 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA deep learning framework to generate realistic population and mobility data
Nov 14, 2022



Census and Household Travel Survey datasets are regularly collected from households and individuals and provide information on their daily travel behavior with demographic and economic characteristics. These datasets have important applications ranging from travel demand estimation to agent-based modeling. However, they often represent a limited sample of the population due to privacy concerns or are given aggregated. Synthetic data augmentation is a promising avenue in addressing these challenges. In this paper, we propose a framework to generate a synthetic population that includes both socioeconomic features (e.g., age, sex, industry) and trip chains (i.e., activity locations). Our model is tested and compared with other recently proposed models on multiple assessment metrics.
ConMatch: Semi-Supervised Learning with Confidence-Guided Consistency Regularization
Aug 18, 2022
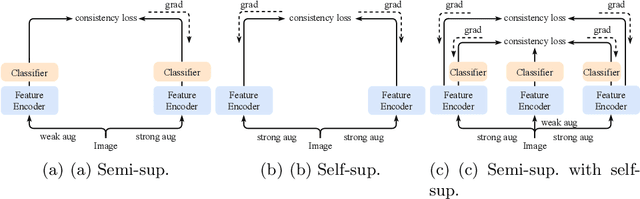
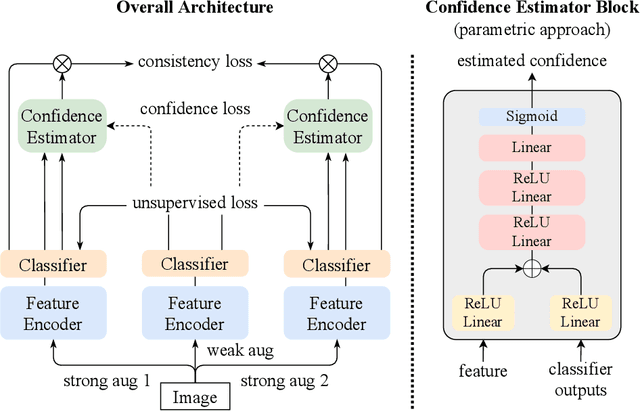
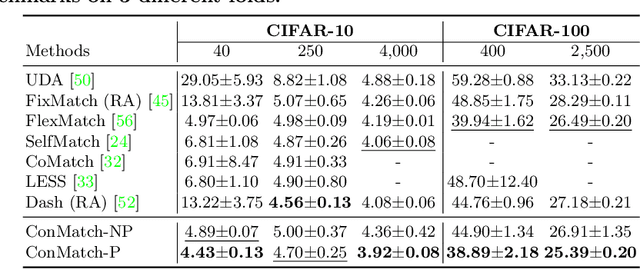
We present a novel semi-supervised learning framework that intelligently leverages the consistency regularization between the model's predictions from two strongly-augmented views of an image, weighted by a confidence of pseudo-label, dubbed ConMatch. While the latest semi-supervised learning methods use weakly- and strongly-augmented views of an image to define a directional consistency loss, how to define such direction for the consistency regularization between two strongly-augmented views remains unexplored. To account for this, we present novel confidence measures for pseudo-labels from strongly-augmented views by means of weakly-augmented view as an anchor in non-parametric and parametric approaches. Especially, in parametric approach, we present, for the first time, to learn the confidence of pseudo-label within the networks, which is learned with backbone model in an end-to-end manner. In addition, we also present a stage-wise training to boost the convergence of training. When incorporated in existing semi-supervised learners, ConMatch consistently boosts the performance. We conduct experiments to demonstrate the effectiveness of our ConMatch over the latest methods and provide extensive ablation studies. Code has been made publicly available at https://github.com/JiwonCocoder/ConMatch.
