 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Enabling Technologies: A Survey
May 08, 2019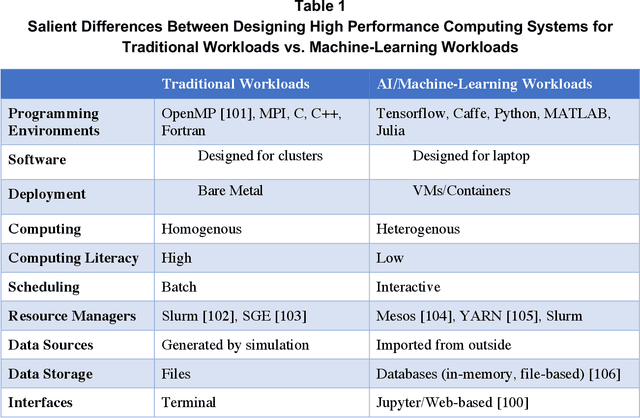
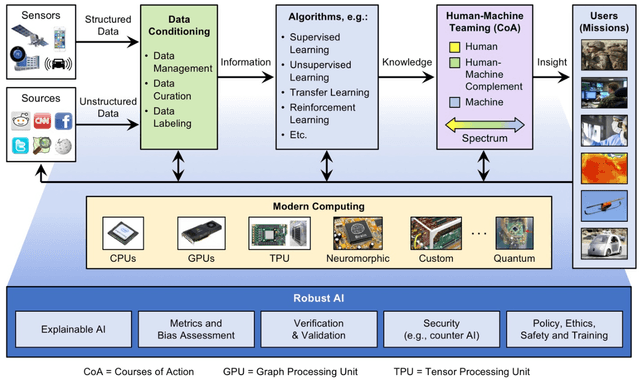

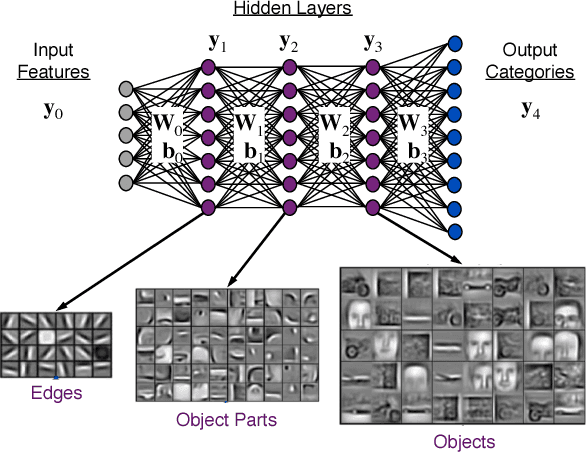
Artificial Intelligence (AI) has the opportunity to revolutionize the way the United States Department of Defense (DoD) and Intelligence Community (IC) address the challenges of evolving threats, data deluge, and rapid courses of action. Developing an end-to-end artificial intelligence system involves parallel development of different pieces that must work together in order to provide capabilities that can be used by decision makers, warfighters and analysts. These pieces include data collection, data conditioning, algorithms, computing, robust artificial intelligence, and human-machine teaming. While much of the popular press today surrounds advances in algorithms and computing, most modern AI systems leverage advances across numerous different fields. Further, while certain components may not be as visible to end-users as others, our experience has shown that each of these interrelated components play a major role in the success or failure of an AI system. This article is meant to highlight many of these technologies that are involved in an end-to-end AI system. The goal of this article is to provide readers with an overview of terminology, technical details and recent highlights from academia, industry and government. Where possible, we indicate relevant resources that can be used for further reading and understanding.
