of these board positions. FGNNs are shown to improve the performance of networks playing checkers (draughts), and can be easily adapted to other games and learning problems. Additionally, FGNNs can be created from existing network architectures. These include, for the first time, those with skip connections and arbitrary layer types. We demonstrate that an equivariant version of U-Net (FGNN-U-Net) outperforms the unmodified network in image segmentation.
Towards an Interoperable Data Protocol Aimed at Linking the Fashion Industry with AI Companies
Sep 07, 2020


The fashion industry is looking forward to use artificial intelligence technologies to enhance their processes, services, and applications. Although the amount of fashion data currently in use is increasing, there is a large gap in data exchange between the fashion industry and the related AI companies, not to mention the different structure used for each fashion dataset. As a result, AI companies are relying on manually annotated fashion data to build different applications. Furthermore, as of this writing, the terminology, vocabulary and methods of data representation used to denote fashion items are still ambiguous and confusing. Hence, it is clear that the fashion industry and AI companies will benefit from a protocol that allows them to exchange and organise fashion information in a unified way. To achieve this goal we aim (1) to define a protocol called DDOIF that will allow interoperability of fashion data; (2) for DDOIF to contain diverse entities including extensive information on clothing and accessories attributes in the form of text and various media formats; and (3)To design and implement an API that includes, among other things, functions for importing and exporting a file built according to the DDOIF protocol that stores all information about a single item of clothing. To this end, we identified over 1000 class and subclass names used to name fashion items and use them to build the DDOIF dictionary. We make DDOIF publicly available to all interested users and developers and look forward to engaging more collaborators to improve and enrich it.
Auto-Surprise: An Automated Recommender-System (AutoRecSys) Library with Tree of Parzens Estimator (TPE) Optimization
Aug 19, 2020
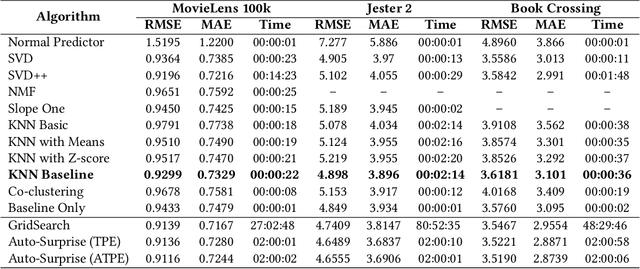
We introduce Auto-Surprise, an Automated Recommender System library. Auto-Surprise is an extension of the Surprise recommender system library and eases the algorithm selection and configuration process. Compared to out-of-the-box Surprise library, Auto-Surprise performs better when evaluated with MovieLens, Book Crossing and Jester Datasets. It may also result in the selection of an algorithm with significantly lower runtime. Compared to Surprise's grid search, Auto-Surprise performs equally well or slightly better in terms of RMSE, and is notably faster in finding the optimum hyperparameters.
Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]
Jun 23, 2020![Figure 1 for Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fdded217ac3c93998376d8e0ffea5cbe23772a43e%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fdded217ac3c93998376d8e0ffea5cbe23772a43e%2F2-Figure2-1.png&w=640&q=75)
![Figure 3 for Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fdded217ac3c93998376d8e0ffea5cbe23772a43e%2F3-Figure3-1.png&w=640&q=75)
![Figure 4 for Siamese Meta-Learning and Algorithm Selection with 'Algorithm-Performance Personas' [Proposal]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fdded217ac3c93998376d8e0ffea5cbe23772a43e%2F4-Figure4-1.png&w=640&q=75)
Automated per-instance algorithm selection often outperforms single learners. Key to algorithm selection via meta-learning is often the (meta) features, which sometimes though do not provide enough information to train a meta-learner effectively. We propose a Siamese Neural Network architecture for automated algorithm selection that focuses more on 'alike performing' instances than meta-features. Our work includes a novel performance metric and method for selecting training samples. We introduce further the concept of 'Algorithm Performance Personas' that describe instances for which the single algorithms perform alike. The concept of 'alike performing algorithms' as ground truth for selecting training samples is novel and provides a huge potential as we believe. In this proposal, we outline our ideas in detail and provide the first evidence that our proposed metric is better suitable for training sample selection that standard performance metrics such as absolute errors.