Estimating Link Flows in Road Networks with Synthetic Trajectory Data Generation: Reinforcement Learning-based Approaches
Jun 26, 2022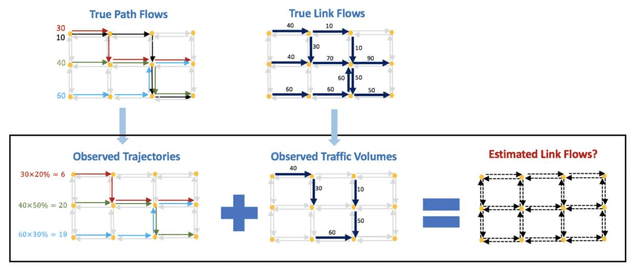
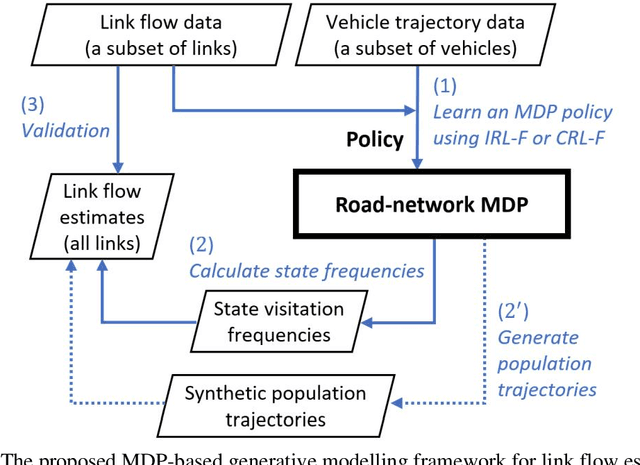

This paper addresses the problem of estimating link flows in a road network by combining limited traffic volume and vehicle trajectory data. While traffic volume data from loop detectors have been the common data source for link flow estimation, the detectors only cover a subset of links. Vehicle trajectory data collected from vehicle tracking sensors are also incorporated these days. However, trajectory data are often sparse in that the observed trajectories only represent a small subset of the whole population, where the exact sampling rate is unknown and may vary over space and time. This study proposes a novel generative modelling framework, where we formulate the link-to-link movements of a vehicle as a sequential decision-making problem using the Markov Decision Process framework and train an agent to make sequential decisions to generate realistic synthetic vehicle trajectories. We use Reinforcement Learning (RL)-based methods to find the best behaviour of the agent, based on which synthetic population vehicle trajectories can be generated to estimate link flows across the whole network. To ensure the generated population vehicle trajectories are consistent with the observed traffic volume and trajectory data, two methods based on Inverse Reinforcement Learning and Constrained Reinforcement Learning are proposed. The proposed generative modelling framework solved by either of these RL-based methods is validated by solving the link flow estimation problem in a real road network. Additionally, we perform comprehensive experiments to compare the performance with two existing methods. The results show that the proposed framework has higher estimation accuracy and robustness under realistic scenarios where certain behavioural assumptions about drivers are not met or the network coverage and penetration rate of trajectory data are low.
Joint Learning of Feature Extraction and Cost Aggregation for Semantic Correspondence
Apr 19, 2022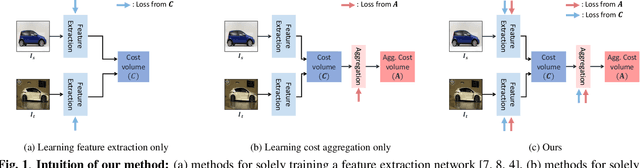
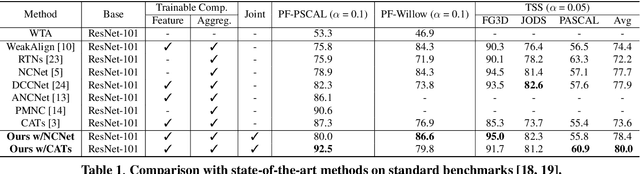

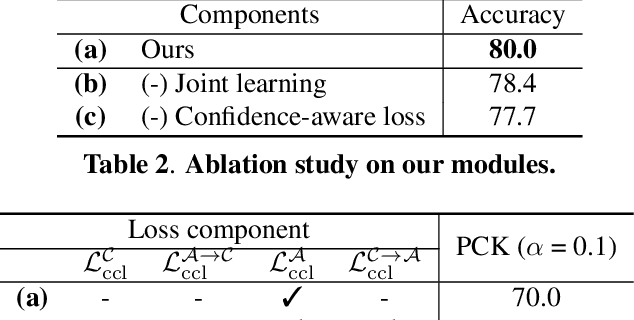
Establishing dense correspondences across semantically similar images is one of the challenging tasks due to the significant intra-class variations and background clutters. To solve these problems, numerous methods have been proposed, focused on learning feature extractor or cost aggregation independently, which yields sub-optimal performance. In this paper, we propose a novel framework for jointly learning feature extraction and cost aggregation for semantic correspondence. By exploiting the pseudo labels from each module, the networks consisting of feature extraction and cost aggregation modules are simultaneously learned in a boosting fashion. Moreover, to ignore unreliable pseudo labels, we present a confidence-aware contrastive loss function for learning the networks in a weakly-supervised manner. We demonstrate our competitive results on standard benchmarks for semantic correspondence.