RadiX-Net: Structured Sparse Matrices for Deep Neural Networks
Apr 30, 2019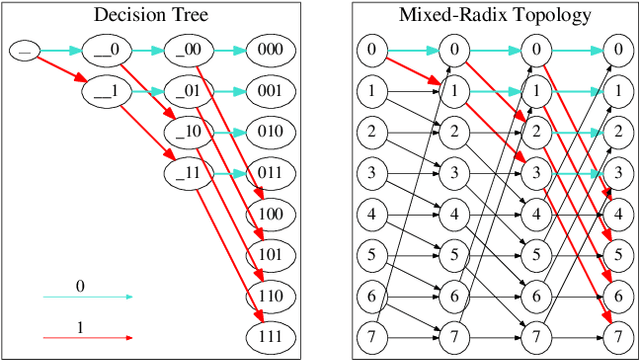
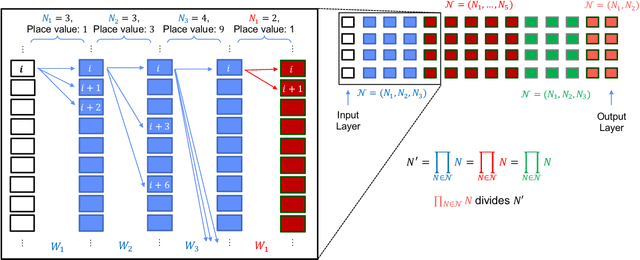
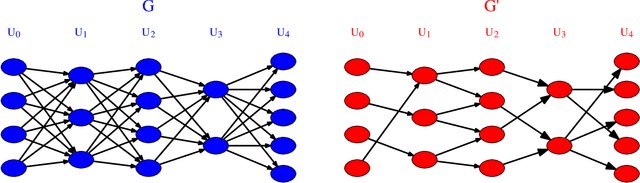
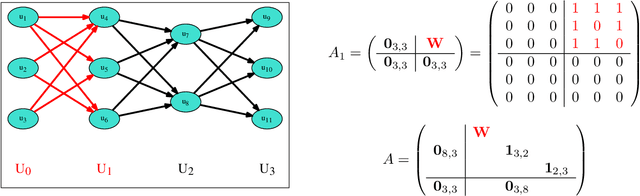
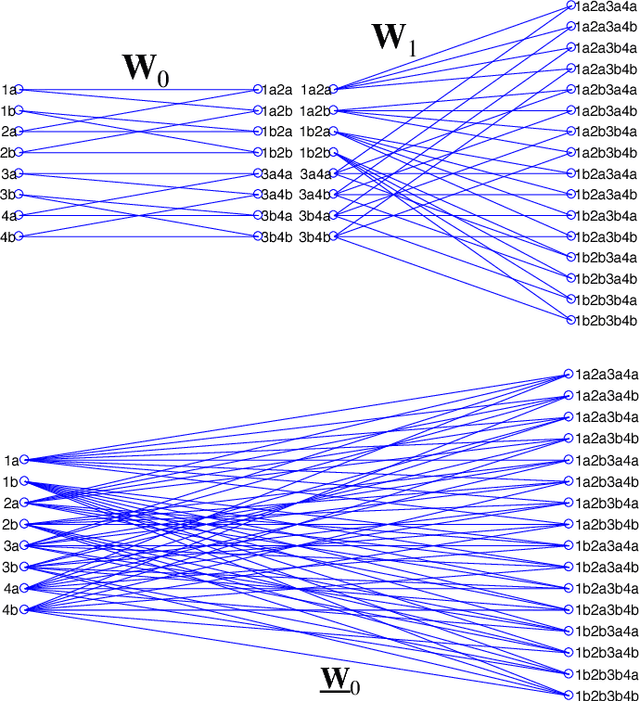
The sizes of deep neural networks (DNNs) are rapidly outgrowing the capacity of hardware to store and train them. Research over the past few decades has explored the prospect of sparsifying DNNs before, during, and after training by pruning edges from the underlying topology. The resulting neural network is known as a sparse neural network. More recent work has demonstrated the remarkable result that certain sparse DNNs can train to the same precision as dense DNNs at lower runtime and storage cost. An intriguing class of these sparse DNNs is the X-Nets, which are initialized and trained upon a sparse topology with neither reference to a parent dense DNN nor subsequent pruning. We present an algorithm that deterministically generates RadiX-Nets: sparse DNN topologies that, as a whole, are much more diverse than X-Net topologies, while preserving X-Nets' desired characteristics. We further present a functional-analytic conjecture based on the longstanding observation that sparse neural network topologies can attain the same expressive power as dense counterparts
