 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Multimodal Deep Neural Networks to Disentangle Language from Visual Aesthetics
Oct 31, 2024



When we experience a visual stimulus as beautiful, how much of that experience derives from perceptual computations we cannot describe versus conceptual knowledge we can readily translate into natural language? Disentangling perception from language in visually-evoked affective and aesthetic experiences through behavioral paradigms or neuroimaging is often empirically intractable. Here, we circumnavigate this challenge by using linear decoding over the learned representations of unimodal vision, unimodal language, and multimodal (language-aligned) deep neural network (DNN) models to predict human beauty ratings of naturalistic images. We show that unimodal vision models (e.g. SimCLR) account for the vast majority of explainable variance in these ratings. Language-aligned vision models (e.g. SLIP) yield small gains relative to unimodal vision. Unimodal language models (e.g. GPT2) conditioned on visual embeddings to generate captions (via CLIPCap) yield no further gains. Caption embeddings alone yield less accurate predictions than image and caption embeddings combined (concatenated). Taken together, these results suggest that whatever words we may eventually find to describe our experience of beauty, the ineffable computations of feedforward perception may provide sufficient foundation for that experience.
Detecting Dataset Drift and Non-IID Sampling via k-Nearest Neighbors
May 25, 2023



We present a straightforward statistical test to detect certain violations of the assumption that the data are Independent and Identically Distributed (IID). The specific form of violation considered is common across real-world applications: whether the examples are ordered in the dataset such that almost adjacent examples tend to have more similar feature values (e.g. due to distributional drift, or attractive interactions between datapoints). Based on a k-Nearest Neighbors estimate, our approach can be used to audit any multivariate numeric data as well as other data types (image, text, audio, etc.) that can be numerically represented, perhaps with model embeddings. Compared with existing methods to detect drift or auto-correlation, our approach is both applicable to more types of data and also able to detect a wider variety of IID violations in practice. Code: https://github.com/cleanlab/cleanlab
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022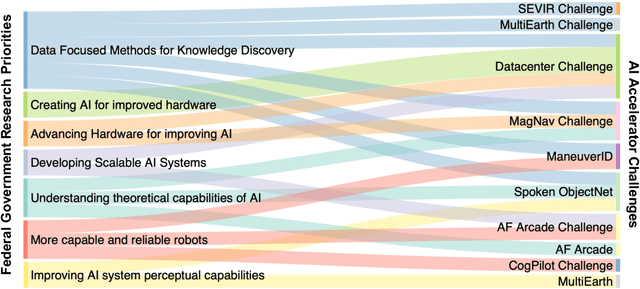

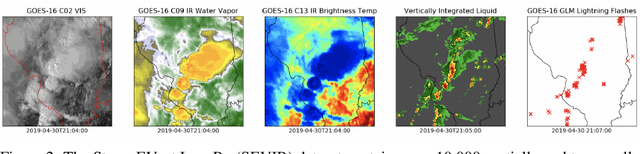
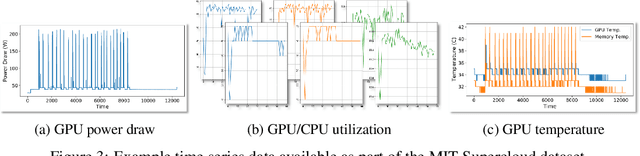
Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.