 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Representation Learning for Conservative Linear Bandits
May 12, 2026This paper presents the Constrained Multi-Task Representation Learning (CMTRL) framework for linear bandits. We consider T linear bandit tasks in a d dimensional space, which share a common low-dimensional representation of dimension r, where r is much smaller than the minimum of d and T. Furthermore, tasks are constrained so that only actions meeting specific safety or performance requirements are allowed, referred to as conservative (safe) bandits. We introduce a novel algorithm, Safe-Alternating projected Gradient Descent and minimization (Safe-AltGDmin), to recover a low-rank feature matrix while satisfying the given constraints. Building on this algorithm, we propose a multi-task representation learning framework for conservative linear bandits and establish theoretical guarantees for its regret and sample complexity bounds. We presented experiments and compared the performance of our algorithm with benchmark algorithms.
Learning Shared Representations for Multi-Task Linear Bandits
Apr 01, 2026Multi-task representation learning is an approach that learns shared latent representations across related tasks, facilitating knowledge transfer and improving sample efficiency. This paper introduces a novel approach to multi-task representation learning in linear bandits. We consider a setting with T concurrent linear bandit tasks, each with feature dimension d, that share a common latent representation of dimension r \ll min{d,T}$, capturing their underlying relatedness. We propose a new Optimism in the Face of Uncertainty Linear (OFUL) algorithm that leverages shared low-rank representations to enhance decision-making in a sample-efficient manner. Our algorithm first collects data through an exploration phase, estimates the shared model via spectral initialization, and then conducts OFUL based learning over a newly constructed confidence set. We provide theoretical guarantees for the confidence set and prove that the unknown reward vectors lie within the confidence set with high probability. We derive cumulative regret bounds and show that the proposed approach achieves \tilde{O}(\sqrt{drNT}), a significant improvement over solving the T tasks independently, resulting in a regret of \tilde{O}(dT\sqrt{N}). We performed numerical simulations to validate the performance of our algorithm for different problem sizes.
Fast and Sample Efficient Multi-Task Representation Learning in Stochastic Contextual Bandits
Oct 02, 2024

We study how representation learning can improve the learning efficiency of contextual bandit problems. We study the setting where we play T contextual linear bandits with dimension d simultaneously, and these T bandit tasks collectively share a common linear representation with a dimensionality of r much smaller than d. We present a new algorithm based on alternating projected gradient descent (GD) and minimization estimator to recover a low-rank feature matrix. Using the proposed estimator, we present a multi-task learning algorithm for linear contextual bandits and prove the regret bound of our algorithm. We presented experiments and compared the performance of our algorithm against benchmark algorithms.
Distributed Multi-Task Learning for Stochastic Bandits with Context Distribution and Stage-wise Constraints
Jan 21, 2024



We present the problem of conservative distributed multi-task learning in stochastic linear contextual bandits with heterogeneous agents. This extends conservative linear bandits to a distributed setting where M agents tackle different but related tasks while adhering to stage-wise performance constraints. The exact context is unknown, and only a context distribution is available to the agents as in many practical applications that involve a prediction mechanism to infer context, such as stock market prediction and weather forecast. We propose a distributed upper confidence bound (UCB) algorithm, DiSC-UCB. Our algorithm constructs a pruned action set during each round to ensure the constraints are met. Additionally, it includes synchronized sharing of estimates among agents via a central server using well-structured synchronization steps. We prove the regret and communication bounds on the algorithm. We extend the problem to a setting where the agents are unaware of the baseline reward. For this setting, we provide a modified algorithm, DiSC-UCB2, and we show that the modified algorithm achieves the same regret and communication bounds. We empirically validated the performance of our algorithm on synthetic data and real-world Movielens-100K data.
Federated Stochastic Bandit Learning with Unobserved Context
Mar 29, 2023
We study the problem of federated stochastic multi-arm contextual bandits with unknown contexts, in which M agents are faced with different bandits and collaborate to learn. The communication model consists of a central server and the agents share their estimates with the central server periodically to learn to choose optimal actions in order to minimize the total regret. We assume that the exact contexts are not observable and the agents observe only a distribution of the contexts. Such a situation arises, for instance, when the context itself is a noisy measurement or based on a prediction mechanism. Our goal is to develop a distributed and federated algorithm that facilitates collaborative learning among the agents to select a sequence of optimal actions so as to maximize the cumulative reward. By performing a feature vector transformation, we propose an elimination-based algorithm and prove the regret bound for linearly parametrized reward functions. Finally, we validated the performance of our algorithm and compared it with another baseline approach using numerical simulations on synthetic data and on the real-world movielens dataset.
