 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Lengthening as a Function of Utterance Position: A Multi-Corpus Study
Jun 22, 2026Efficient turn-taking requires interlocutors to predict turn endings within a few hundred milliseconds. Beyond syntactic and pragmatic completion, prosody (especially pre-boundary lengthening) supports projection. We test whether turn-final words are longer than mid-sentence words, whether this reflects prosodic modification rather than lexical choice, and where within the word it concentrates. We analyze four corpora spanning styles and two languages (English, Spanish): Switchboard, Columbia Games, BU Radio, and Glissando, with >500 speakers, $39{,}470$ turn-final and $206{,}268$ mid-sentence tokens across $\sim39{,}500$ turns. Turn-final words are longer (mean ${\approx}191$\,ms; $d=1.14$). The effect persists in matched-word, within-speaker comparisons ($80$\,ms; $p<0.001$) and is localized mainly to the final syllable ($d=0.89$). Turn-final lengthening thus emerges as a robust, localized cue to floor transfer.
Acoustic Landmark Detector based on Conformer and HuBERT
Jun 22, 2026Acoustic landmarks (abrupt acoustic changes tied to speech events) offer a linguistically grounded representation for speech analysis. We study automatic landmark detection with Conformer models, evaluating 14 configurations spanning architecture, loss, label representation, feature extractor, and data conditions on 1 839 manually annotated utterances with eight landmark types. We propose Gaussian soft labels with per-class temporal spread (sigma=10-20 ms), improving F1-at-20 ms by 7.0% absolute vs. hard labels by modeling annotation variability. Frozen HuBERT features perform best without fine-tuning (F1-at-20 ms=0.77). Stops and fricatives are reliable (F1>0.80), while vowels remain challenging (F1 approx 0.55). On our corpus, our system reaches a 13.8% Landmark Error Rate (LER). This is not directly comparable to AutoLandmark (31.3%) or SpeechMark (56.5%), evaluated on a different corpus and metric. Per-class trends show detectability increases with event abruptness, consistent with Stevens' theory.
An Acoustic Landmark Database of the English Lexicon via Articulatory Synthesis
Jun 22, 2026Acoustic landmark theory treats speech as organized around the acoustic consequences of articulatory gestures that shape the vocal tract and airflow. Progress is limited by the scarcity of large, unambiguously annotated landmark datasets. We invert the problem by generating speech from landmark patterns. Using the Pink Trombone physical vocal-tract synthesizer, we produce an English lexicon for two adult configurations (male, female). With direct control of gestures, we place landmark labels algorithmically at the exact times of their physical events (e.g., oral closures/releases). The corpus contains $>$200,000 synthesized words, rendered for both configurations with time-aligned annotations; intelligibility is measured with STOI. We leverage it for statistics across the lexicon from an articulatory-event view, reporting landmark frequencies and dominant cue patterns, and enabling quantitative studies plus training/benchmarking of automatic landmark detectors.
