 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics derived automatically from language corpora contain human-like biases
May 25, 2017Artificial intelligence and machine learning are in a period of astounding growth. However, there are concerns that these technologies may be used, either with or without intention, to perpetuate the prejudice and unfairness that unfortunately characterizes many human institutions. Here we show for the first time that human-like semantic biases result from the application of standard machine learning to ordinary language---the same sort of language humans are exposed to every day. We replicate a spectrum of standard human biases as exposed by the Implicit Association Test and other well-known psychological studies. We replicate these using a widely used, purely statistical machine-learning model---namely, the GloVe word embedding---trained on a corpus of text from the Web. Our results indicate that language itself contains recoverable and accurate imprints of our historic biases, whether these are morally neutral as towards insects or flowers, problematic as towards race or gender, or even simply veridical, reflecting the {\em status quo} for the distribution of gender with respect to careers or first names. These regularities are captured by machine learning along with the rest of semantics. In addition to our empirical findings concerning language, we also contribute new methods for evaluating bias in text, the Word Embedding Association Test (WEAT) and the Word Embedding Factual Association Test (WEFAT). Our results have implications not only for AI and machine learning, but also for the fields of psychology, sociology, and human ethics, since they raise the possibility that mere exposure to everyday language can account for the biases we replicate here.
Measuring Cultural Relativity of Emotional Valence and Arousal using Semantic Clustering and Twitter
Apr 28, 2013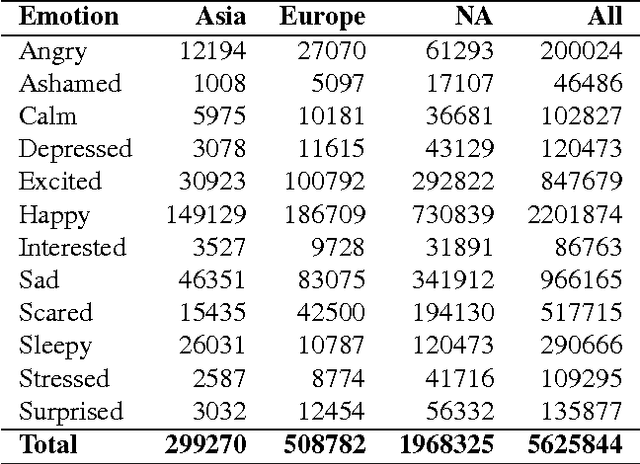
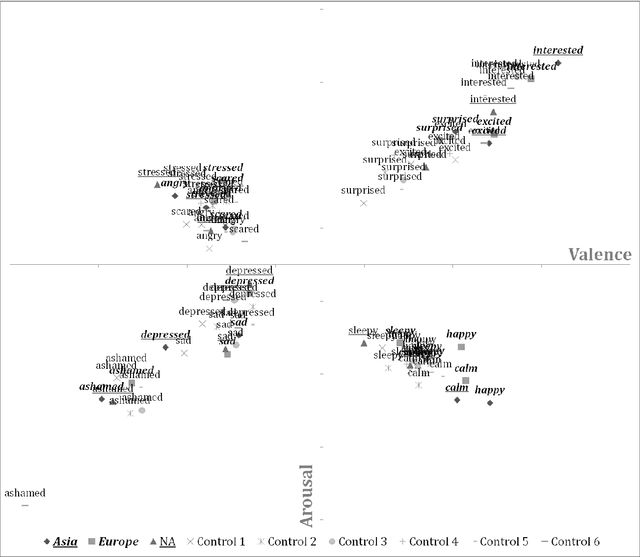
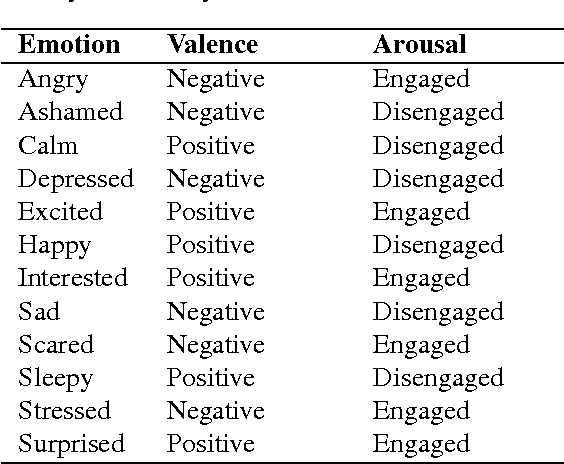
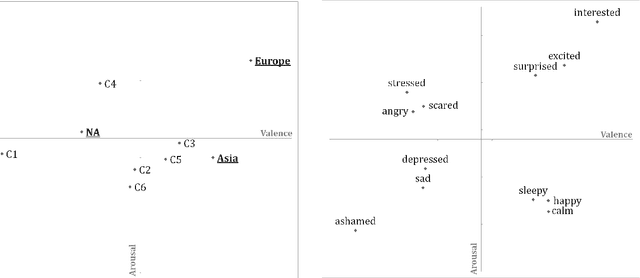
Researchers since at least Darwin have debated whether and to what extent emotions are universal or culture-dependent. However, previous studies have primarily focused on facial expressions and on a limited set of emotions. Given that emotions have a substantial impact on human lives, evidence for cultural emotional relativity might be derived by applying distributional semantics techniques to a text corpus of self-reported behaviour. Here, we explore this idea by measuring the valence and arousal of the twelve most popular emotion keywords expressed on the micro-blogging site Twitter. We do this in three geographical regions: Europe, Asia and North America. We demonstrate that in our sample, the valence and arousal levels of the same emotion keywords differ significantly with respect to these geographical regions --- Europeans are, or at least present themselves as more positive and aroused, North Americans are more negative and Asians appear to be more positive but less aroused when compared to global valence and arousal levels of the same emotion keywords. Our work is the first in kind to programatically map large text corpora to a dimensional model of affect.