Distributed Stochastic Bandit Learning with Context Distributions
Jul 28, 2022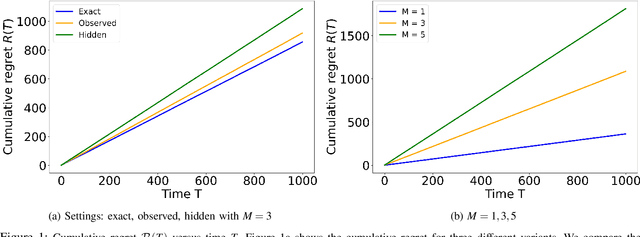
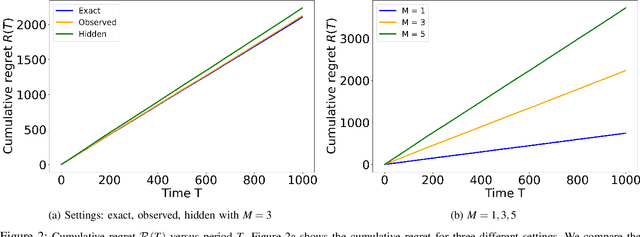
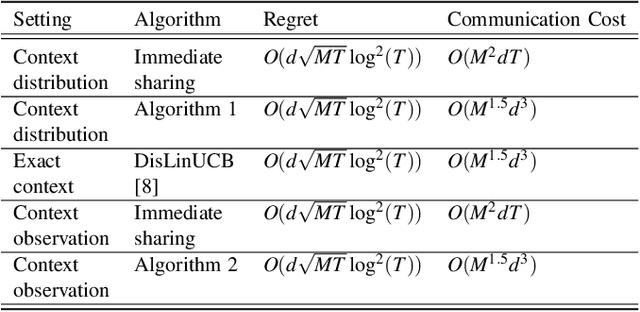
We study the problem of distributed stochastic multi-arm contextual bandit with unknown contexts, in which M agents work collaboratively to choose optimal actions under the coordination of a central server in order to minimize the total regret. In our model, an adversary chooses a distribution on the set of possible contexts and the agents observe only the context distribution and the exact context is unknown to the agents. Such a situation arises, for instance, when the context itself is a noisy measurement or based on a prediction mechanism as in weather forecasting or stock market prediction. Our goal is to develop a distributed algorithm that selects a sequence of optimal actions to maximize the cumulative reward. By performing a feature vector transformation and by leveraging the UCB algorithm, we propose a UCB algorithm for stochastic bandits with context distribution and prove that our algorithm achieves a regret and communications bounds of $O(d\sqrt{MT}log^2T)$ and $O(M^{1.5}d^3)$, respectively, for linearly parametrized reward functions. We also consider a case where the agents observe the actual context after choosing the action. For this setting we presented a modified algorithm that utilizes the additional information to achieve a tighter regret bound. Finally, we validated the performance of our algorithms and compared it with other baseline approaches using extensive simulations on synthetic data and on the real world movielens dataset.
Stochastic Conservative Contextual Linear Bandits
Mar 29, 2022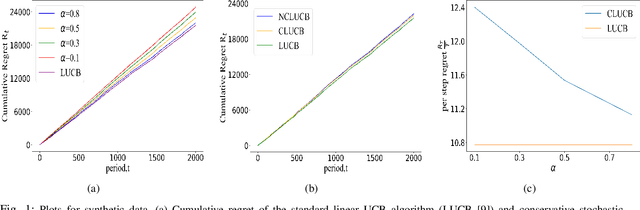
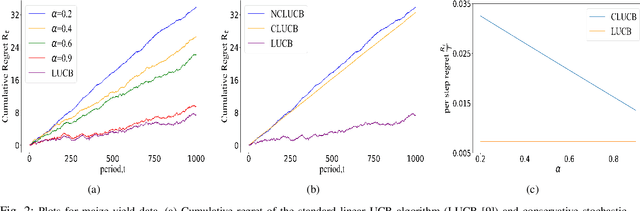
Many physical systems have underlying safety considerations that require that the strategy deployed ensures the satisfaction of a set of constraints. Further, often we have only partial information on the state of the system. We study the problem of safe real-time decision making under uncertainty. In this paper, we formulate a conservative stochastic contextual bandit formulation for real-time decision making when an adversary chooses a distribution on the set of possible contexts and the learner is subject to certain safety/performance constraints. The learner observes only the context distribution and the exact context is unknown, and the goal is to develop an algorithm that selects a sequence of optimal actions to maximize the cumulative reward without violating the safety constraints at any time step. By leveraging the UCB algorithm for this setting, we propose a conservative linear UCB algorithm for stochastic bandits with context distribution. We prove an upper bound on the regret of the algorithm and show that it can be decomposed into three terms: (i) an upper bound for the regret of the standard linear UCB algorithm, (ii) a constant term (independent of time horizon) that accounts for the loss of being conservative in order to satisfy the safety constraint, and (ii) a constant term (independent of time horizon) that accounts for the loss for the contexts being unknown and only the distribution being known. To validate the performance of our approach we perform extensive simulations on synthetic data and on real-world maize data collected through the Genomes to Fields (G2F) initiative.