Synthetic vs. Real Reference Strings for Citation Parsing, and the Importance of Re-training and Out-Of-Sample Data for Meaningful Evaluations: Experiments with GROBID, GIANT and Cora
Apr 25, 2020
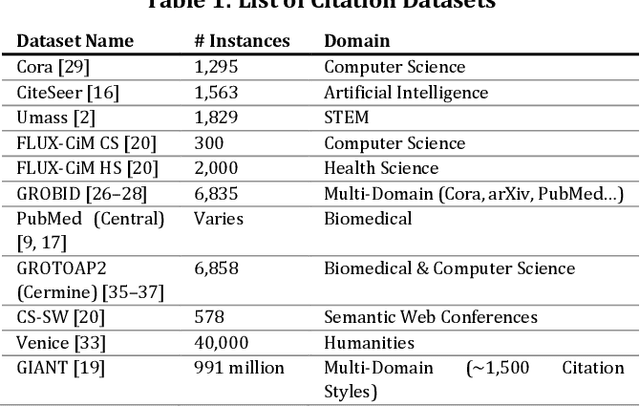
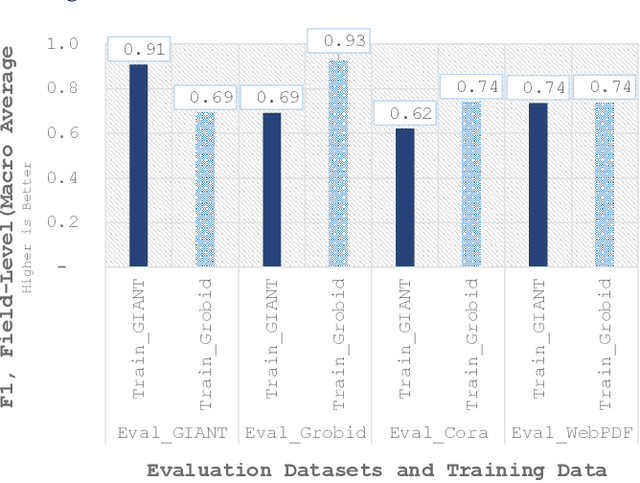
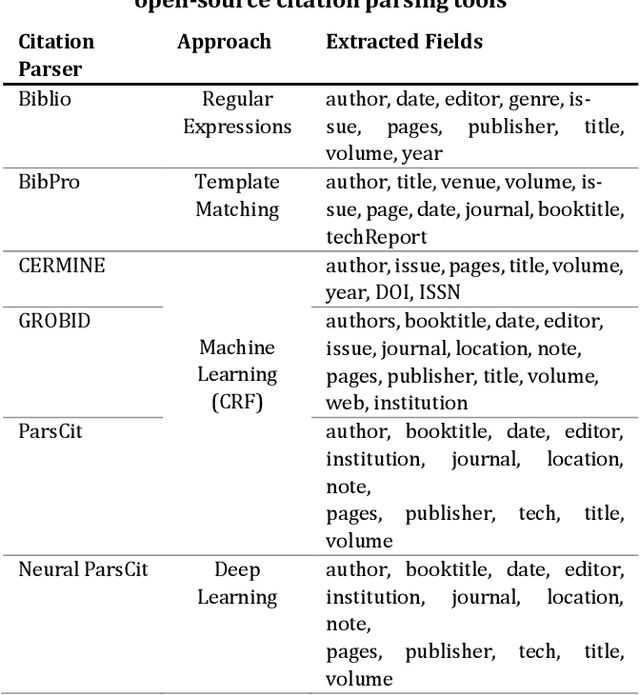
Citation parsing, particularly with deep neural networks, suffers from a lack of training data as available datasets typically contain only a few thousand training instances. Manually labelling citation strings is very time-consuming, hence synthetically created training data could be a solution. However, as of now, it is unknown if synthetically created reference-strings are suitable to train machine learning algorithms for citation parsing. To find out, we train Grobid, which uses Conditional Random Fields, with a) human-labelled reference strings from 'real' bibliographies and b) synthetically created reference strings from the GIANT dataset. We find that both synthetic and organic reference strings are equally suited for training Grobid (F1 = 0.74). We additionally find that retraining Grobid has a notable impact on its performance, for both synthetic and real data (+30% in F1). Having as many types of labelled fields as possible during training also improves effectiveness, even if these fields are not available in the evaluation data (+13.5% F1). We conclude that synthetic data is suitable for training (deep) citation parsing models. We further suggest that in future evaluations of reference parsers both evaluation data similar and dissimilar to the training data should be used for more meaningful evaluations.