Pruned and Structurally Sparse Neural Networks
Sep 30, 2018
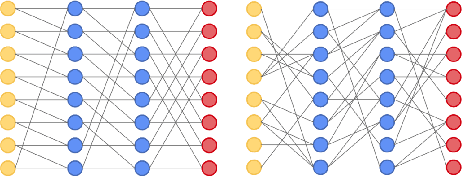
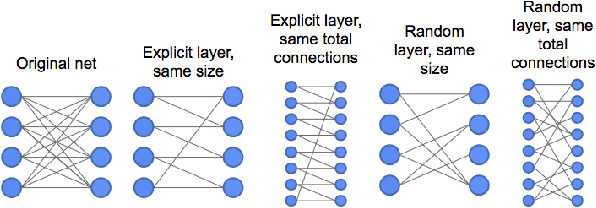
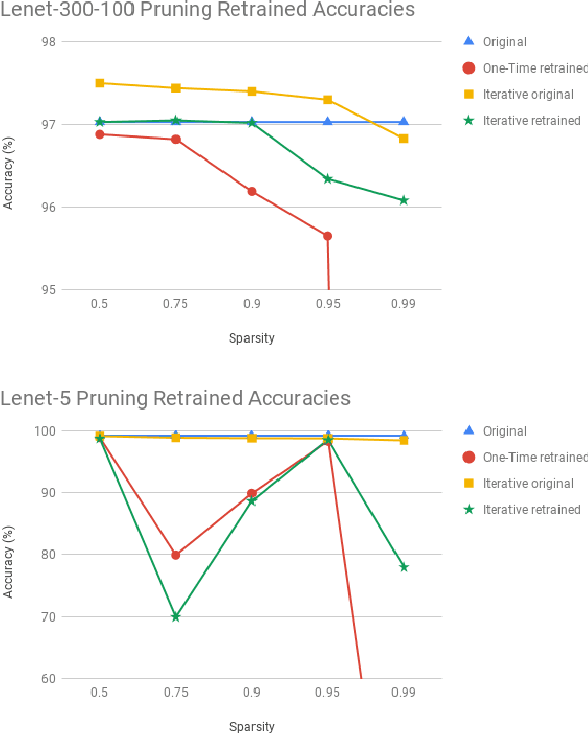
Advances in designing and training deep neural networks have led to the principle that the large and deeper a network is, the better it can perform. As a result, computational resources have become a key limiting factor in achieving better performance. One strategy to improve network capabilities while decreasing computation required is to replace dense fully-connected and convolutional layers with sparse layers. In this paper we experiment with training on sparse neural network topologies. First, we test pruning-based sparse topologies, which use a network topology obtained by initially training a dense network and then pruning low-weight connections. Second, we test RadiX-Nets, a class of sparse network structures with proven connectivity and sparsity properties. Results show that compared to dense topologies, sparse structures show promise in training potential but also can exhibit highly nonlinear convergence, which merits further study.
