 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Potential of BERTopic for Multilingual Fake News Analysis -- Use Case: Covid-19
Jul 11, 2024



Topic modeling is frequently being used for analysing large text corpora such as news articles or social media data. BERTopic, consisting of sentence embedding, dimension reduction, clustering, and topic extraction, is the newest and currently the SOTA topic modeling method. However, current topic modeling methods have room for improvement because, as unsupervised methods, they require careful tuning and selection of hyperparameters, e.g., for dimension reduction and clustering. This paper aims to analyse the technical application of BERTopic in practice. For this purpose, it compares and selects different methods and hyperparameters for each stage of BERTopic through density based clustering validation and six different topic coherence measures. Moreover, it also aims to analyse the results of topic modeling on real world data as a use case. For this purpose, the German fake news dataset (GermanFakeNCovid) on Covid-19 was created by us and in order to experiment with topic modeling in a multilingual (English and German) setting combined with the FakeCovid dataset. With the final results, we were able to determine thematic similarities between the United States and Germany. Whereas, distinguishing the topics of fake news from India proved to be more challenging.
Fraunhofer SIT at CheckThat! 2023: Tackling Classification Uncertainty Using Model Souping on the Example of Check-Worthiness Classification
Jul 03, 2023



This paper describes the second-placed approach developed by the Fraunhofer SIT team in the CLEF-2023 CheckThat! lab Task 1B for English. Given a text snippet from a political debate, the aim of this task is to determine whether it should be assessed for check-worthiness. Detecting check-worthy statements aims to facilitate manual fact-checking efforts by prioritizing the claims that fact-checkers should consider first. It can also be considered as primary step of a fact-checking system. Our best-performing method took advantage of an ensemble classification scheme centered on Model Souping. When applied to the English data set, our submitted model achieved an overall F1 score of 0.878 and was ranked as the second-best model in the competition.
* 9 pages
Similarity Detection Pipeline for Crawling a Topic Related Fake News Corpus
Sep 28, 2020
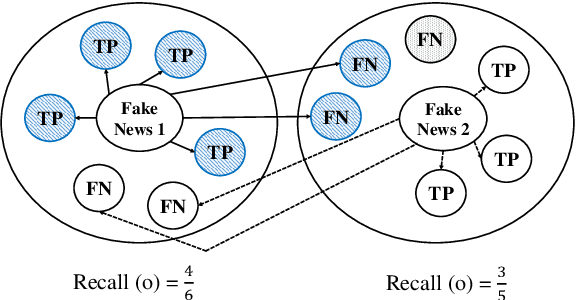
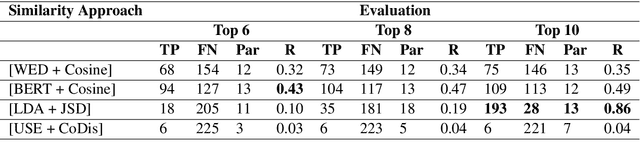
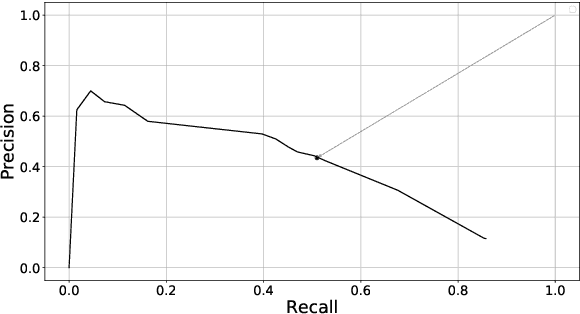
Fake news detection is a challenging task aiming to reduce human time and effort to check the truthfulness of news. Automated approaches to combat fake news, however, are limited by the lack of labeled benchmark datasets, especially in languages other than English. Moreover, many publicly available corpora have specific limitations that make them difficult to use. To address this problem, our contribution is threefold. First, we propose a new, publicly available German topic related corpus for fake news detection. To the best of our knowledge, this is the first corpus of its kind. In this regard, we developed a pipeline for crawling similar news articles. As our third contribution, we conduct different learning experiments to detect fake news. The best performance was achieved using sentence level embeddings from SBERT in combination with a Bi-LSTM (k=0.88).