Predicting the Outcome of Judicial Decisions made by the European Court of Human Rights
Dec 16, 2019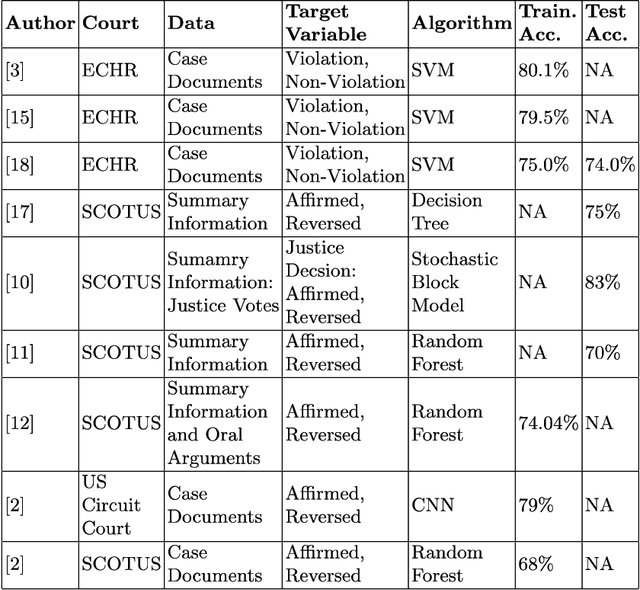
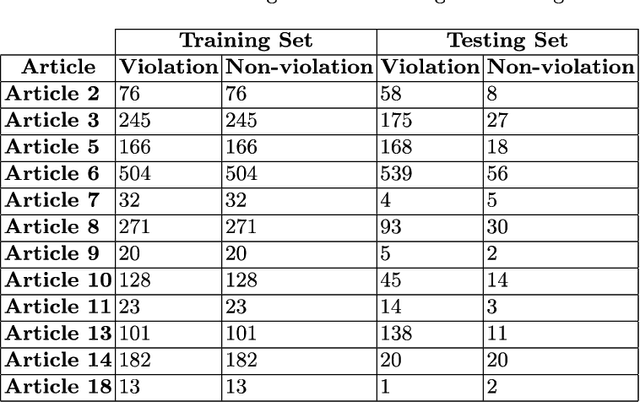
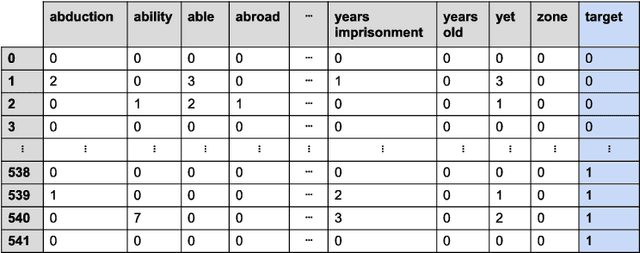
In this study, machine learning models were constructed to predict whether judgments made by the European Court of Human Rights (ECHR) would lead to a violation of an Article in the Convention on Human Rights. The problem is framed as a binary classification task where a judgment can lead to a "violation" or "non-violation" of a particular Article. Using auto-sklearn, an automated algorithm selection package, models were constructed for 12 Articles in the Convention. To train these models, textual features were obtained from the ECHR Judgment documents using N-grams, word embeddings and paragraph embeddings. Additional documents, from the ECHR, were incorporated into the models through the creation of a word embedding (echr2vec) and a doc2vec model. The features obtained using the echr2vec embedding provided the highest cross-validation accuracy for 5 of the Articles. The overall test accuracy, across the 12 Articles, was 68.83%. As far as we could tell, this is the first estimate of the accuracy of such machine learning models using a realistic test set. This provides an important benchmark for future work. As a baseline, a simple heuristic of always predicting the most common outcome in the past was used. The heuristic achieved an overall test accuracy of 86.68% which is 29.7% higher than the models. Again, this was seemingly the first study that included such a heuristic with which to compare model results. The higher accuracy achieved by the heuristic highlights the importance of including such a baseline.