Uncertainty Propagation in Deep Neural Networks Using Extended Kalman Filtering
Sep 17, 2018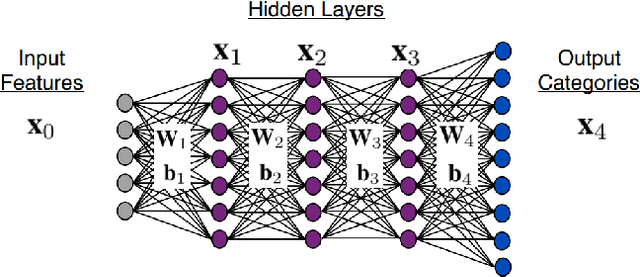
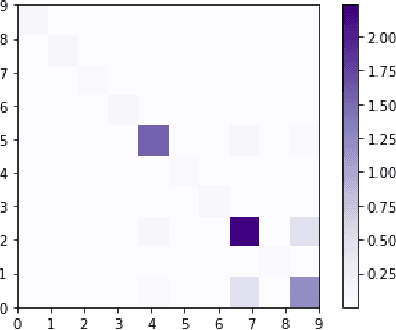
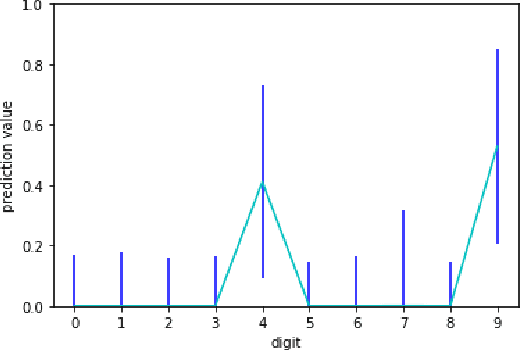
Extended Kalman Filtering (EKF) can be used to propagate and quantify input uncertainty through a Deep Neural Network (DNN) assuming mild hypotheses on the input distribution. This methodology yields results comparable to existing methods of uncertainty propagation for DNNs while lowering the computational overhead considerably. Additionally, EKF allows model error to be naturally incorporated into the output uncertainty.
Neural Network Topologies for Sparse Training
Sep 14, 2018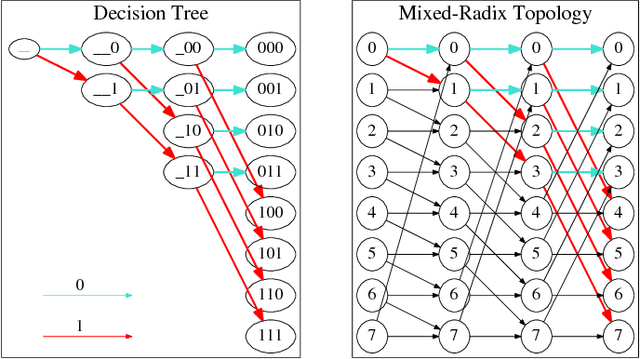
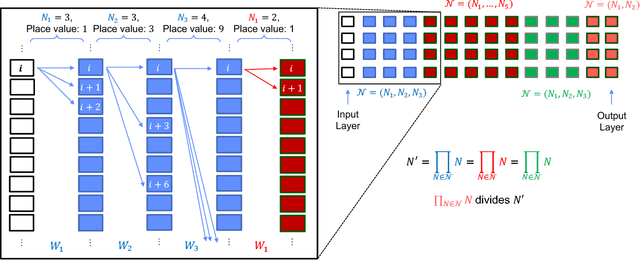
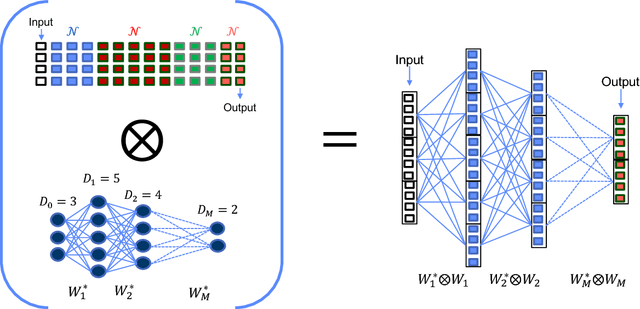

The sizes of deep neural networks (DNNs) are rapidly outgrowing the capacity of hardware to store and train them. Research over the past few decades has explored the prospect of sparsifying DNNs before, during, and after training by pruning edges from the underlying topology. The resulting neural network is known as a sparse neural network. More recent work has demonstrated the remarkable result that certain sparse DNNs can train to the same precision as dense DNNs at lower runtime and storage cost. An intriguing class of these sparse DNNs is the X-Nets, which are initialized and trained upon a sparse topology with neither reference to a parent dense DNN nor subsequent pruning. We present an algorithm that deterministically generates sparse DNN topologies that, as a whole, are much more diverse than X-Net topologies, while preserving X-Nets' desired characteristics.
