 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
Speech Tokenizer is Key to Consistent Representation
Jul 09, 2025Speech tokenization is crucial in digital speech processing, converting continuous speech signals into discrete units for various computational tasks. This paper introduces a novel speech tokenizer with broad applicability across downstream tasks. While recent advances in residual vector quantization (RVQ) have incorporated semantic elements, they often neglect critical acoustic features. We propose an advanced approach that simultaneously encodes both linguistic and acoustic information, preserving prosodic and emotional content. Our method significantly enhances speech representation fidelity across diverse applications. Empirical evaluations demonstrate its effectiveness in speech coding, voice conversion, emotion recognition, and multimodal language modeling, without requiring additional training. This versatility underscores its potential as a key tool for advancing AI-driven speech processing.
Associative Partial Domain Adaptation
Aug 07, 2020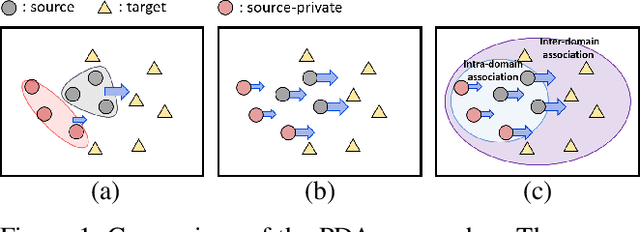
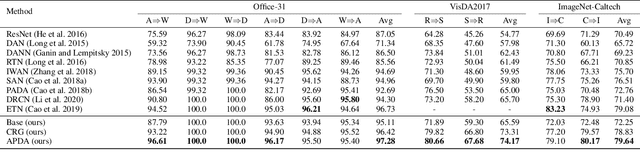
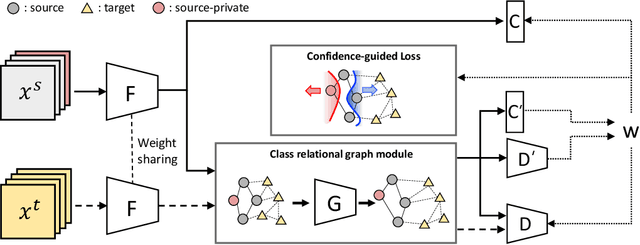
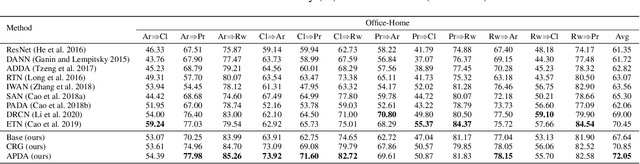
Partial Adaptation (PDA) addresses a practical scenario in which the target domain contains only a subset of classes in the source domain. While PDA should take into account both class-level and sample-level to mitigate negative transfer, current approaches mostly rely on only one of them. In this paper, we propose a novel approach to fully exploit multi-level associations that can arise in PDA. Our Associative Partial Domain Adaptation (APDA) utilizes intra-domain association to actively select out non-trivial anomaly samples in each source-private class that sample-level weighting cannot handle. Additionally, our method considers inter-domain association to encourage positive transfer by mapping between nearby target samples and source samples with high label-commonness. For this, we exploit feature propagation in a proposed label space consisting of source ground-truth labels and target probabilistic labels. We further propose a geometric guidance loss based on the label commonness of each source class to encourage positive transfer. Our APDA consistently achieves state-of-the-art performance across public datasets.
Key Instance Selection for Unsupervised Video Object Segmentation
Jul 26, 2019

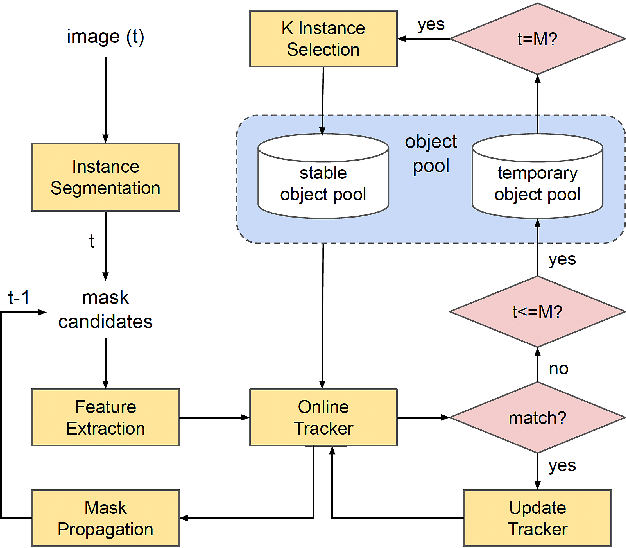
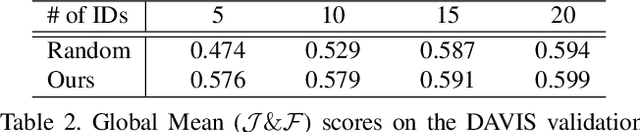
This paper proposes key instance selection based on video saliency covering objectness and dynamics for unsupervised video object segmentation (UVOS). Our method takes frames sequentially and extracts object proposals with corresponding masks for each frame. We link objects according to their similarity until the M-th frame and then assign them unique IDs (i.e., instances). Similarity measure takes into account multiple properties such as ReID descriptor, expected trajectory, and semantic co-segmentation result. After M-th frame, we select K IDs based on video saliency and frequency of appearance; then only these key IDs are tracked through the remaining frames. Thanks to these technical contributions, our results are ranked third on the leaderboard of UVOS DAVIS challenge.