 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluence-Based Multi-Agent Exploration
Oct 12, 2019
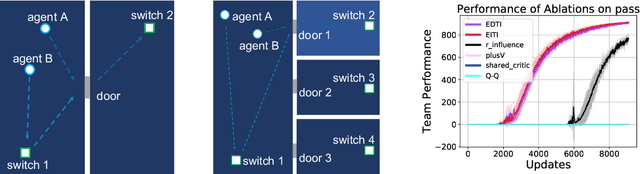
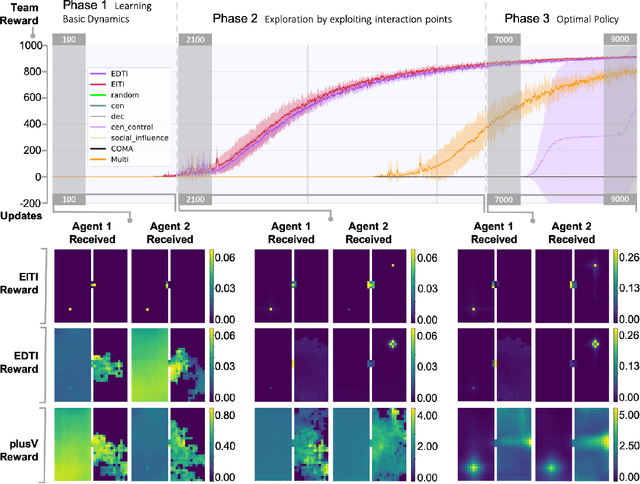
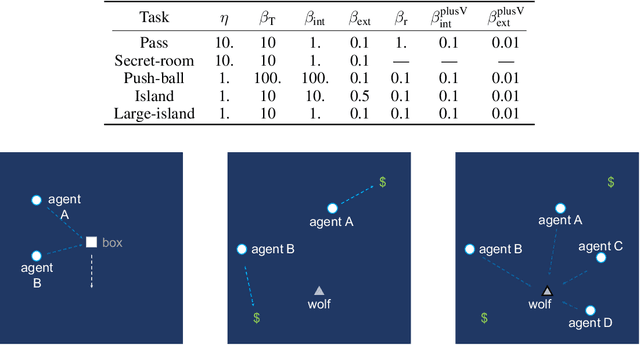
Intrinsically motivated reinforcement learning aims to address the exploration challenge for sparse-reward tasks. However, the study of exploration methods in transition-dependent multi-agent settings is largely absent from the literature. We aim to take a step towards solving this problem. We present two exploration methods: exploration via information-theoretic influence (EITI) and exploration via decision-theoretic influence (EDTI), by exploiting the role of interaction in coordinated behaviors of agents. EITI uses mutual information to capture influence transition dynamics. EDTI uses a novel intrinsic reward, called Value of Interaction (VoI), to characterize and quantify the influence of one agent's behavior on expected returns of other agents. By optimizing EITI or EDTI objective as a regularizer, agents are encouraged to coordinate their exploration and learn policies to optimize team performance. We show how to optimize these regularizers so that they can be easily integrated with policy gradient reinforcement learning. The resulting update rule draws a connection between coordinated exploration and intrinsic reward distribution. Finally, we empirically demonstrate the significant strength of our method in a variety of multi-agent scenarios.
Learning Nearly Decomposable Value Functions Via Communication Minimization
Oct 11, 2019



Reinforcement learning encounters major challenges in multi-agent settings, such as scalability and non-stationarity. Recently, value function factorization learning emerges as a promising way to address these challenges in collaborative multi-agent systems. However, existing methods have been focusing on learning fully decentralized value function, which are not efficient for tasks requiring communication. To address this limitation, this paper presents a novel framework for learning nearly decomposable value functions with communication, with which agents act on their own most of the time but occasionally send messages to other agents in order for effective coordination. This framework hybridizes value function factorization learning and communication learning by introducing two information-theoretic regularizers. These regularizers are maximizing mutual information between decentralized Q functions and communication messages while minimizing the entropy of messages between agents. We show how to optimize these regularizers in a way that is easily integrated with existing value function factorization methods such as QMIX. Finally, we demonstrate that, on the StarCraft unit micromanagement benchmark, our framework significantly outperforms baseline methods and allows to cut off more than $80\%$ communication without sacrificing the performance. The video of our experiments is available at https://sites.google.com/view/ndvf.