Sparse Deep Neural Network Exact Solutions
Jul 06, 2018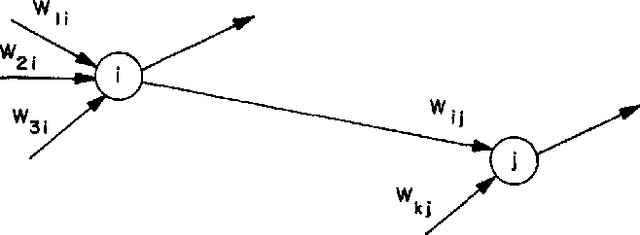
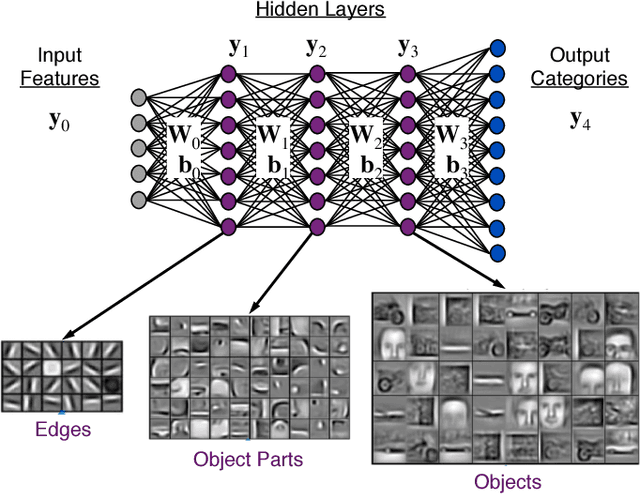
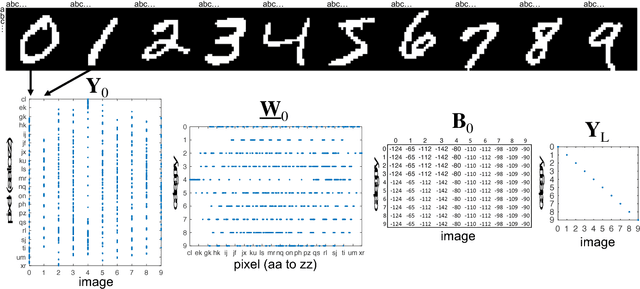
Deep neural networks (DNNs) have emerged as key enablers of machine learning. Applying larger DNNs to more diverse applications is an important challenge. The computations performed during DNN training and inference are dominated by operations on the weight matrices describing the DNN. As DNNs incorporate more layers and more neurons per layers, these weight matrices may be required to be sparse because of memory limitations. Sparse DNNs are one possible approach, but the underlying theory is in the early stages of development and presents a number of challenges, including determining the accuracy of inference and selecting nonzero weights for training. Associative array algebra has been developed by the big data community to combine and extend database, matrix, and graph/network concepts for use in large, sparse data problems. Applying this mathematics to DNNs simplifies the formulation of DNN mathematics and reveals that DNNs are linear over oscillating semirings. This work uses associative array DNNs to construct exact solutions and corresponding perturbation models to the rectified linear unit (ReLU) DNN equations that can be used to construct test vectors for sparse DNN implementations over various precisions. These solutions can be used for DNN verification, theoretical explorations of DNN properties, and a starting point for the challenge of sparse training.
