 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
LASER: Learning Active Sensing for Continuum Field Reconstruction
Apr 21, 2026High-fidelity measurements of continuum physical fields are essential for scientific discovery and engineering design but remain challenging under sparse and constrained sensing. Conventional reconstruction methods typically rely on fixed sensor layouts, which cannot adapt to evolving physical states. We propose LASER, a unified, closed-loop framework that formulates active sensing as a Partially Observable Markov Decision Process (POMDP). At its core, LASER employs a continuum field latent world model that captures the underlying physical dynamics and provides intrinsic reward feedback. This enables a reinforcement learning policy to simulate ''what-if'' sensing scenarios within a latent imagination space. By conditioning sensor movements on predicted latent states, LASER navigates toward potentially high-information regions beyond current observations. Our experiments demonstrate that LASER consistently outperforms static and offline-optimized strategies, achieving high-fidelity reconstruction under sparsity across diverse continuum fields.
Discovering Mathematical Equations with Diffusion Language Model
Sep 16, 2025Discovering valid and meaningful mathematical equations from observed data plays a crucial role in scientific discovery. While this task, symbolic regression, remains challenging due to the vast search space and the trade-off between accuracy and complexity. In this paper, we introduce DiffuSR, a pre-training framework for symbolic regression built upon a continuous-state diffusion language model. DiffuSR employs a trainable embedding layer within the diffusion process to map discrete mathematical symbols into a continuous latent space, modeling equation distributions effectively. Through iterative denoising, DiffuSR converts an initial noisy sequence into a symbolic equation, guided by numerical data injected via a cross-attention mechanism. We also design an effective inference strategy to enhance the accuracy of the diffusion-based equation generator, which injects logit priors into genetic programming. Experimental results on standard symbolic regression benchmarks demonstrate that DiffuSR achieves competitive performance with state-of-the-art autoregressive methods and generates more interpretable and diverse mathematical expressions.
ConvNext Based Neural Network for Anti-Spoofing
Sep 15, 2022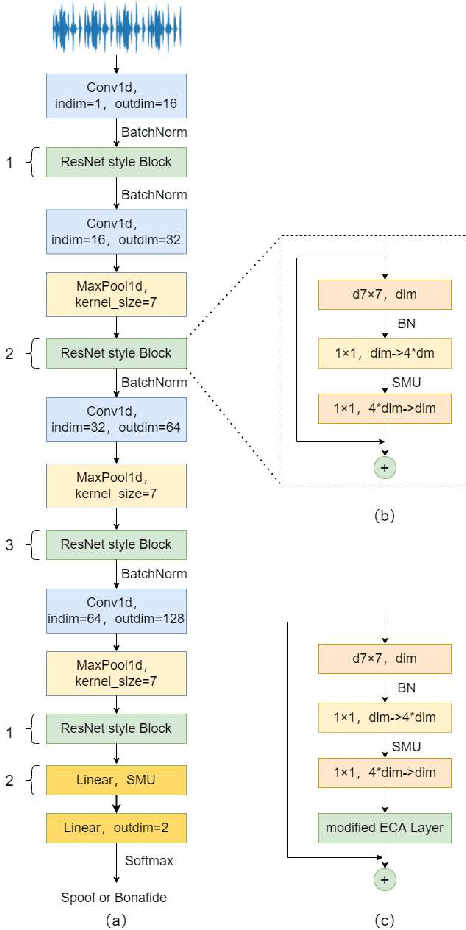
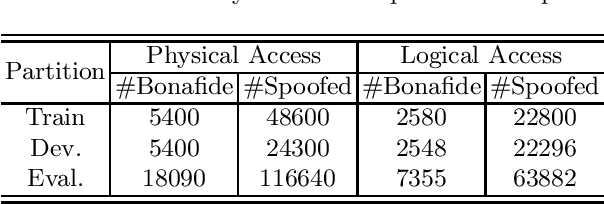
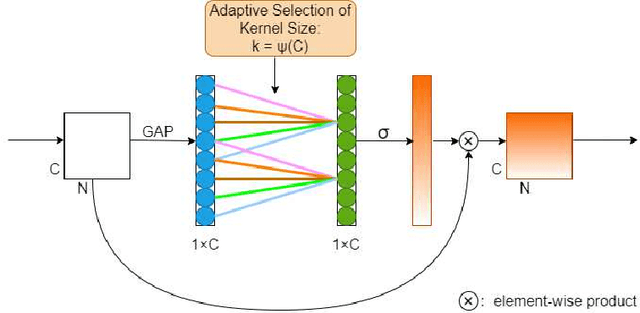
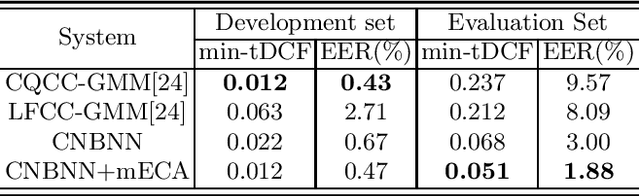
Automatic speaker verification (ASV) has been widely used in the real life for identity authentication. However, with the rapid development of speech conversion, speech synthesis algorithms and the improvement of the quality of recording devices, ASV systems are vulnerable for spoof attacks. In recent years, there have many works about synthetic and replay speech detection, researchers had proposed a number of anti-spoofing methods based on hand-crafted features to improve the accuracy and robustness of synthetic and replay speech detection system. However, using hand-crafted features rather than raw waveform would lose certain information for anti-spoofing, which will reduce the detection performance of the system. Inspired by the promising performance of ConvNext in image classification tasks, we extend the ConvNext network architecture accordingly for spoof attacks detection task and propose an end-to-end anti-spoofing model. By integrating the extended architecture with the channel attention block, the proposed model can focus on the most informative sub-bands of speech representations to improve the anti-spoofing performance. Experiments show that our proposed best single system could achieve an equal error rate of 1.88% and 2.79% for the ASVSpoof 2019 LA evaluation dataset and PA evaluation dataset respectively, which demonstrate the model's capacity for anti-spoofing.