Lexical Access Model for Italian -- Modeling human speech processing: identification of words in running speech toward lexical access based on the detection of landmarks and other acoustic cues to features
Jun 24, 2021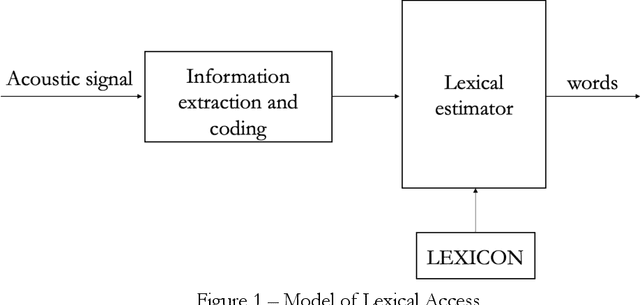
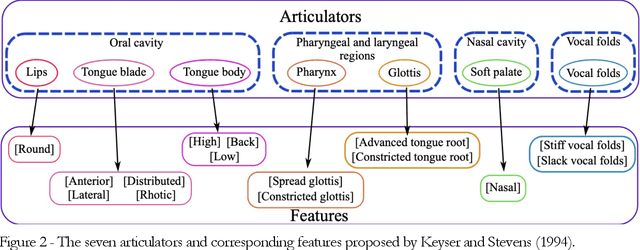
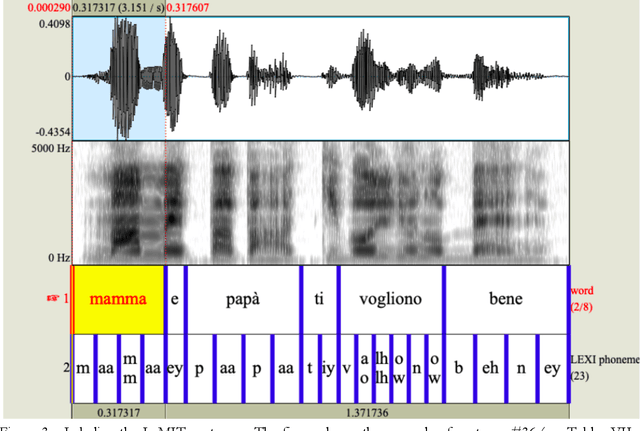
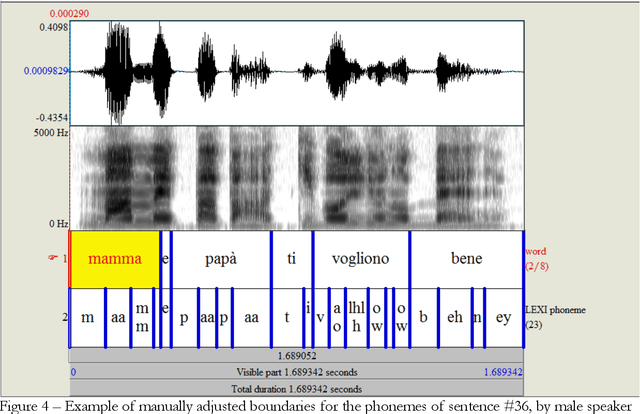
Modelling the process that a listener actuates in deriving the words intended by a speaker requires setting a hypothesis on how lexical items are stored in memory. This work aims at developing a system that imitates humans when identifying words in running speech and, in this way, provide a framework to better understand human speech processing. We build a speech recognizer for Italian based on the principles of Stevens' model of Lexical Access in which words are stored as hierarchical arrangements of distinctive features (Stevens, K. N. (2002). "Toward a model for lexical access based on acoustic landmarks and distinctive features," J. Acoust. Soc. Am., 111(4):1872-1891). Over the past few decades, the Speech Communication Group at the Massachusetts Institute of Technology (MIT) developed a speech recognition system for English based on this approach. Italian will be the first language beyond English to be explored; the extension to another language provides the opportunity to test the hypothesis that words are represented in memory as a set of hierarchically-arranged distinctive features, and reveal which of the underlying mechanisms may have a language-independent nature. This paper also introduces a new Lexical Access corpus, the LaMIT database, created and labeled specifically for this work, that will be provided freely to the speech research community. Future developments will test the hypothesis that specific acoustic discontinuities - called landmarks - that serve as cues to features, are language independent, while other cues may be language-dependent, with powerful implications for understanding how the human brain recognizes speech.
Evaluating Automatic Speech Recognition Systems in Comparison With Human Perception Results Using Distinctive Feature Measures
Dec 13, 2016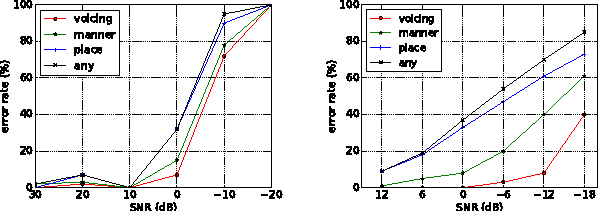
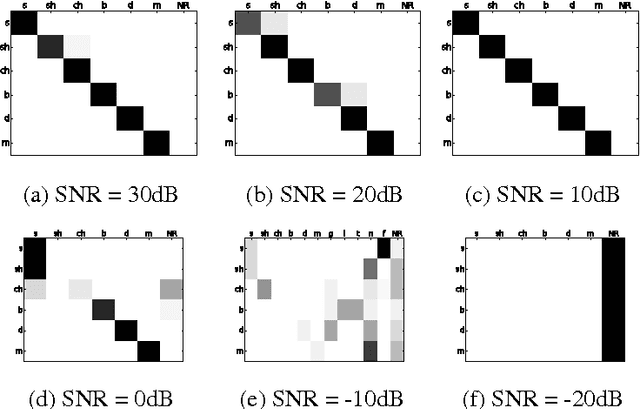
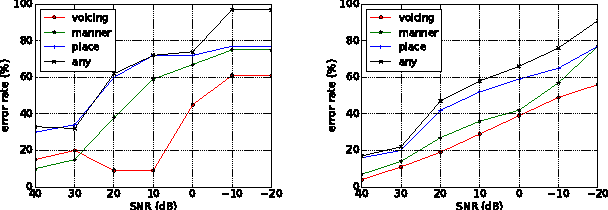
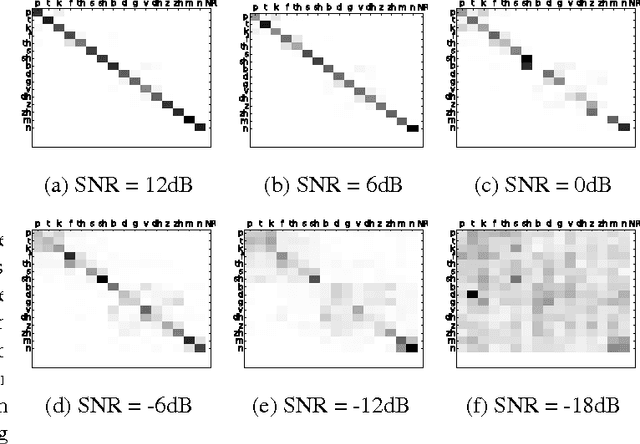
This paper describes methods for evaluating automatic speech recognition (ASR) systems in comparison with human perception results, using measures derived from linguistic distinctive features. Error patterns in terms of manner, place and voicing are presented, along with an examination of confusion matrices via a distinctive-feature-distance metric. These evaluation methods contrast with conventional performance criteria that focus on the phone or word level, and are intended to provide a more detailed profile of ASR system performance,as well as a means for direct comparison with human perception results at the sub-phonemic level.
