 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSCF: Relation-Semantics Consistent Filter for Entity Embedding of Knowledge Graph
May 28, 2025In knowledge graph embedding, leveraging relation specific entity transformation has markedly enhanced performance. However, the consistency of embedding differences before and after transformation remains unaddressed, risking the loss of valuable inductive bias inherent in the embeddings. This inconsistency stems from two problems. First, transformation representations are specified for relations in a disconnected manner, allowing dissimilar transformations and corresponding entity embeddings for similar relations. Second, a generalized plug-in approach as a SFBR (Semantic Filter Based on Relations) disrupts this consistency through excessive concentration of entity embeddings under entity-based regularization, generating indistinguishable score distributions among relations. In this paper, we introduce a plug-in KGE method, Relation-Semantics Consistent Filter (RSCF). Its entity transformation has three features for enhancing semantic consistency: 1) shared affine transformation of relation embeddings across all relations, 2) rooted entity transformation that adds an entity embedding to its change represented by the transformed vector, and 3) normalization of the change to prevent scale reduction. To amplify the advantages of consistency that preserve semantics on embeddings, RSCF adds relation transformation and prediction modules for enhancing the semantics. In knowledge graph completion tasks with distance-based and tensor decomposition models, RSCF significantly outperforms state-of-the-art KGE methods, showing robustness across all relations and their frequencies.
Efficient COLREGs-Compliant Collision Avoidance using Turning Circle-based Control Barrier Function
Apr 27, 2025This paper proposes a computationally efficient collision avoidance algorithm using turning circle-based control barrier functions (CBFs) that comply with international regulations for preventing collisions at sea (COLREGs). Conventional CBFs often lack explicit consideration of turning capabilities and avoidance direction, which are key elements in developing a COLREGs-compliant collision avoidance algorithm. To overcome these limitations, we introduce two CBFs derived from left and right turning circles. These functions establish safety conditions based on the proximity between the traffic ships and the centers of the turning circles, effectively determining both avoidance directions and turning capabilities. The proposed method formulates a quadratic programming problem with the CBFs as constraints, ensuring safe navigation without relying on computationally intensive trajectory optimization. This approach significantly reduces computational effort while maintaining performance comparable to model predictive control-based methods. Simulation results validate the effectiveness of the proposed algorithm in enabling COLREGs-compliant, safe navigation, demonstrating its potential for reliable and efficient operation in complex maritime environments.
Structural Optimization Ambiguity and Simplicity Bias in Unsupervised Neural Grammar Induction
Jul 23, 2024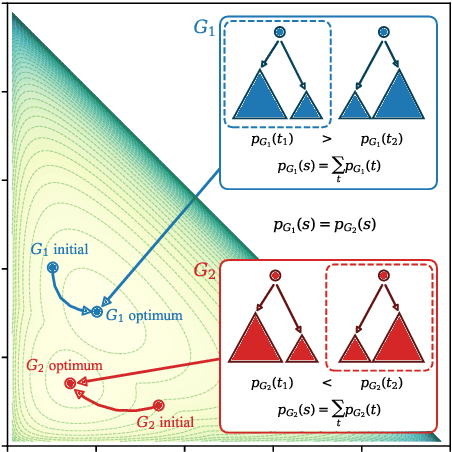
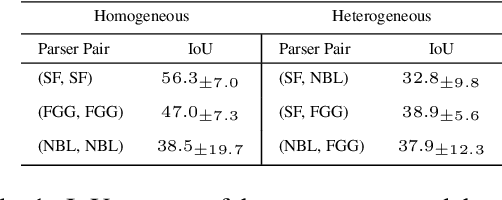
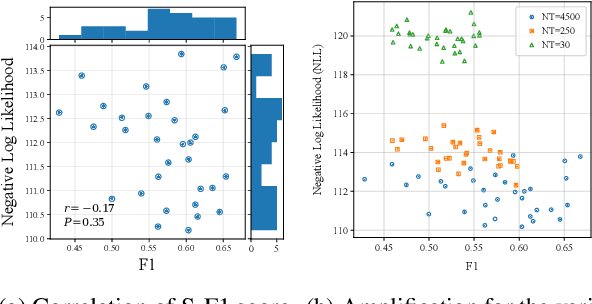
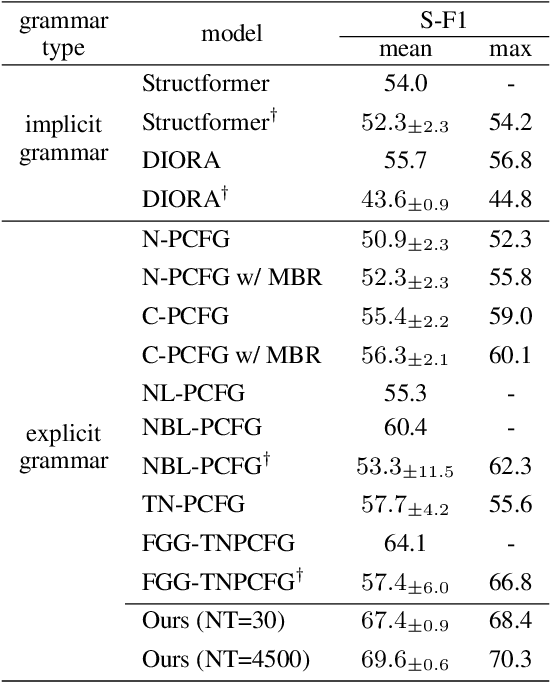
Neural parameterization has significantly advanced unsupervised grammar induction. However, training these models with a traditional likelihood loss for all possible parses exacerbates two issues: 1) $\textit{structural optimization ambiguity}$ that arbitrarily selects one among structurally ambiguous optimal grammars despite the specific preference of gold parses, and 2) $\textit{structural simplicity bias}$ that leads a model to underutilize rules to compose parse trees. These challenges subject unsupervised neural grammar induction (UNGI) to inevitable prediction errors, high variance, and the necessity for extensive grammars to achieve accurate predictions. This paper tackles these issues, offering a comprehensive analysis of their origins. As a solution, we introduce $\textit{sentence-wise parse-focusing}$ to reduce the parse pool per sentence for loss evaluation, using the structural bias from pre-trained parsers on the same dataset. In unsupervised parsing benchmark tests, our method significantly improves performance while effectively reducing variance and bias toward overly simplistic parses. Our research promotes learning more compact, accurate, and consistent explicit grammars, facilitating better interpretability.