 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtterance-level Permutation Invariant Training with Latency-controlled BLSTM for Single-channel Multi-talker Speech Separation
Dec 25, 2019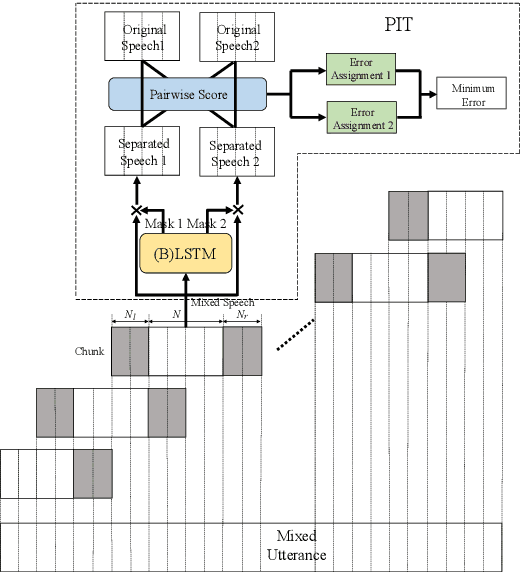
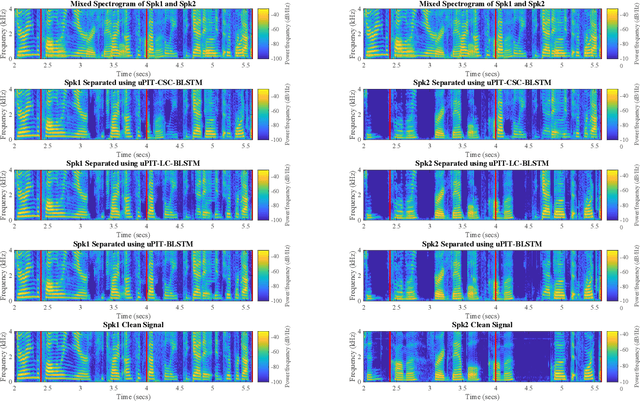
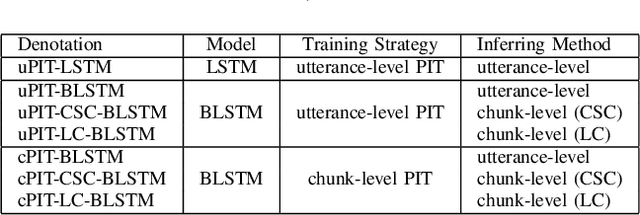
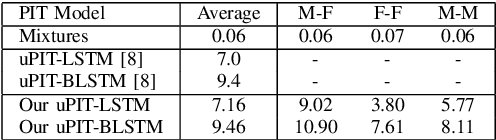
Utterance-level permutation invariant training (uPIT) has achieved promising progress on single-channel multi-talker speech separation task. Long short-term memory (LSTM) and bidirectional LSTM (BLSTM) are widely used as the separation networks of uPIT, i.e. uPIT-LSTM and uPIT-BLSTM. uPIT-LSTM has lower latency but worse performance, while uPIT-BLSTM has better performance but higher latency. In this paper, we propose using latency-controlled BLSTM (LC-BLSTM) during inference to fulfill low-latency and good-performance speech separation. To find a better training strategy for BLSTM-based separation network, chunk-level PIT (cPIT) and uPIT are compared. The experimental results show that uPIT outperforms cPIT when LC-BLSTM is used during inference. It is also found that the inter-chunk speaker tracing (ST) can further improve the separation performance of uPIT-LC-BLSTM. Evaluated on the WSJ0 two-talker mixed-speech separation task, the absolute gap of signal-to-distortion ratio (SDR) between uPIT-BLSTM and uPIT-LC-BLSTM is reduced to within 0.7 dB.