* ICASSP 2017
Landmark-based consonant voicing detection on multilingual corpora
Nov 10, 2016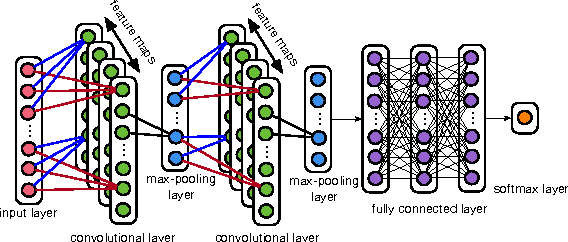
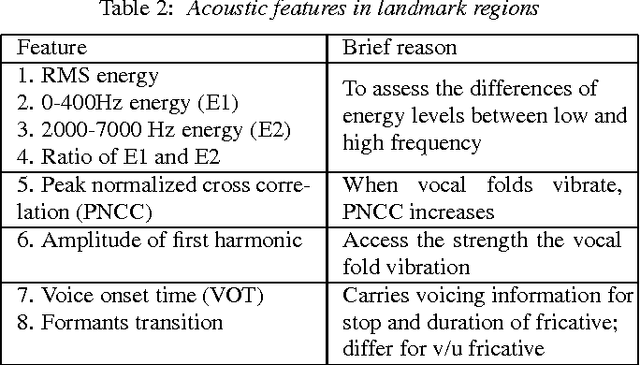
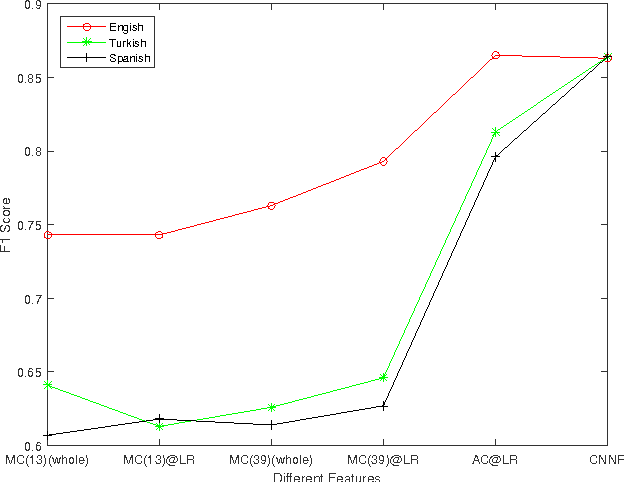
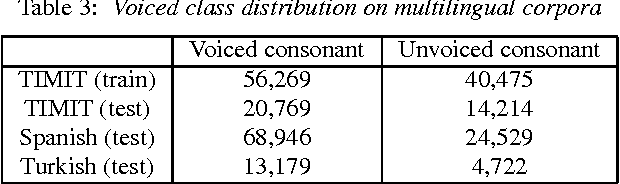
This paper tests the hypothesis that distinctive feature classifiers anchored at phonetic landmarks can be transferred cross-lingually without loss of accuracy. Three consonant voicing classifiers were developed: (1) manually selected acoustic features anchored at a phonetic landmark, (2) MFCCs (either averaged across the segment or anchored at the landmark), and(3) acoustic features computed using a convolutional neural network (CNN). All detectors are trained on English data (TIMIT),and tested on English, Turkish, and Spanish (performance measured using F1 and accuracy). Experiments demonstrate that manual features outperform all MFCC classifiers, while CNNfeatures outperform both. MFCC-based classifiers suffer an F1reduction of 16% absolute when generalized from English to other languages. Manual features suffer only a 5% F1 reduction,and CNN features actually perform better in Turkish and Span-ish than in the training language, demonstrating that features capable of representing long-term spectral dynamics (CNN and landmark-based features) are able to generalize cross-lingually with little or no loss of accuracy