 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Disease Progress with Imprecise Lab Test Results
Jul 08, 2021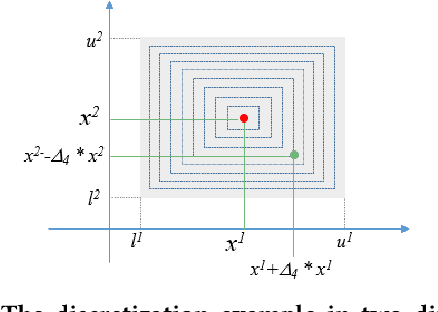
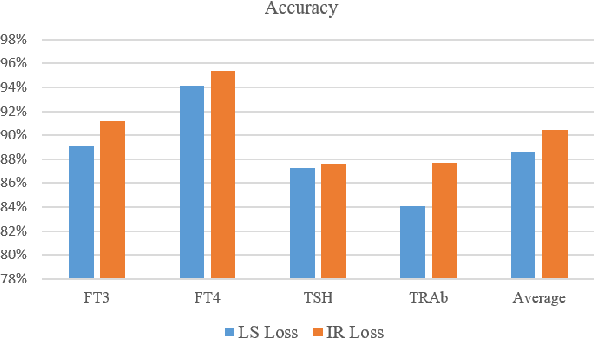
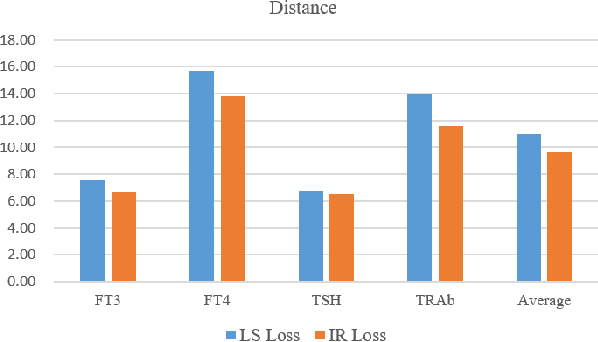
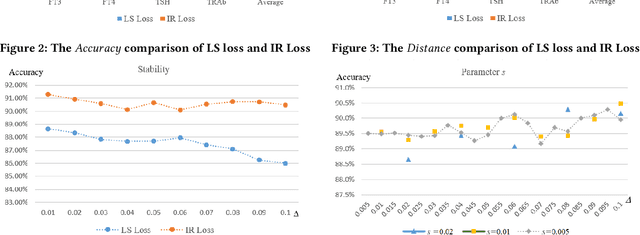
In existing deep learning methods, almost all loss functions assume that sample data values used to be predicted are the only correct ones. This assumption does not hold for laboratory test data. Test results are often within tolerable or imprecision ranges, with all values in the ranges acceptable. By considering imprecision samples, we propose an imprecision range loss (IR loss) method and incorporate it into Long Short Term Memory (LSTM) model for disease progress prediction. In this method, each sample in imprecision range space has a certain probability to be the real value, participating in the loss calculation. The loss is defined as the integral of the error of each point in the impression range space. A sampling method for imprecision space is formulated. The continuous imprecision space is discretized, and a sequence of imprecise data sets are obtained, which is convenient for gradient descent learning. A heuristic learning algorithm is developed to learn the model parameters based on the imprecise data sets. Experimental results on real data show that the prediction method based on IR loss can provide more stable and consistent prediction result when test samples are generated from imprecision range.
