 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating on Incorporating Pretrained and Learnable Speaker Representations for Multi-Speaker Multi-Style Text-to-Speech
Mar 20, 2021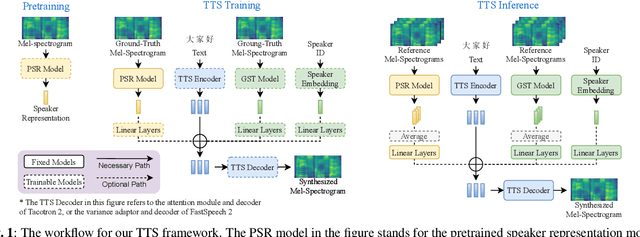
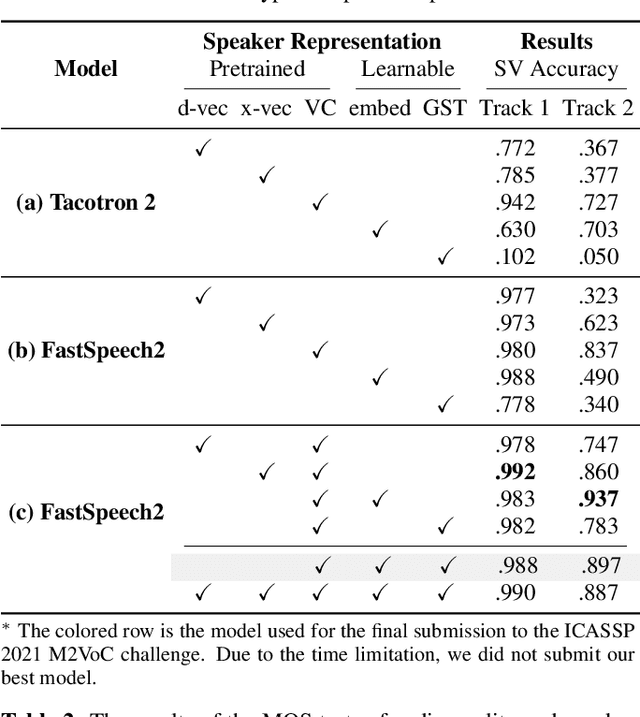
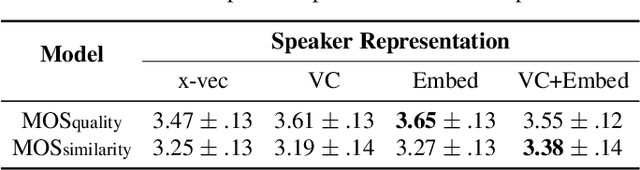

The few-shot multi-speaker multi-style voice cloning task is to synthesize utterances with voice and speaking style similar to a reference speaker given only a few reference samples. In this work, we investigate different speaker representations and proposed to integrate pretrained and learnable speaker representations. Among different types of embeddings, the embedding pretrained by voice conversion achieves the best performance. The FastSpeech 2 model combined with both pretrained and learnable speaker representations shows great generalization ability on few-shot speakers and achieved 2nd place in the one-shot track of the ICASSP 2021 M2VoC challenge.
FragmentVC: Any-to-Any Voice Conversion by End-to-End Extracting and Fusing Fine-Grained Voice Fragments With Attention
Oct 27, 2020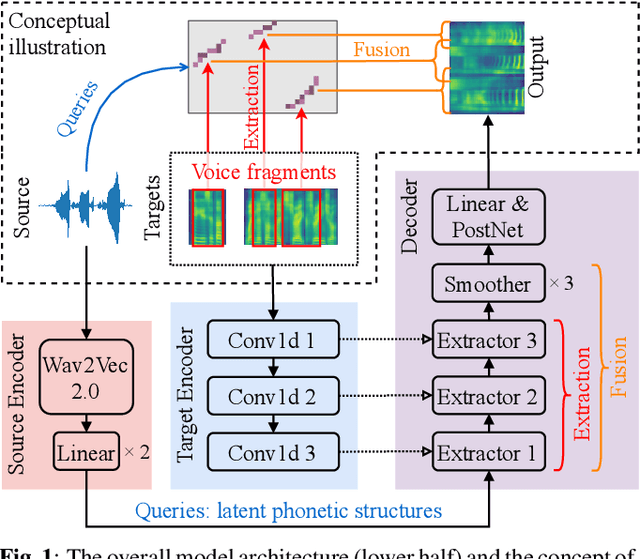

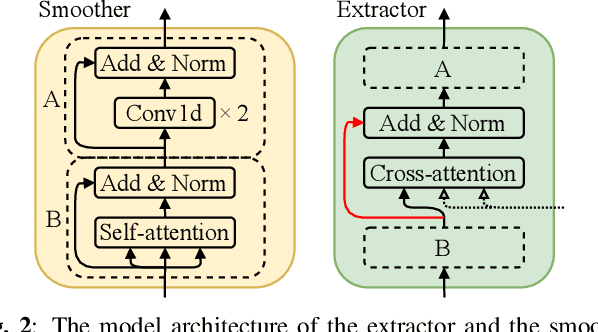

Any-to-any voice conversion aims to convert the voice from and to any speakers even unseen during training, which is much more challenging compared to one-to-one or many-to-many tasks, but much more attractive in real-world scenarios. In this paper we proposed FragmentVC, in which the latent phonetic structure of the utterance from the source speaker is obtained from Wav2Vec 2.0, while the spectral features of the utterance(s) from the target speaker are obtained from log mel-spectrograms. By aligning the hidden structures of the two different feature spaces with a two-stage training process, FragmentVC is able to extract fine-grained voice fragments from the target speaker utterance(s) and fuse them into the desired utterance, all based on the attention mechanism of Transformer as verified with analysis on attention maps, and is accomplished end-to-end. This approach is trained with reconstruction loss only without any disentanglement considerations between content and speaker information and doesn't require parallel data. Objective evaluation based on speaker verification and subjective evaluation with MOS both showed that this approach outperformed SOTA approaches, such as AdaIN-VC and AutoVC.