Object-Oriented Dynamics Learning through Multi-Level Abstraction
May 25, 2019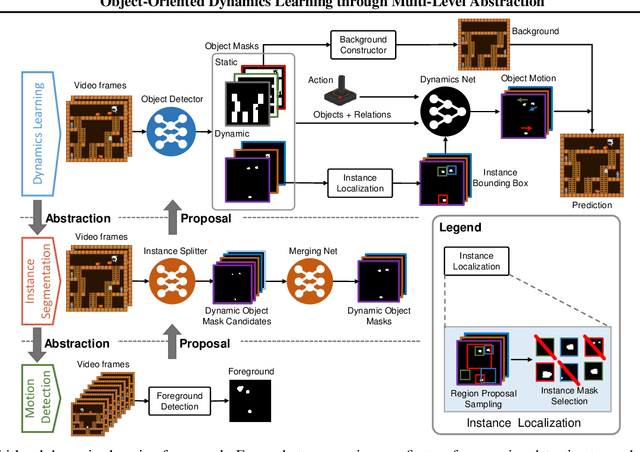
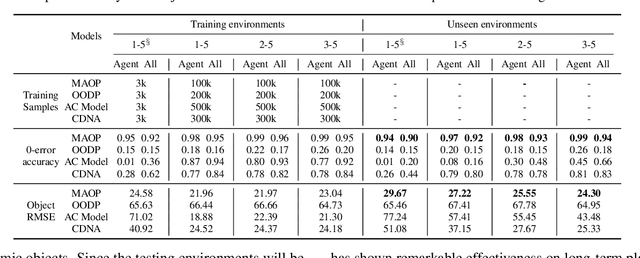
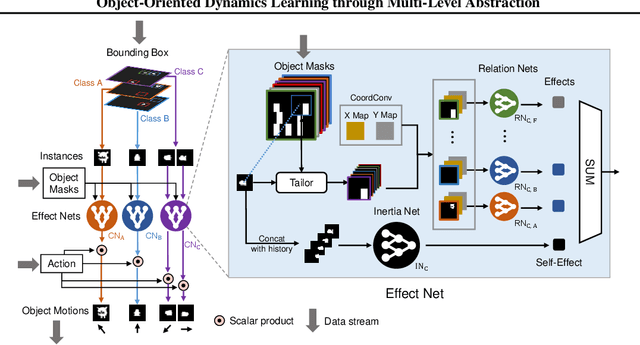
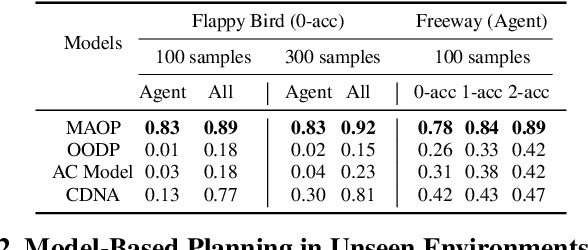
Object-based approaches for learning action-conditioned dynamics has demonstrated promise for generalization and interpretability. However, existing approaches suffer from structural limitations and optimization difficulties for common environments with multiple dynamic objects. In this paper, we present a novel self-supervised learning framework, called Multi-level Abstraction Object-oriented Predictor (MAOP), which employs a three-level learning architecture that enables efficient object-based dynamics learning from raw visual observations. We also design a spatial-temporal relational reasoning mechanism for MAOP to support instance-level dynamics learning and handle partial observability. Our results show that MAOP significantly outperforms previous methods in terms of sample efficiency and generalization over novel environments for learning environment models. We also demonstrate that learned dynamics models enable efficient planning in unseen environments, comparable to true environment models. In addition, MAOP learns semantically and visually interpretable disentangled representations.