Impact of Medical Data Imprecision on Learning Results
Jul 24, 2020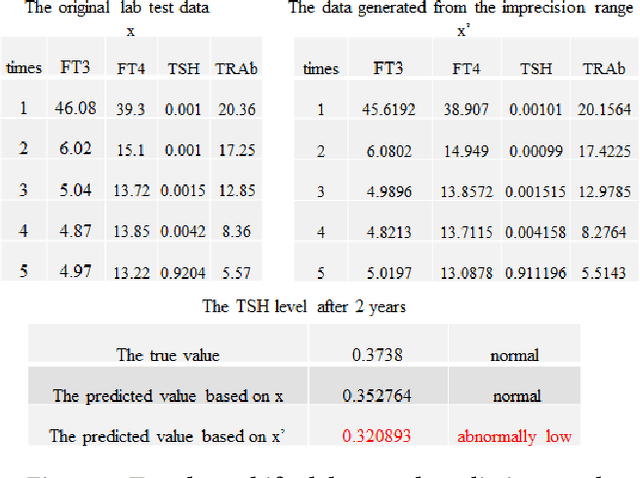
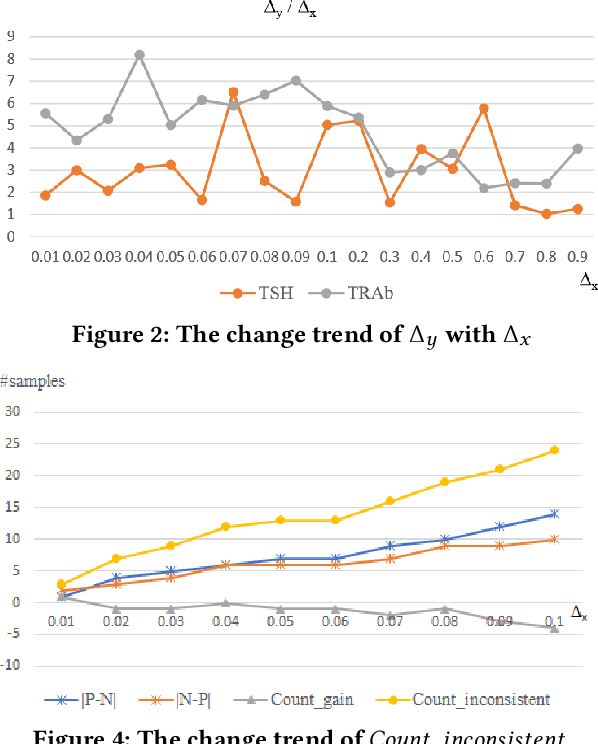
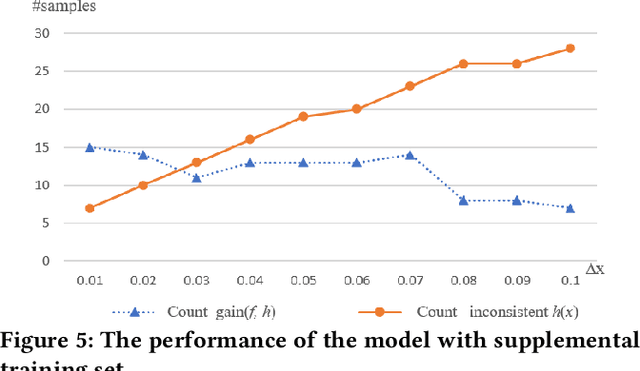
Test data measured by medical instruments often carry imprecise ranges that include the true values. The latter are not obtainable in virtually all cases. Most learning algorithms, however, carry out arithmetical calculations that are subject to uncertain influence in both the learning process to obtain models and applications of the learned models in, e.g. prediction. In this paper, we initiate a study on the impact of imprecision on prediction results in a healthcare application where a pre-trained model is used to predict future state of hyperthyroidism for patients. We formulate a model for data imprecisions. Using parameters to control the degree of imprecision, imprecise samples for comparison experiments can be generated using this model. Further, a group of measures are defined to evaluate the different impacts quantitatively. More specifically, the statistics to measure the inconsistent prediction for individual patients are defined. We perform experimental evaluations to compare prediction results based on the data from the original dataset and the corresponding ones generated from the proposed precision model using the long-short-term memories (LSTM) network. The results against a real world hyperthyroidism dataset provide insights into how small imprecisions can cause large ranges of predicted results, which could cause mis-labeling and inappropriate actions (treatments or no treatments) for individual patients.