Semi-Supervised Learning of Semantic Correspondence with Pseudo-Labels
Apr 05, 2022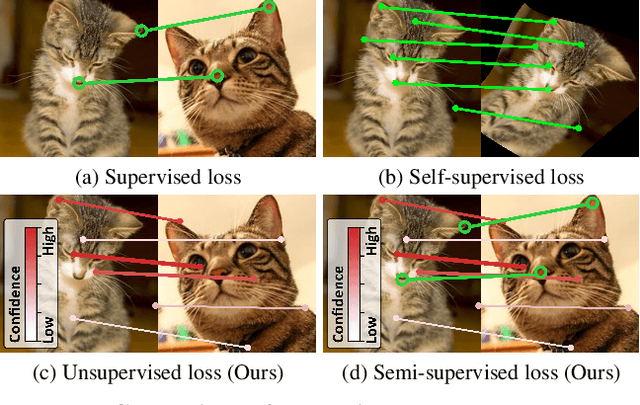
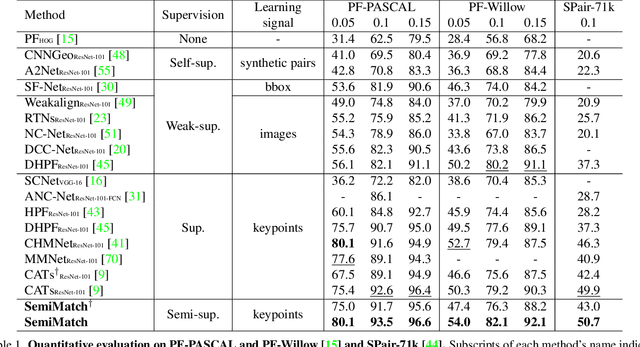
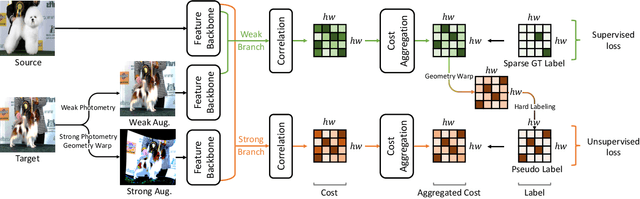
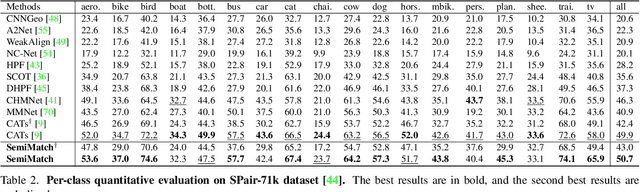
Establishing dense correspondences across semantically similar images remains a challenging task due to the significant intra-class variations and background clutters. Traditionally, a supervised learning was used for training the models, which required tremendous manually-labeled data, while some methods suggested a self-supervised or weakly-supervised learning to mitigate the reliance on the labeled data, but with limited performance. In this paper, we present a simple, but effective solution for semantic correspondence that learns the networks in a semi-supervised manner by supplementing few ground-truth correspondences via utilization of a large amount of confident correspondences as pseudo-labels, called SemiMatch. Specifically, our framework generates the pseudo-labels using the model's prediction itself between source and weakly-augmented target, and uses pseudo-labels to learn the model again between source and strongly-augmented target, which improves the robustness of the model. We also present a novel confidence measure for pseudo-labels and data augmentation tailored for semantic correspondence. In experiments, SemiMatch achieves state-of-the-art performance on various benchmarks, especially on PF-Willow by a large margin.