Enabling Massive Deep Neural Networks with the GraphBLAS
Aug 09, 2017
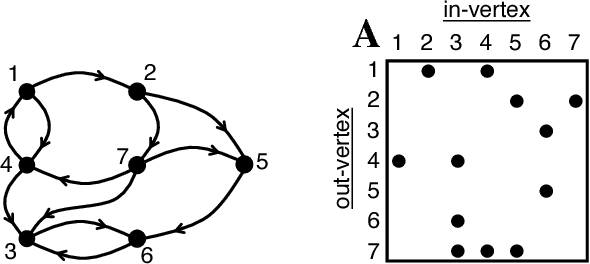

Deep Neural Networks (DNNs) have emerged as a core tool for machine learning. The computations performed during DNN training and inference are dominated by operations on the weight matrices describing the DNN. As DNNs incorporate more stages and more nodes per stage, these weight matrices may be required to be sparse because of memory limitations. The GraphBLAS.org math library standard was developed to provide high performance manipulation of sparse weight matrices and input/output vectors. For sufficiently sparse matrices, a sparse matrix library requires significantly less memory than the corresponding dense matrix implementation. This paper provides a brief description of the mathematics underlying the GraphBLAS. In addition, the equations of a typical DNN are rewritten in a form designed to use the GraphBLAS. An implementation of the DNN is given using a preliminary GraphBLAS C library. The performance of the GraphBLAS implementation is measured relative to a standard dense linear algebra library implementation. For various sizes of DNN weight matrices, it is shown that the GraphBLAS sparse implementation outperforms a BLAS dense implementation as the weight matrix becomes sparser.
Non-Negative Matrix Factorization Test Cases
Dec 30, 2016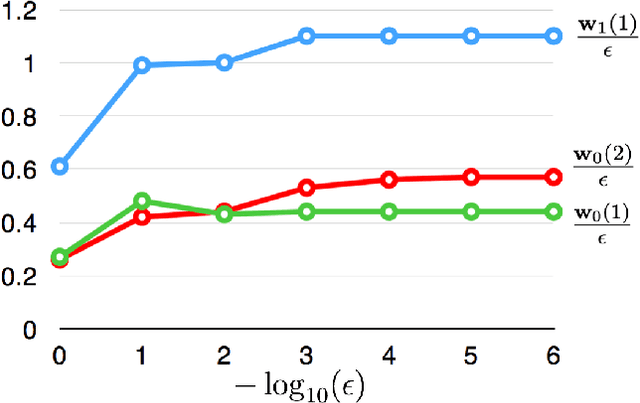
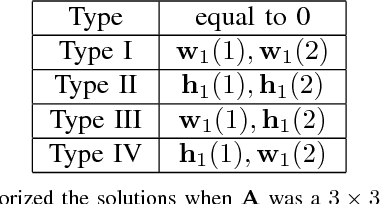
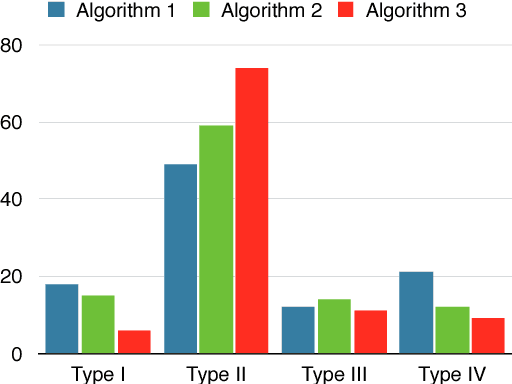
Non-negative matrix factorization (NMF) is a prob- lem with many applications, ranging from facial recognition to document clustering. However, due to the variety of algorithms that solve NMF, the randomness involved in these algorithms, and the somewhat subjective nature of the problem, there is no clear "correct answer" to any particular NMF problem, and as a result, it can be hard to test new algorithms. This paper suggests some test cases for NMF algorithms derived from matrices with enumerable exact non-negative factorizations and perturbations of these matrices. Three algorithms using widely divergent approaches to NMF all give similar solutions over these test cases, suggesting that these test cases could be used as test cases for implementations of these existing NMF algorithms as well as potentially new NMF algorithms. This paper also describes how the proposed test cases could be used in practice.
