 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttr-Int: A Simple and Effective Entity Alignment Framework for Heterogeneous Knowledge Graphs
Oct 17, 2024



Entity alignment (EA) refers to the task of linking entities in different knowledge graphs (KGs). Existing EA methods rely heavily on structural isomorphism. However, in real-world KGs, aligned entities usually have non-isomorphic neighborhood structures, which paralyses the application of these structure-dependent methods. In this paper, we investigate and tackle the problem of entity alignment between heterogeneous KGs. First, we propose two new benchmarks to closely simulate real-world EA scenarios of heterogeneity. Then we conduct extensive experiments to evaluate the performance of representative EA methods on the new benchmarks. Finally, we propose a simple and effective entity alignment framework called Attr-Int, in which innovative attribute information interaction methods can be seamlessly integrated with any embedding encoder for entity alignment, improving the performance of existing entity alignment techniques. Experiments demonstrate that our framework outperforms the state-of-the-art approaches on two new benchmarks.
P-NAL: an Effective and Interpretable Entity Alignment Method
Apr 18, 2024Entity alignment (EA) aims to find equivalent entities between two Knowledge Graphs. Existing embedding-based EA methods usually encode entities as embeddings, triples as embeddings' constraint and learn to align the embeddings. The structural and side information are usually utilized via embedding propagation, aggregation or interaction. However, the details of the underlying logical inference steps among the alignment process are usually omitted, resulting in inadequate inference process. In this paper, we introduce P-NAL, an entity alignment method that captures two types of logical inference paths with Non-Axiomatic Logic (NAL). Type 1 is the bridge-like inference path between to-be-aligned entity pairs, consisting of two relation/attribute triples and a similarity sentence between the other two entities. Type 2 links the entity pair by their embeddings. P-NAL iteratively aligns entities and relations by integrating the conclusions of the inference paths. Moreover, our method is logically interpretable and extensible due to the expressiveness of NAL. Our proposed method is suitable for various EA settings. Experimental results show that our method outperforms state-of-the-art methods in terms of Hits@1, achieving 0.98+ on all three datasets of DBP15K with both supervised and unsupervised settings. To our knowledge, we present the first in-depth analysis of entity alignment's basic principles from a unified logical perspective.
Consolidating Commonsense Knowledge
Jun 22, 2020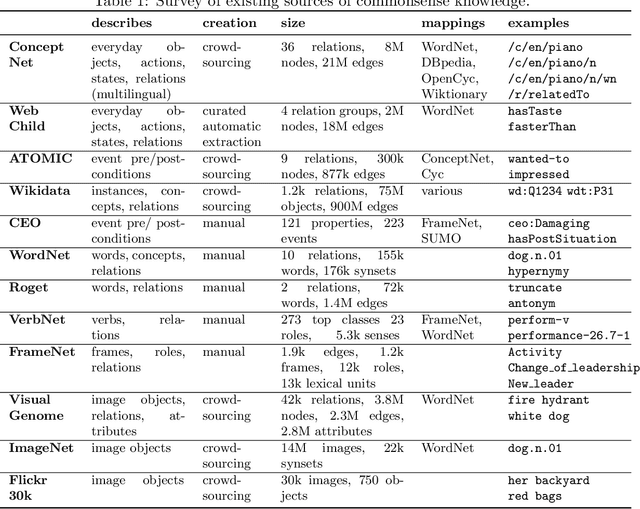
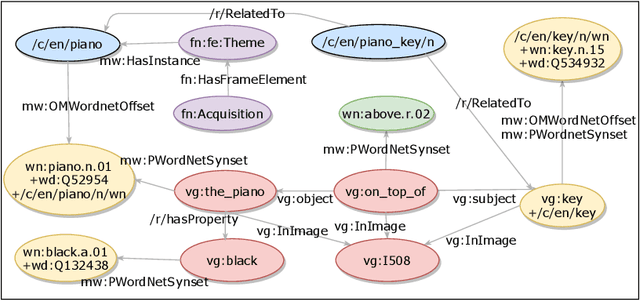

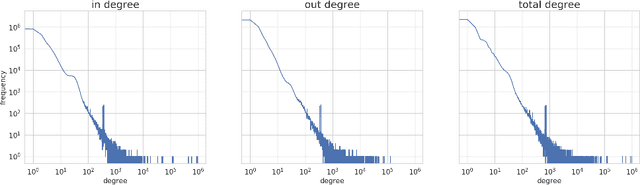
Commonsense reasoning is an important aspect of building robust AI systems and is receiving significant attention in the natural language understanding, computer vision, and knowledge graphs communities. At present, a number of valuable commonsense knowledge sources exist, with different foci, strengths, and weaknesses. In this paper, we list representative sources and their properties. Based on this survey, we propose principles and a representation model in order to consolidate them into a Common Sense Knowledge Graph (CSKG). We apply this approach to consolidate seven separate sources into a first integrated CSKG. We present statistics of CSKG, present initial investigations of its utility on four QA datasets, and list learned lessons.