AggMatch: Aggregating Pseudo Labels for Semi-Supervised Learning
Jan 25, 2022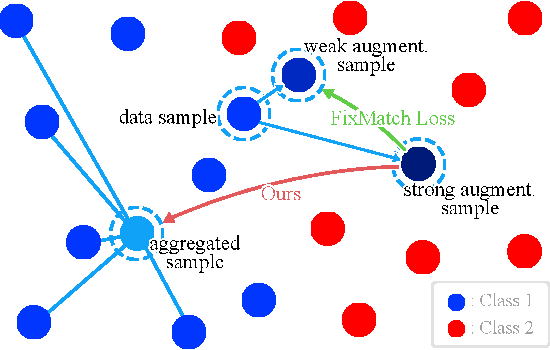
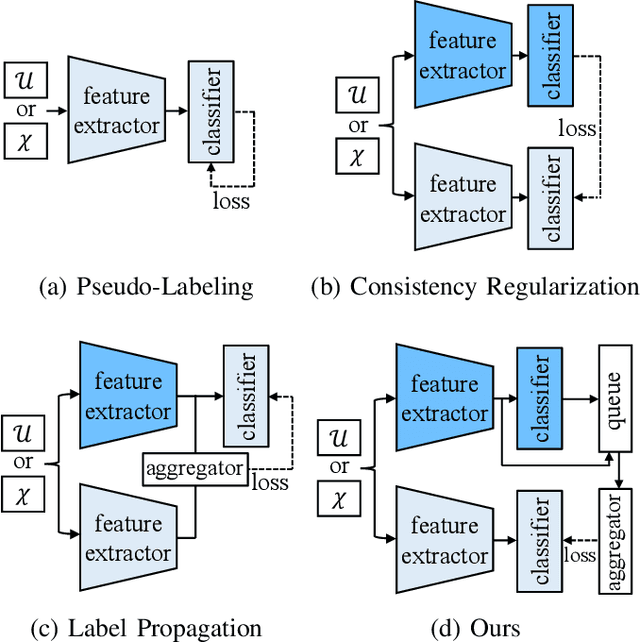
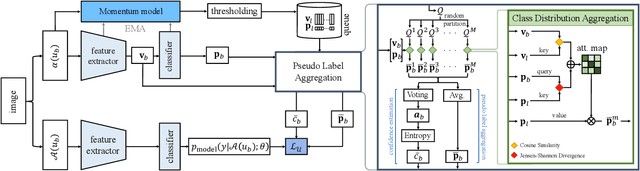
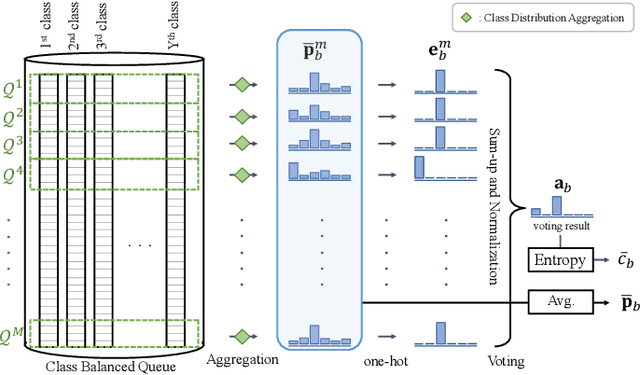
Semi-supervised learning (SSL) has recently proven to be an effective paradigm for leveraging a huge amount of unlabeled data while mitigating the reliance on large labeled data. Conventional methods focused on extracting a pseudo label from individual unlabeled data sample and thus they mostly struggled to handle inaccurate or noisy pseudo labels, which degenerate performance. In this paper, we address this limitation with a novel SSL framework for aggregating pseudo labels, called AggMatch, which refines initial pseudo labels by using different confident instances. Specifically, we introduce an aggregation module for consistency regularization framework that aggregates the initial pseudo labels based on the similarity between the instances. To enlarge the aggregation candidates beyond the mini-batch, we present a class-balanced confidence-aware queue built with the momentum model, encouraging to provide more stable and consistent aggregation. We also propose a novel uncertainty-based confidence measure for the pseudo label by considering the consensus among multiple hypotheses with different subsets of the queue. We conduct experiments to demonstrate the effectiveness of AggMatch over the latest methods on standard benchmarks and provide extensive analyses.