Large Enforced Sparse Non-Negative Matrix Factorization
Oct 18, 2015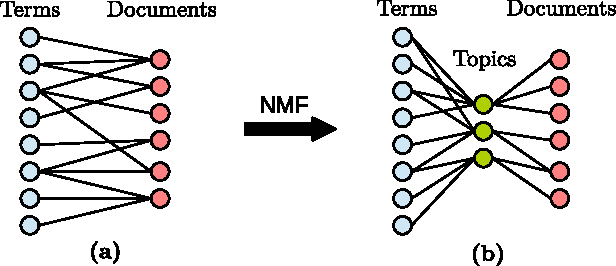
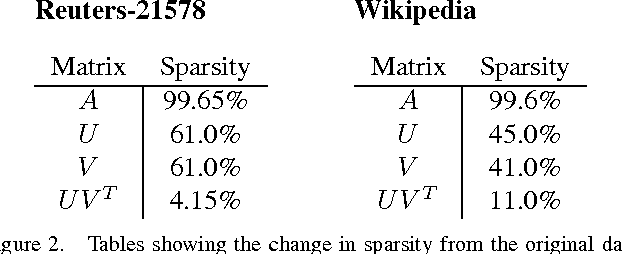
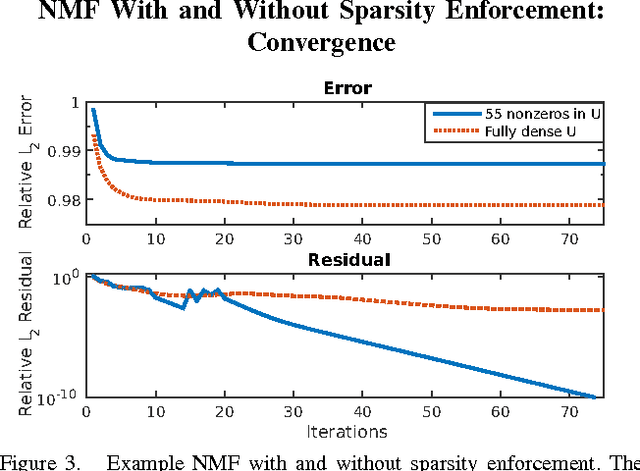
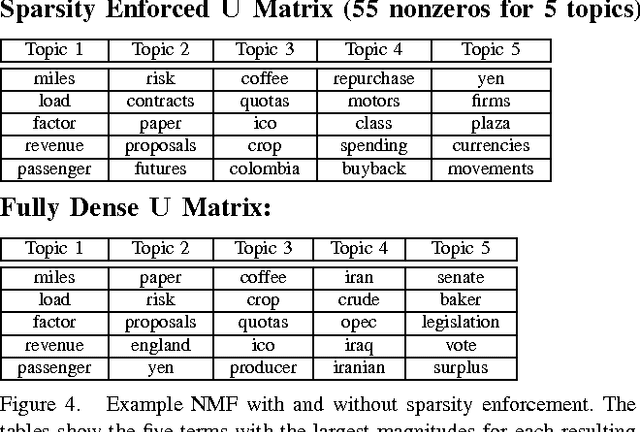
Non-negative matrix factorization (NMF) is a common method for generating topic models from text data. NMF is widely accepted for producing good results despite its relative simplicity of implementation and ease of computation. One challenge with applying NMF to large datasets is that intermediate matrix products often become dense, stressing the memory and compute elements of a system. In this article, we investigate a simple but powerful modification of a common NMF algorithm that enforces the generation of sparse intermediate and output matrices. This method enables the application of NMF to large datasets through improved memory and compute performance. Further, we demonstrate empirically that this method of enforcing sparsity in the NMF either preserves or improves both the accuracy of the resulting topic model and the convergence rate of the underlying algorithm.