An Improved Residual LSTM Architecture for Acoustic Modeling
Aug 17, 2017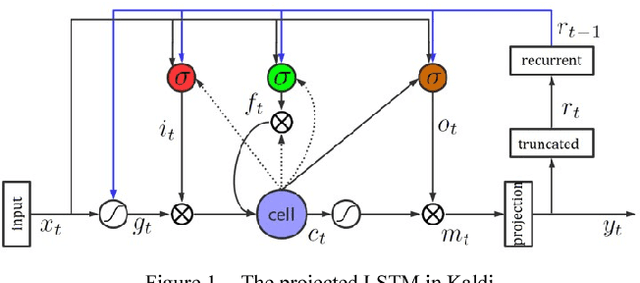
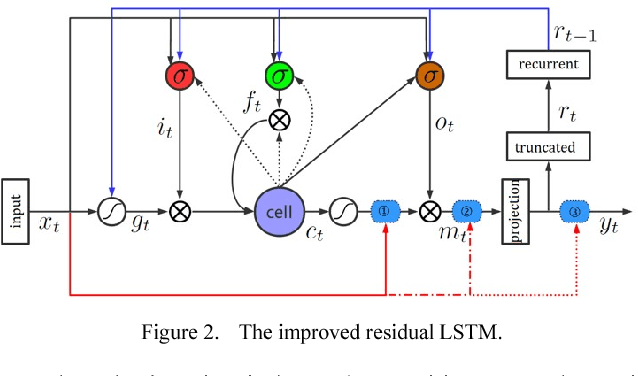
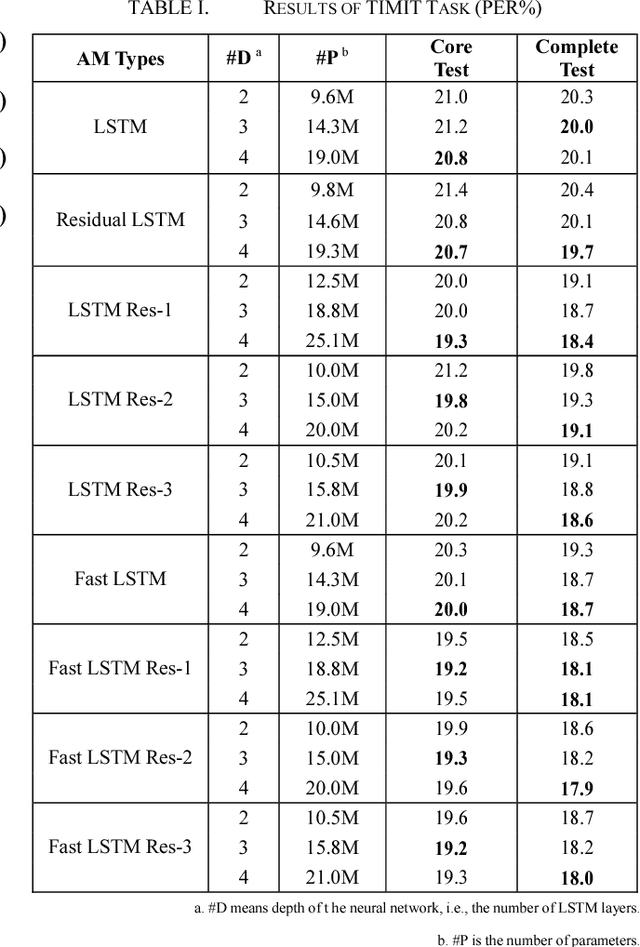
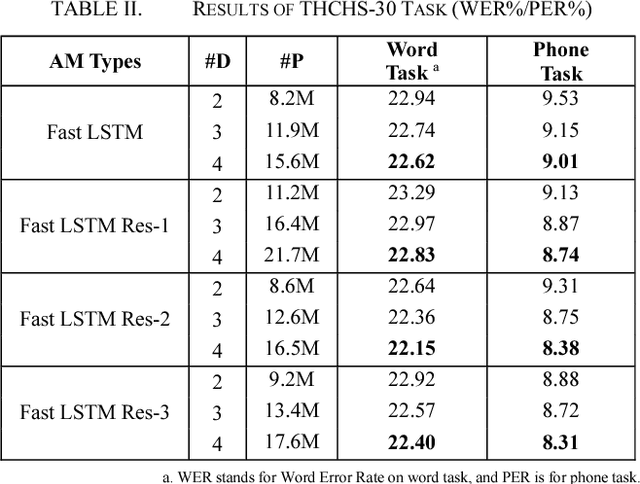
Long Short-Term Memory (LSTM) is the primary recurrent neural networks architecture for acoustic modeling in automatic speech recognition systems. Residual learning is an efficient method to help neural networks converge easier and faster. In this paper, we propose several types of residual LSTM methods for our acoustic modeling. Our experiments indicate that, compared with classic LSTM, our architecture shows more than 8% relative reduction in Phone Error Rate (PER) on TIMIT tasks. At the same time, our residual fast LSTM approach shows 4% relative reduction in PER on the same task. Besides, we find that all this architecture could have good results on THCHS-30, Librispeech and Switchboard corpora.