A Computational Approach to Measure Empathy and Theory-of-Mind from Written Texts
Aug 26, 2021

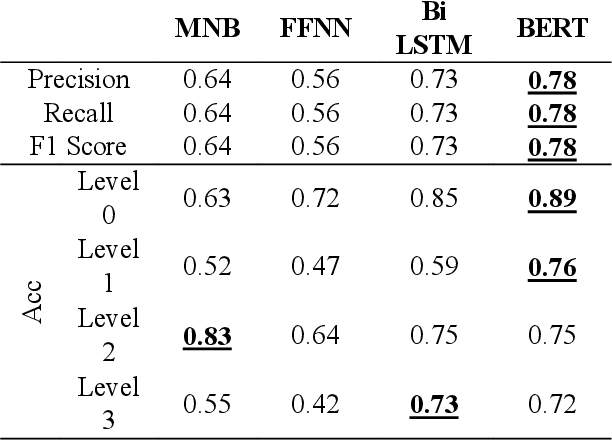
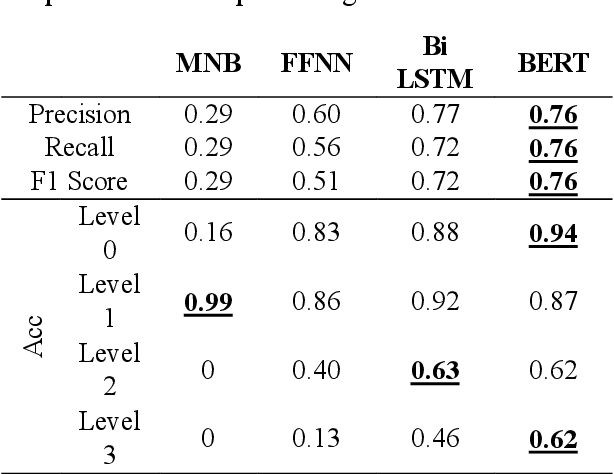
Theory-of-mind (ToM), a human ability to infer the intentions and thoughts of others, is an essential part of empathetic experiences. We provide here the framework for using NLP models to measure ToM expressed in written texts. For this purpose, we introduce ToM-Diary, a crowdsourced 18,238 diaries with 74,014 Korean sentences annotated with different ToM levels. Each diary was annotated with ToM levels by trained psychology students and reviewed by selected psychology experts. The annotators first divided the diaries based on whether they mentioned other people: self-focused and other-focused. Examples of self-focused sentences are "I am feeling good". The other-focused sentences were further classified into different levels. These levels differ by whether the writer 1) mentions the presence of others without inferring their mental state(e.g., I saw a man walking down the street), 2) fails to take the perspective of others (e.g., I don't understand why they refuse to wear masks), or 3) successfully takes the perspective of others (It must have been hard for them to continue working). We tested whether state-of-the-art transformer-based models (e.g., BERT) could predict underlying ToM levels in sentences. We found that BERT more successfully detected self-focused sentences than other-focused ones. Sentences that successfully take the perspective of others (the highest ToM level) were the most difficult to predict. Our study suggests a promising direction for large-scale and computational approaches for identifying the ability of authors to empathize and take the perspective of others. The dataset is at [URL](https://github.com/humanfactorspsych/covid19-tom-empathy-diary)
TrajGAIL: Generating Urban Vehicle Trajectories using Generative Adversarial Imitation Learning
Aug 21, 2020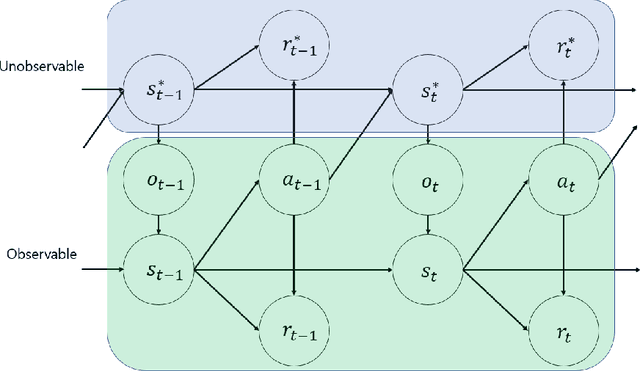
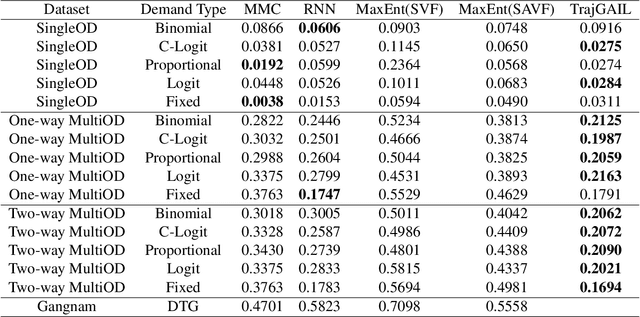
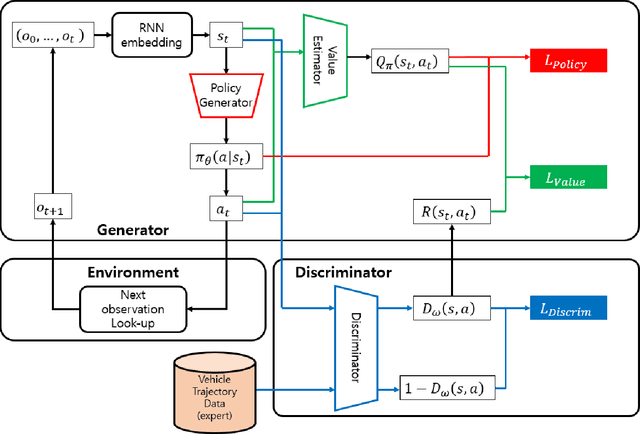
Recently, an abundant amount of urban vehicle trajectory data has been collected in road networks. Many studies have used machine learning algorithms to analyze patterns in vehicle trajectories to predict location sequences of individual travelers. Unlike the previous studies that used a discriminative modeling approach, this research suggests a generative modeling approach to learn the underlying distributions of urban vehicle trajectory data. A generative model for urban vehicle trajectories can better generalize from training data by learning the underlying distribution of the training data and, thus, produce synthetic vehicle trajectories similar to real vehicle trajectories with limited observations. Synthetic trajectories can provide solutions to data sparsity or data privacy issues in using location data. This research proposesTrajGAIL, a generative adversarial imitation learning framework for the urban vehicle trajectory generation. In TrajGAIL, learning location sequences in observed trajectories is formulated as an imitation learning problem in a partially observable Markov decision process. The model is trained by the generative adversarial framework, which uses the reward function from the adversarial discriminator. The model is tested with both simulation and real-world datasets, and the results show that the proposed model obtained significant performance gains compared to existing models in sequence modeling.
Associative Partial Domain Adaptation
Aug 07, 2020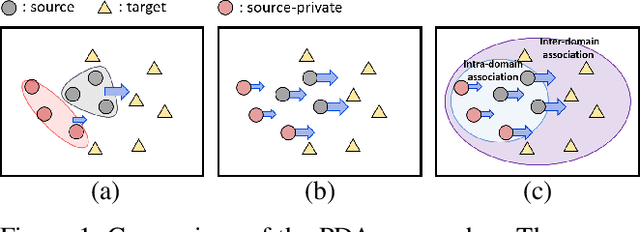
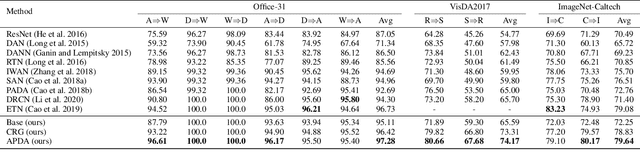
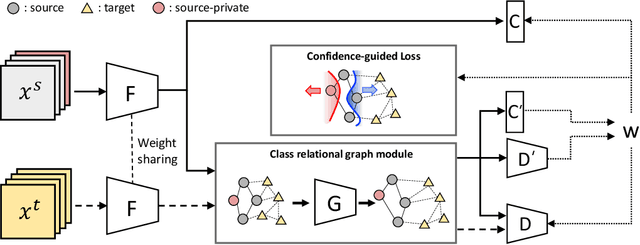
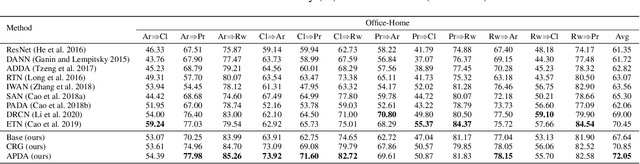
Partial Adaptation (PDA) addresses a practical scenario in which the target domain contains only a subset of classes in the source domain. While PDA should take into account both class-level and sample-level to mitigate negative transfer, current approaches mostly rely on only one of them. In this paper, we propose a novel approach to fully exploit multi-level associations that can arise in PDA. Our Associative Partial Domain Adaptation (APDA) utilizes intra-domain association to actively select out non-trivial anomaly samples in each source-private class that sample-level weighting cannot handle. Additionally, our method considers inter-domain association to encourage positive transfer by mapping between nearby target samples and source samples with high label-commonness. For this, we exploit feature propagation in a proposed label space consisting of source ground-truth labels and target probabilistic labels. We further propose a geometric guidance loss based on the label commonness of each source class to encourage positive transfer. Our APDA consistently achieves state-of-the-art performance across public datasets.
Sample-based Regularization: A Transfer Learning Strategy Toward Better Generalization
Jul 10, 2020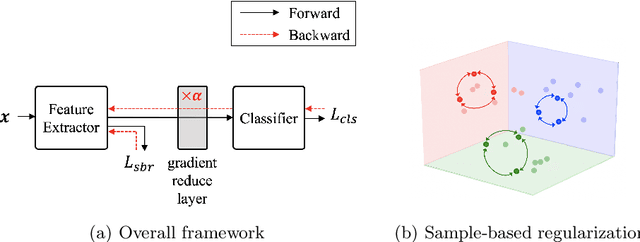
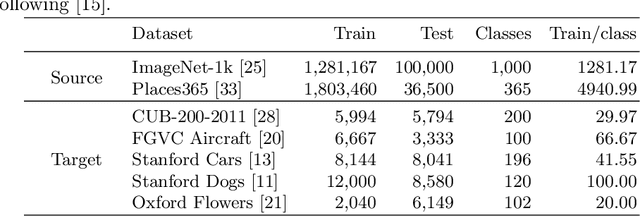
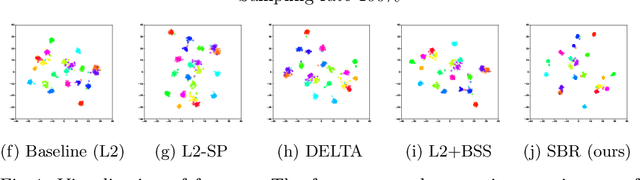
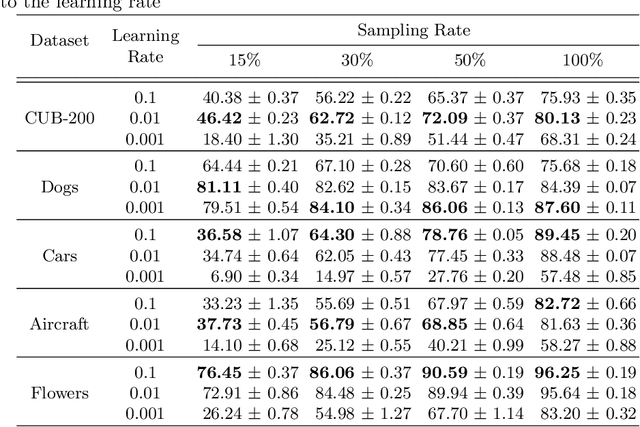
Training a deep neural network with a small amount of data is a challenging problem as it is vulnerable to overfitting. However, one of the practical difficulties that we often face is to collect many samples. Transfer learning is a cost-effective solution to this problem. By using the source model trained with a large-scale dataset, the target model can alleviate the overfitting originated from the lack of training data. Resorting to the ability of generalization of the source model, several methods proposed to use the source knowledge during the whole training procedure. However, this is likely to restrict the potential of the target model and some transferred knowledge from the source can interfere with the training procedure. For improving the generalization performance of the target model with a few training samples, we proposed a regularization method called sample-based regularization (SBR), which does not rely on the source's knowledge during training. With SBR, we suggested a new training framework for transfer learning. Experimental results showed that our framework outperformed existing methods in various configurations.